
{kind=link}
[ad_1]
TL;DR: Text Prompt -> LLM -> Intermediate Representation (akin to a picture format) -> Stable Diffusion -> Image.
Recent developments in text-to-image era with diffusion fashions have yielded exceptional outcomes synthesizing extremely life like and various photographs. However, regardless of their spectacular capabilities, diffusion fashions, akin to Stable Diffusion, usually battle to precisely comply with the prompts when spatial or widespread sense reasoning is required.
The following determine lists 4 situations wherein Stable Diffusion falls quick in producing photographs that precisely correspond to the given prompts, specifically negation, numeracy, and attribute task, spatial relationships. In distinction, our technique, LLM-grounded Diffusion (LMD), delivers significantly better immediate understanding in text-to-image era in these situations.

Figure 1: LLM-grounded Diffusion enhances the immediate understanding means of text-to-image diffusion fashions.
One attainable answer to handle this situation is after all to collect an enormous multi-modal dataset comprising intricate captions and practice a big diffusion mannequin with a big language encoder. This strategy comes with important prices: It is time-consuming and costly to coach each massive language fashions (LLMs) and diffusion fashions.
Our Solution
To effectively clear up this downside with minimal value (i.e., no coaching prices), we as a substitute equip diffusion fashions with enhanced spatial and customary sense reasoning through the use of off-the-shelf frozen LLMs in a novel two-stage era course of.
First, we adapt an LLM to be a text-guided format generator via in-context studying. When supplied with a picture immediate, an LLM outputs a scene format within the type of bounding bins together with corresponding particular person descriptions. Second, we steer a diffusion mannequin with a novel controller to generate photographs conditioned on the format. Both phases make the most of frozen pretrained fashions with none LLM or diffusion mannequin parameter optimization. We invite readers to learn the paper on arXiv for extra particulars.
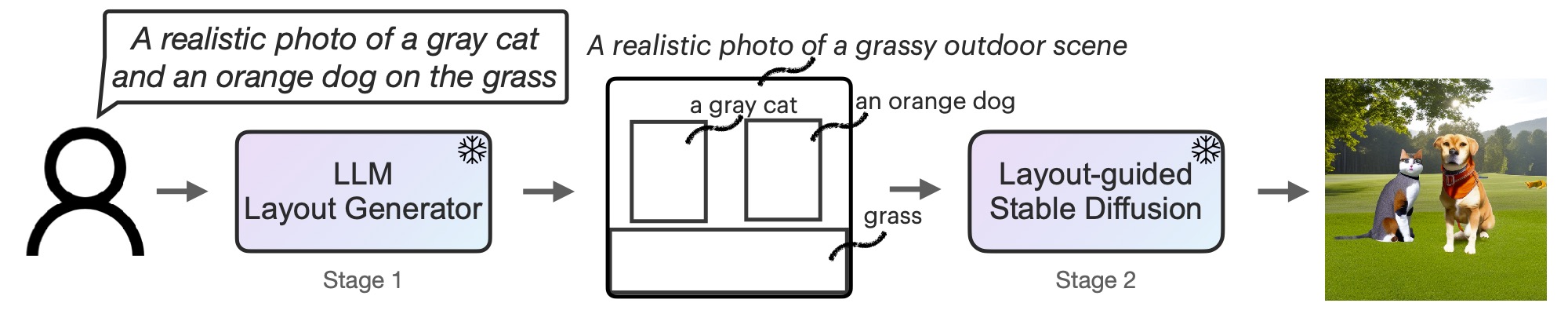
Figure 2: LMD is a text-to-image generative mannequin with a novel two-stage era course of: a text-to-layout generator with an LLM + in-context studying and a novel layout-guided secure diffusion. Both phases are training-free.
LMD’s Additional Capabilities
Additionally, LMD naturally permits dialog-based multi-round scene specification, enabling further clarifications and subsequent modifications for every immediate. Furthermore, LMD is ready to deal with prompts in a language that’s not well-supported by the underlying diffusion mannequin.

Figure 3: Incorporating an LLM for immediate understanding, our technique is ready to carry out dialog-based scene specification and era from prompts in a language (Chinese within the instance above) that the underlying diffusion mannequin doesn’t assist.
Given an LLM that helps multi-round dialog (e.g., GPT-3.5 or GPT-4), LMD permits the person to offer further info or clarifications to the LLM by querying the LLM after the primary format era within the dialog and generate photographs with the up to date format within the subsequent response from the LLM. For instance, a person might request so as to add an object to the scene or change the present objects in location or descriptions (the left half of Figure 3).
Furthermore, by giving an instance of a non-English immediate with a format and background description in English throughout in-context studying, LMD accepts inputs of non-English prompts and can generate layouts, with descriptions of bins and the background in English for subsequent layout-to-image era. As proven in the suitable half of Figure 3, this permits era from prompts in a language that the underlying diffusion fashions don’t assist.
Visualizations
We validate the prevalence of our design by evaluating it with the bottom diffusion mannequin (SD 2.1) that LMD makes use of underneath the hood. We invite readers to our work for extra analysis and comparisons.
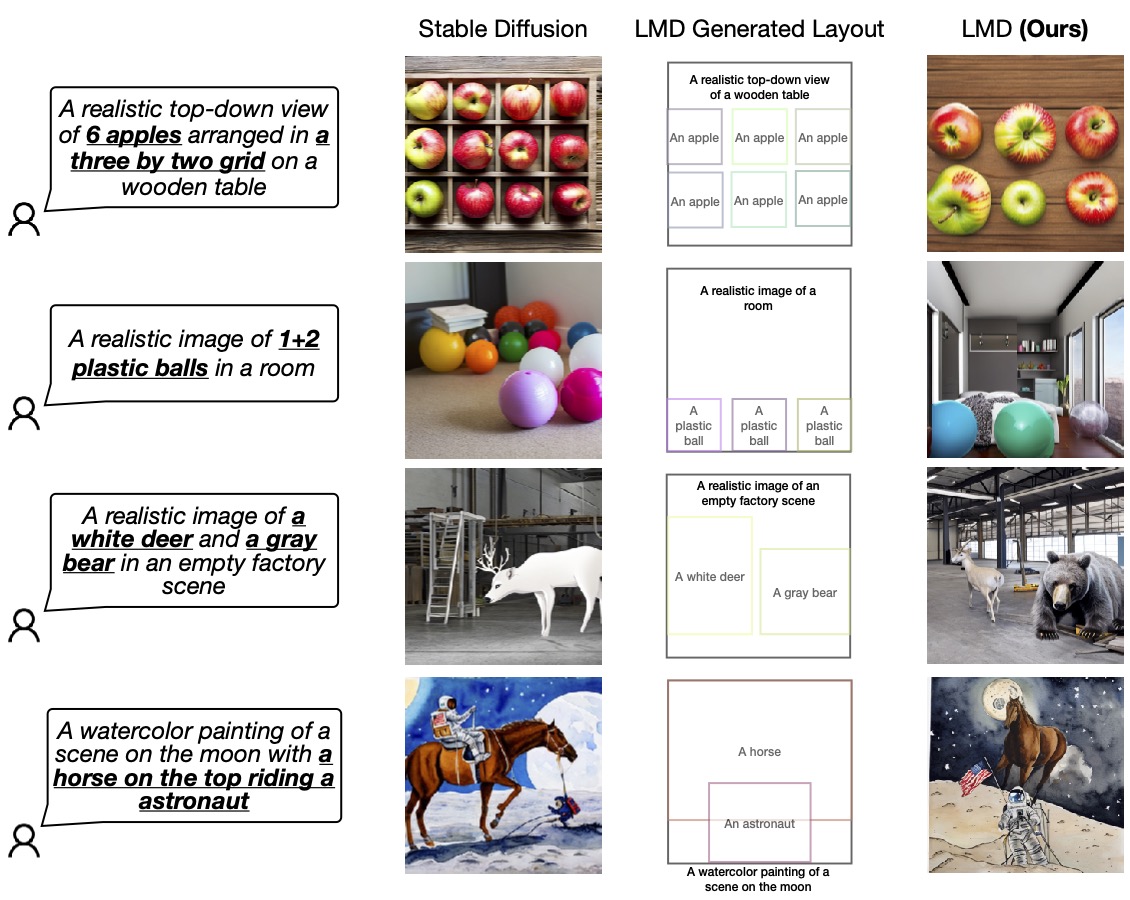
Figure 4: LMD outperforms the bottom diffusion mannequin in precisely producing photographs in accordance with prompts that necessitate each language and spatial reasoning. LMD additionally permits counterfactual text-to-image era that the bottom diffusion mannequin is just not capable of generate (the final row).
For extra particulars about LLM-grounded Diffusion (LMD), go to our web site and learn the paper on arXiv.
BibTex
If LLM-grounded Diffusion conjures up your work, please cite it with:
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models},
writer={Lian, Long and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
yr={2023}
}
[ad_2]