

TL;DR
- LLMs and different GenAI fashions can reproduce vital chunks of coaching information.
- Specific prompts appear to “unlock” coaching information.
- We have many present and future copyright challenges: coaching could not infringe copyright, however authorized doesn’t imply authentic—we contemplate the analogy of MegaFace the place surveillance fashions have been educated on images of minors, for instance, with out knowledgeable consent.
- Copyright was meant to incentivize cultural manufacturing: within the period of generative AI, copyright gained’t be sufficient.
In Borges’ fable Pierre Menard, Author of The Quixote, the eponymous Monsieur Menard plans to take a seat down and write a portion of Cervantes’ Don Quixote. Not to transcribe, however re-write the epic novel phrase for phrase:
His purpose was by no means the mechanical transcription of the unique; he had no intention of copying it. His admirable ambition was to provide a variety of pages which coincided—phrase for phrase and line by line—with these of Miguel de Cervantes.
Learn sooner. Dig deeper. See farther.

{kind=link}
He first tried to take action by changing into Cervantes, studying Spanish, and forgetting all of the historical past since Cervantes wrote Don Quixote, amongst different issues, however then determined it could make extra sense to (re)write the textual content as Menard himself. The narrator tells us that, “the Cervantes text and the Menard text are verbally identical, but the second is almost infinitely richer.” Perhaps that is an inversion of the power of Generative AI fashions (LLMs, text-to-image, and extra) to breed swathes of their coaching information with out these chunks being explicitly saved within the mannequin and its weights: the output is verbally similar to the unique however reproduced probabilistically with none of the human blood, sweat, tears, and life expertise that goes into the creation of human writing and cultural manufacturing.
Generative AI Has a Plagiarism Problem
ChatGPT, for instance, doesn’t memorize its coaching information, per se. As Mike Loukides and Tim O’Reilly astutely level out:
A mannequin prompted to jot down like Shakespeare could begin with the phrase “To,” which makes it barely extra possible that it’ll observe that with “be,” which makes it barely extra possible that the subsequent phrase can be “or”—and so forth.
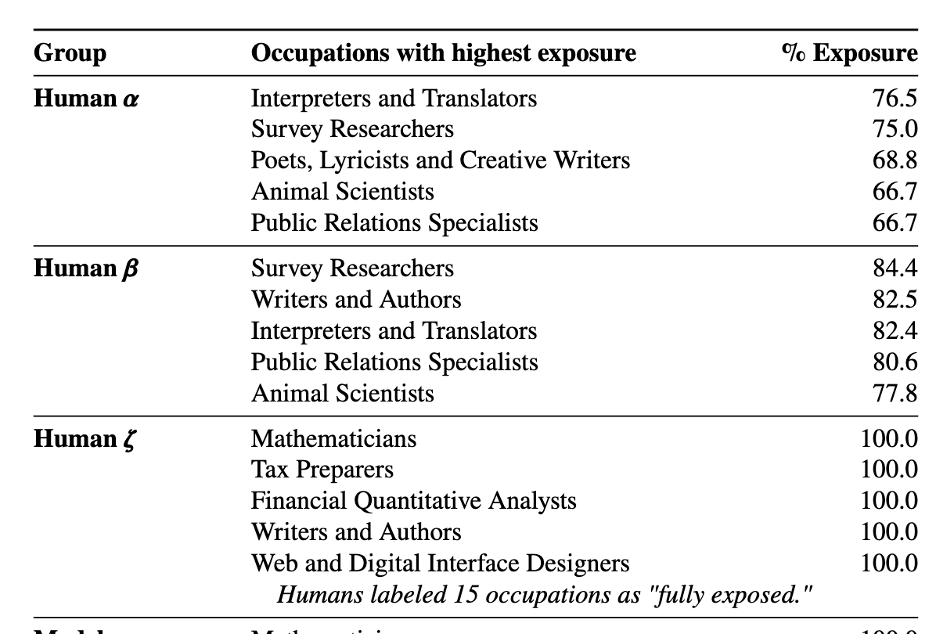
So then, because it seems, next-word prediction (and all of the sauce on prime) can reproduce chunks of coaching information. This is the premise of The New York Times lawsuit towards OpenAI. I’ve been capable of persuade ChatGPT to present me massive chunks of novels which can be within the public area, equivalent to these on Project Gutenberg, together with Pride and Prejudice. Researchers are discovering increasingly methods to extract coaching information from ChatGPT and different fashions. As far as different kinds of basis fashions go, latest work by Gary Marcus and Reid Southern has proven that you should utilize Midjourney (text-to-image) to generate photographs from Star Wars, The Simpsons, Super Mario Brothers, and plenty of different movies. This appears to be rising as a characteristic, not a bug, and hopefully it’s apparent to you why they known as their IEEE opinion piece Generative AI Has a Visual Plagiarism Problem. (It’s ironic that, on this article, we didn’t reproduce the pictures from Marcus’ article as a result of we didn’t need to danger violating copyright—a danger that Midjourney apparently ignores and maybe a danger that even IEEE and the authors took on!) And the area is shifting shortly: SORA, OpenAI’s text-to-video mannequin, is but to be launched and has already taken the world by storm.
Compression, Transformation, Hallucination, and Generation
Training information isn’t saved within the mannequin per se, however massive chunks of it are reconstructable given the proper key (“prompt”).
There are plenty of conversations about whether or not or not LLMs (and machine studying, extra usually) are types of compression or not. In some ways, they’re, however additionally they have generative capabilities that we don’t typically affiliate with compression.
Ted Chiang wrote a considerate piece for the New Yorker known as ChatGPT is a Blurry JPEG of the Web that opens with the analogy of a photocopier making a slight error because of the approach it compresses the digital picture. It’s an attention-grabbing piece that I commend to you, however one which makes me uncomfortable. To me, the analogy breaks down earlier than it begins: firstly, LLMs don’t merely blur, however carry out extremely non-linear transformations, which suggests you possibly can’t simply squint and get a way of the unique; secondly, for the photocopier, the error is a bug, whereas, for LLMs, all errors are options. Let me clarify. Or, reasonably, let Andrej Karpathy clarify:
I at all times wrestle a bit [when] I’m requested in regards to the “hallucination problem” in LLMs. Because, in some sense, hallucination is all LLMs do. They are dream machines.
We direct their goals with prompts. The prompts begin the dream, and primarily based on the LLM’s hazy recollection of its coaching paperwork, more often than not the consequence goes someplace helpful.
It’s solely when the goals go into deemed factually incorrect territory that we label it a “hallucination.” It seems to be like a bug, but it surely’s simply the LLM doing what it at all times does.
At the opposite finish of the acute contemplate a search engine. It takes the immediate and simply returns one of the related “training documents” it has in its database, verbatim. You may say that this search engine has a “creativity problem”—it’s going to by no means reply with one thing new. An LLM is 100% dreaming and has the hallucination downside. A search engine is 0% dreaming and has the creativity downside.
As a aspect notice, constructing merchandise that strike balances between Search and LLMs can be a extremely productive space and corporations equivalent to Perplexity AI are additionally doing attention-grabbing work there.
It’s attention-grabbing to me that, whereas LLMs are continuously “hallucinating,”1 they will additionally reproduce massive chunks of coaching information, not simply go “someplace useful,” as Karpathy put it (summarization, for instance). So, is the coaching information “stored” within the mannequin? Well, no, not fairly. But additionally… Yes?
Let’s say I tear up a portray right into a thousand items and put them again collectively in a mosaic: is the unique portray saved within the mosaic? No, except you understand how to rearrange the items to get the unique. You want a key. And, because it seems, there occur to make certain prompts that act as keys that unlock coaching information (for insiders, chances are you’ll acknowledge this as extraction assaults, a type of adversarial machine studying).
This additionally has implications for whether or not Generative AI can create something notably novel: I’ve excessive hopes that it may well however I believe that’s nonetheless but to be demonstrated. There are additionally vital and critical issues about what occurs when we frequently prepare fashions on the outputs of different fashions.
Implications for Copyright and Legitimacy, Big Tech and Informed Consent
Copyright isn’t the proper paradigm to be fascinated about right here; authorized doesn’t imply authentic; surveillance fashions educated on images of your youngsters.
Now I don’t suppose this has implications for whether or not LLMs are infringing copyright and whether or not ChatGPT is infringing that of The New York Times, Sarah Silverman, George RR Martin, or any of us whose writing has been scraped for coaching information. But I additionally don’t suppose copyright is essentially the very best paradigm for considering by way of whether or not such coaching and deployment ought to be authorized or not. Firstly, copyright was created in response to the affordances of mechanical replica and we now stay in an age of digital replica, distribution, and era. It’s additionally about what sort of society we need to stay in collectively: copyright itself was initially created to incentivize sure modes of cultural manufacturing.
Early predecessors of recent copyright legislation, equivalent to the Statute of Anne (1710) in England, had been created to incentivize writers to jot down and to incentivize extra cultural manufacturing. Up till this level, the Crown had granted unique rights to print sure works to the Stationers’ Company, successfully making a monopoly, and there weren’t monetary incentives to jot down. So, even when OpenAI and their frenemies aren’t breaching copyright legislation, what sort of cultural manufacturing are we and aren’t we incentivizing by not zooming out and as lots of the externalities right here as doable?
Remember the context. Actors and writers had been lately hanging whereas Netflix had an AI product supervisor job itemizing with a base wage starting from $300K to $900K USD.2 Also, notice that we already stay in a society the place many creatives find yourself in promoting and advertising and marketing. These could also be among the first jobs on the chopping block on account of ChatGPT and pals, notably if macroeconomic strain retains leaning on us all. And that’s in keeping with OpenAI!
Back to copyright: I don’t know sufficient about copyright legislation but it surely appears to me as if LLMs are “transformative” sufficient to have a good use protection within the US. Also, coaching fashions doesn’t appear to me to infringe copyright as a result of it doesn’t but produce output! But maybe it ought to infringe one thing: even when the gathering of information is authorized (which, statistically, it gained’t fully be for any web-scale corpus), it doesn’t imply it’s authentic, and it positively doesn’t imply there was knowledgeable consent.
To see this, let’s contemplate one other instance, that of MegaFace. In “How Photos of Your Kids Are Powering Surveillance Technology,” The New York Times reported that
One day in 2005, a mom in Evanston, Ill., joined Flickr. She uploaded some footage of her youngsters, Chloe and Jasper. Then she roughly forgot her account existed…
Years later, their faces are in a database that’s used to check and prepare among the most subtle [facial recognition] synthetic intelligence methods on this planet.
What’s extra,
Containing the likenesses of practically 700,000 people, it has been downloaded by dozens of corporations to coach a brand new era of face-identification algorithms, used to trace protesters, surveil terrorists, spot downside gamblers and spy on the general public at massive.
Even within the instances the place that is authorized (which appear to be the overwhelming majority of instances), it’d be powerful to make an argument that it’s authentic and even more durable to assert that there was knowledgeable consent. I additionally presume most individuals would contemplate it ethically doubtful. I elevate this instance for a number of causes:
- Just as a result of one thing is authorized, doesn’t imply that we wish it to be going ahead.
- This is illustrative of a completely new paradigm, enabled by expertise, by which huge quantities of information will be collected, processed, and used to energy algorithms, fashions, and merchandise; the identical paradigm beneath which GenAI fashions are working.
- It’s a paradigm that’s baked into how a whole lot of Big Tech operates and we appear to simply accept it in lots of kinds now: however should you’d constructed LLMs 10, not to mention 20, years in the past by scraping web-scale information, this may seemingly be a really completely different dialog.
I ought to in all probability additionally outline what I imply by “legitimate/illegitimate” or no less than level to a definition. When the Dutch East India Company “purchased” Manhattan from the Lenape individuals, Peter Minuit, who orchestrated the “purchase,” supposedly paid $24 value of trinkets. That wasn’t unlawful. Was it authentic? It depends upon your POV: not from mine. The Lenape didn’t have a conception of land possession, simply as we don’t but have a critical conception of information possession. This supposed “purchase” of Manhattan has resonances with uninformed consent. It’s additionally related as Big Tech is understood for its extractive and colonialist practices.
This isn’t about copyright, The New York Times, or OpenAI
It’s about what sort of society you need to stay in.
I believe it’s fully doable that The New York Times and OpenAI will settle out of courtroom: OpenAI has robust incentives to take action and the Times seemingly additionally has short-term incentives to. However, the Times has additionally confirmed itself adept at enjoying the lengthy sport. Don’t fall into the lure of considering that is merely in regards to the particular case at hand. To zoom out once more, we stay in a society the place mainstream journalism has been carved out and gutted by the web, search, and social media. The New York Times is likely one of the final critical publications standing they usually’ve labored extremely onerous and cleverly of their “digital transformation” for the reason that introduction of the web.3
Platforms equivalent to Google have inserted themselves as middlemen between producers and customers in a fashion that has killed the enterprise fashions of lots of the content material producers. They’re additionally disingenuous about what they’re doing: when the Australian Government was considering of creating Google pay information retailers that it linked to in Search, Google’s response was:
Now bear in mind, we don’t present full information articles, we simply present you the place you possibly can go and make it easier to to get there. Paying for hyperlinks breaks the best way search engines like google work, and it undermines how the online works, too. Let me attempt to say it one other approach. Imagine your buddy asks for a espresso store suggestion. So you inform them about a couple of close by to allow them to select one and go get a espresso. But then you definately get a invoice to pay all of the espresso retailers, merely since you talked about a couple of. When you place a worth on linking to sure info, you break the best way search engines like google work, and also you not have a free and open internet. We’re not towards a brand new legislation, however we’d like it to be a good one. Google has another resolution that helps journalism. It’s known as Google News Showcase.
Let me be clear: Google has performed unimaginable work in “organizing the world’s information,” however right here they’re disingenuous in evaluating themselves to a buddy providing recommendation on espresso retailers: pals don’t are inclined to have international information, AI, and infrastructural pipelines, nor are they business-predicated on surveillance capitalism.
Copyright apart, the power of Generative AI to displace creatives is an actual menace and I’m asking an actual query: can we need to stay in a society the place there aren’t many incentives for people to jot down, paint, and make music? Borges could not write right this moment, given present incentives. If you don’t notably care about Borges, maybe you care about Philip Ok. Dick, Christopher Nolan, Salman Rushdie, or the Magic Realists, who had been all influenced by his work.
Beyond all of the human features of cultural manufacturing, don’t we additionally nonetheless need to dream? Or can we additionally need to outsource that and have LLMs do all of the dreaming for us?
Footnotes
- I’m placing this in citation marks as I’m nonetheless not fully comfy with the implications of anthropomorphizing LLMs on this method.
- My intention isn’t to recommend that Netflix is all dangerous. Far from it, actually: Netflix has additionally been massively highly effective in offering a large distribution channel to creatives throughout the globe. It’s difficult.
- Also notice that the end result of this case may have vital influence for the way forward for OSS and open weight basis fashions, one thing I hope to jot down about in future.
This essay first appeared on Hugo Bowne-Anderson’s weblog. Thank you to Goku Mohandas for offering early suggestions.