
{kind=link}


|
Deep studying (DL) fashions have been growing in measurement and complexity over the previous couple of years, pushing the time to coach from days to weeks. Coaching massive language fashions the scale of GPT-3 can take months, resulting in an exponential progress in coaching value. To scale back mannequin coaching occasions and allow machine studying (ML) practitioners to iterate quick, AWS has been innovating throughout chips, servers, and knowledge heart connectivity.
At AWS re:Invent 2021, we introduced the preview of Amazon EC2 Trn1 situations powered by AWS Trainium chips. AWS Trainium is optimized for high-performance deep studying coaching and is the second-generation ML chip constructed by AWS, following AWS Inferentia.
Right now, I’m excited to announce that Amazon EC2 Trn1 situations at the moment are typically accessible! These situations are well-suited for large-scale distributed coaching of complicated DL fashions throughout a broad set of purposes, corresponding to pure language processing, picture recognition, and extra.
In comparison with Amazon EC2 P4d situations, Trn1 situations ship 1.4x the teraFLOPS for BF16 knowledge sorts, 2.5x extra teraFLOPS for TF32 knowledge sorts, 5x the teraFLOPS for FP32 knowledge sorts, 4x inter-node community bandwidth, and as much as 50 % cost-to-train financial savings. Trn1 situations will be deployed in EC2 UltraClusters that function highly effective supercomputers to quickly prepare complicated deep studying fashions. I’ll share extra particulars on EC2 UltraClusters later on this weblog submit.
New Trn1 Occasion Highlights
Trn1 situations can be found immediately in two sizes and are powered by as much as 16 AWS Trainium chips with 128 vCPUs. They supply high-performance networking and storage to help environment friendly knowledge and mannequin parallelism, common methods for distributed coaching.
Trn1 situations provide as much as 512 GB of high-bandwidth reminiscence, ship as much as 3.4 petaFLOPS of TF32/FP16/BF16 compute energy, and have an ultra-high-speed NeuronLink interconnect between chips. NeuronLink helps keep away from communication bottlenecks when scaling workloads throughout a number of Trainium chips.
Trn1 situations are additionally the primary EC2 situations to allow as much as 800 Gbps of Elastic Material Adapter (EFA) community bandwidth for high-throughput community communication. This second era EFA delivers decrease latency and as much as 2x extra community bandwidth in comparison with the earlier era. Trn1 situations additionally include as much as 8 TB of native NVMe SSD storage for ultra-fast entry to massive datasets.
The next desk lists the sizes and specs of Trn1 situations intimately.
| Occasion Title |
vCPUs | AWS Trainium Chips | Accelerator Reminiscence | NeuronLink | Occasion Reminiscence | Occasion Networking | Native Occasion Storage |
| trn1.2xlarge | 8 | 1 | 32 GB | N/A | 32 GB | As much as 12.5 Gbps | 1x 500 GB NVMe |
| trn1.32xlarge | 128 | 16 | 512 GB | Supported | 512 GB | 800 Gbps | 4x 2 TB NVMe |
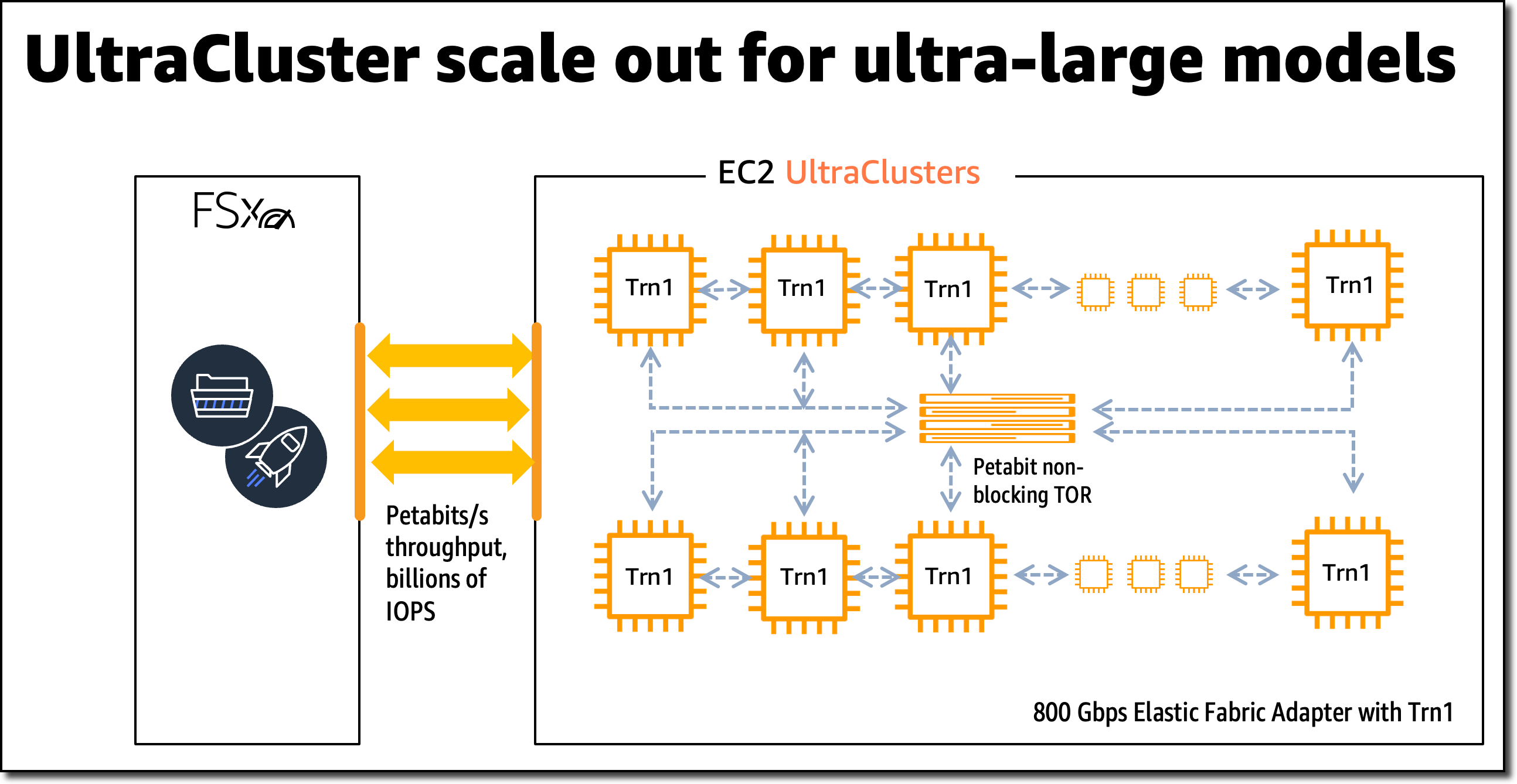
Trn1 EC2 UltraClusters
For big-scale mannequin coaching, Trn1 situations combine with Amazon FSx for Lustre high-performance storage and are deployed in EC2 UltraClusters. EC2 UltraClusters are hyperscale clusters interconnected with a non-blocking petabit-scale community. This provides you on-demand entry to a supercomputer to chop mannequin coaching time for giant and complicated fashions from months to weeks and even days.
AWS Trainium Innovation
AWS Trainium chips embody specific scalar, vector, and tensor engines which are purpose-built for deep studying algorithms. This ensures greater chip utilization as in comparison with different architectures, leading to greater efficiency.
Here’s a brief abstract of further {hardware} improvements:
- Information Varieties: AWS Trainium helps a variety of knowledge sorts, together with FP32, TF32, BF16, FP16, and UINT8, so you’ll be able to select essentially the most appropriate knowledge kind on your workloads. It additionally helps a brand new, configurable FP8 (cFP8) knowledge kind, which is particularly related for giant fashions as a result of it reduces the reminiscence footprint and I/O necessities of the mannequin.
- {Hardware}-Optimized Stochastic Rounding: Stochastic rounding achieves near FP32-level accuracy with quicker BF16-level efficiency once you allow auto-casting from FP32 to BF16 knowledge sorts. Stochastic rounding is a distinct approach of rounding floating-point numbers, which is extra appropriate for machine studying workloads versus the generally used Spherical Nearest Even rounding. By setting the setting variable
NEURON_RT_STOCHASTIC_ROUNDING_EN=1to make use of stochastic rounding, you’ll be able to prepare a mannequin as much as 30 % quicker. - Customized Operators, Dynamic Tensor Shapes: AWS Trainium additionally helps customized operators written in C++ and dynamic tensor shapes. Dynamic tensor shapes are key for fashions with unknown enter tensor sizes, corresponding to fashions processing textual content.
AWS Trainium shares the identical AWS Neuron SDK as AWS Inferentia, making it straightforward for everybody who’s already utilizing AWS Inferentia to get began with AWS Trainium.
For mannequin coaching, the Neuron SDK consists of a compiler, framework extensions, a runtime library, and developer instruments. The Neuron plugin natively integrates with common ML frameworks, corresponding to PyTorch and TensorFlow.
The AWS Neuron SDK helps just-in-time (JIT) compilation, along with ahead-of-time (AOT) compilation, to hurry up mannequin compilation, and Keen Debug Mode, for a step-by-step execution.
To compile and run your mannequin on AWS Trainium, you could change just a few traces of code in your coaching script. You don’t must tweak your mannequin or take into consideration knowledge kind conversion.
Get Began with Trn1 Situations
On this instance, I prepare a PyTorch mannequin on an EC2 Trn1 occasion utilizing the accessible PyTorch Neuron packages. PyTorch Neuron is predicated on the PyTorch XLA software program package deal and allows conversion of PyTorch operations to AWS Trainium directions.
Every AWS Trainium chip contains two NeuronCore accelerators, that are the primary neural community compute items. With just a few modifications to your coaching code, you’ll be able to prepare your PyTorch mannequin on AWS Trainium NeuronCores.
SSH into the Trn1 occasion and activate a Python digital setting that features the PyTorch Neuron packages. In case you’re utilizing a Neuron-provided AMI, you’ll be able to activate the preinstalled setting by operating the next command:
supply aws_neuron_venv_pytorch_p36/bin/activateEarlier than you’ll be able to run your coaching script, you could make a couple of modifications. On Trn1 situations, the default XLA system must be mapped to a NeuronCore.
Let’s begin by including the PyTorch XLA imports to your coaching script:
import torch, torch_xla
import torch_xla.core.xla_model as xmThen, place your mannequin and tensors onto an XLA system:
mannequin.to(xm.xla_device())
tensor.to(xm.xla_device())When the mannequin is moved to the XLA system (NeuronCore), subsequent operations on the mannequin are recorded for later execution. That is XLA’s lazy execution which is completely different from PyTorch’s keen execution. Throughout the coaching loop, it’s important to mark the graph to be optimized and run on the XLA system utilizing xm.mark_step(). With out this mark, XLA can’t decide the place the graph ends.
...
for knowledge, goal in train_loader:
output = mannequin(knowledge)
loss = loss_fn(output, goal)
loss.backward()
optimizer.step()
xm.mark_step()
...Now you can run your coaching script utilizing torchrun <my_training_script>.py.
When operating the coaching script, you’ll be able to configure the variety of NeuronCores to make use of for coaching by utilizing torchrun –nproc_per_node.
For instance, to run a multi-worker knowledge parallel mannequin coaching on all 32 NeuronCores in a single trn1.32xlarge occasion, run torchrun --nproc_per_node=32 <my_training_script>.py.
Information parallel is a method for distributed coaching that means that you can replicate your script throughout a number of staff, with every employee processing a portion of the coaching dataset. The employees then share their outcome with one another.
For extra particulars on supported ML frameworks, mannequin sorts, and easy methods to put together your mannequin coaching script for large-scale distributed coaching throughout trn1.32xlarge situations, take a look on the AWS Neuron SDK documentation.
Profiling Instruments
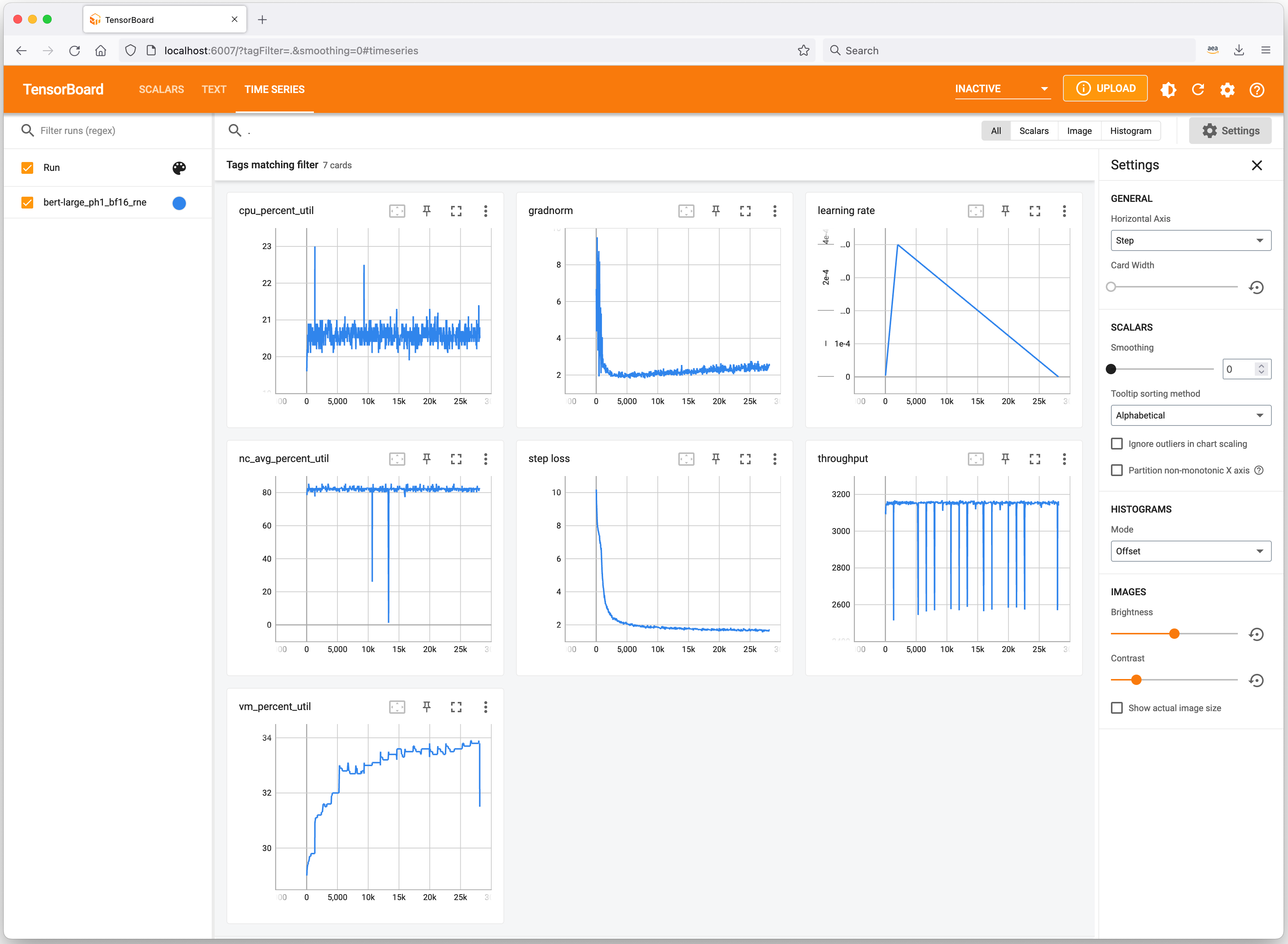
Let’s have a fast take a look at helpful instruments to maintain observe of your ML experiments and profile Trn1 occasion useful resource consumption. Neuron integrates with TensorBoard to trace and visualize your mannequin coaching metrics.
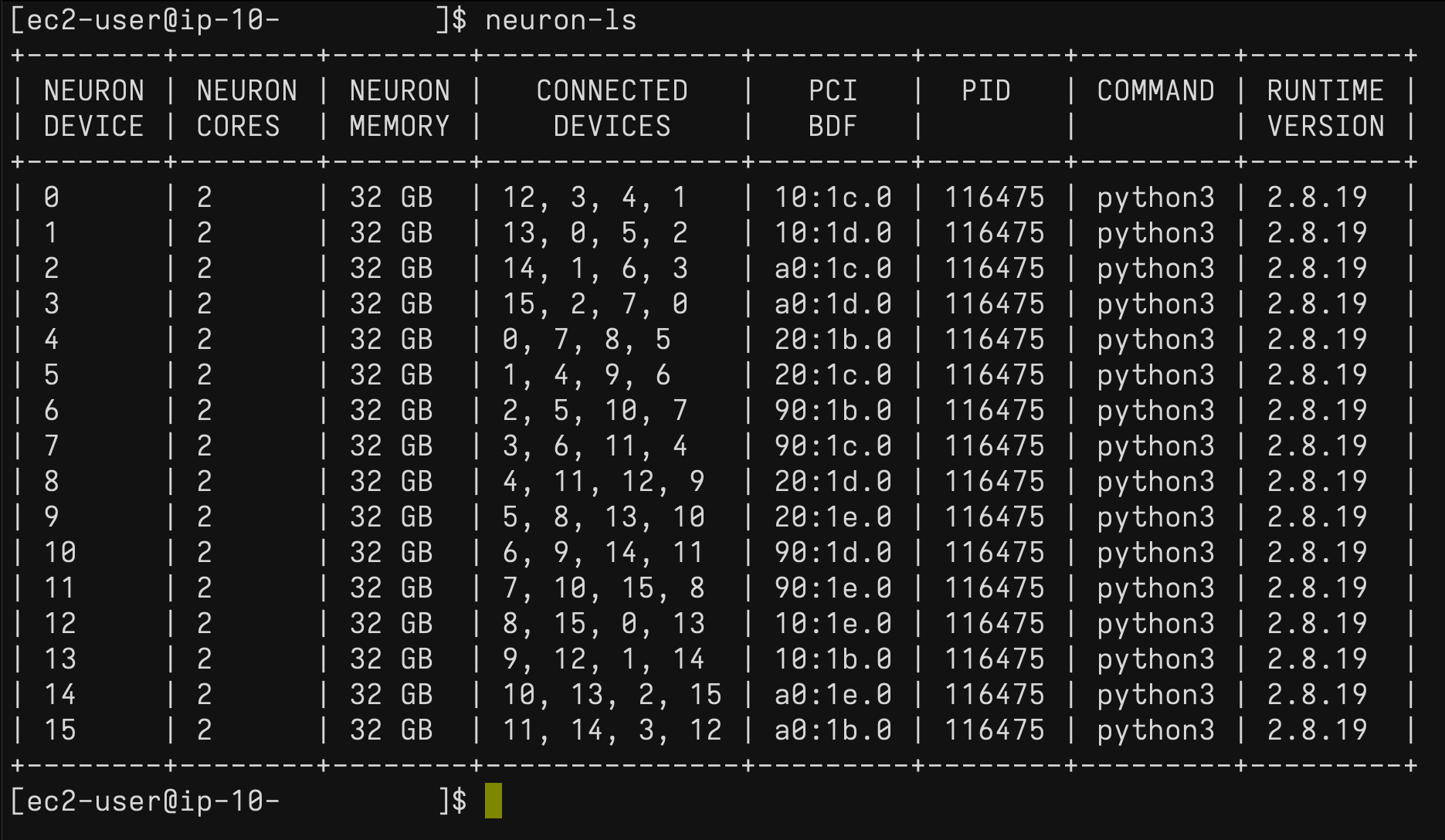
On the Trn1 occasion, you should utilize the neuron-ls command to explain the variety of Neuron units current within the system, together with the related NeuronCore rely, reminiscence, connectivity/topology, PCI system data, and the Python course of that presently has possession of the NeuronCores:
Equally, you should utilize the neuron-top command to see a high-level view of the Neuron setting. This exhibits the utilization of every of the NeuronCores, any fashions which are presently loaded onto a number of NeuronCores, course of IDs for any processes which are utilizing the Neuron runtime, and primary system statistics regarding vCPU and reminiscence utilization.

Out there Now
You possibly can launch Trn1 situations immediately within the AWS US East (N. Virginia) and US West (Oregon) Areas as On-Demand, Reserved, and Spot Situations or as a part of a Financial savings Plan. As typical with Amazon EC2, you pay just for what you employ. For extra data, see Amazon EC2 pricing.
Trn1 situations will be deployed utilizing AWS Deep Studying AMIs, and container photos can be found through managed providers corresponding to Amazon SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), and AWS ParallelCluster.
To study extra, go to our Amazon EC2 Trn1 situations web page, and please ship suggestions to AWS re:Publish for EC2 or via your typical AWS Help contacts.
— Antje