
{kind=link}
[ad_1]
When the COVID-19 pandemic erupted in early 2020, the world made an unprecedented shift to distant work. As a precaution, some Internet suppliers scaled again service ranges briefly, though that in all probability wasn’t crucial for international locations in Asia, Europe, and North America, which have been typically ready to deal with the surge in demand attributable to folks teleworking (and binge-watching Netflix). That’s as a result of most of their networks have been overprovisioned, with extra capability than they often want. But in international locations with out the identical stage of funding in community infrastructure, the image was much less rosy: Internet service suppliers (ISPs) in South Africa and Venezuela, as an illustration, reported important pressure.
But is overprovisioning the one method to make sure resilience? We don’t suppose so. To perceive the choice strategy we’re championing, although, you first must recall how the Internet works.
The core protocol of the Internet, aptly named the
Internet Protocol (IP), defines an addressing scheme that computer systems use to speak with each other. This scheme assigns addresses to particular gadgets—folks’s computer systems in addition to servers—and makes use of these addresses to ship knowledge between them as wanted.
It’s a mannequin that works effectively for sending distinctive info from one level to a different, say, your financial institution assertion or a letter from a cherished one. This strategy made sense when the Internet was used primarily to ship totally different content material to totally different folks. But this design just isn’t effectively suited to the mass consumption of static content material, resembling films or TV exhibits.
The actuality at this time is that the Internet is extra typically used to ship precisely the identical factor to many individuals, and it’s doing an enormous quantity of that now, a lot of which is within the type of video. The calls for develop even larger as our screens acquire ever-increasing resolutions, with 4K video already in widespread use and 8K on the horizon.
The
content material supply networks (CDNs) utilized by streaming providers resembling Netflix assist tackle the issue by briefly storing content material near, and even inside, many ISPs. But this technique depends on ISPs and CDNs with the ability to make offers and deploy the required infrastructure. And it could possibly nonetheless depart the sides of the community having to deal with extra site visitors than truly must move.
The actual downside just isn’t a lot the quantity of content material being handed round—it’s how it’s being delivered, from a central supply to many various far-away customers, even when these customers are positioned proper subsequent to 1 one other.
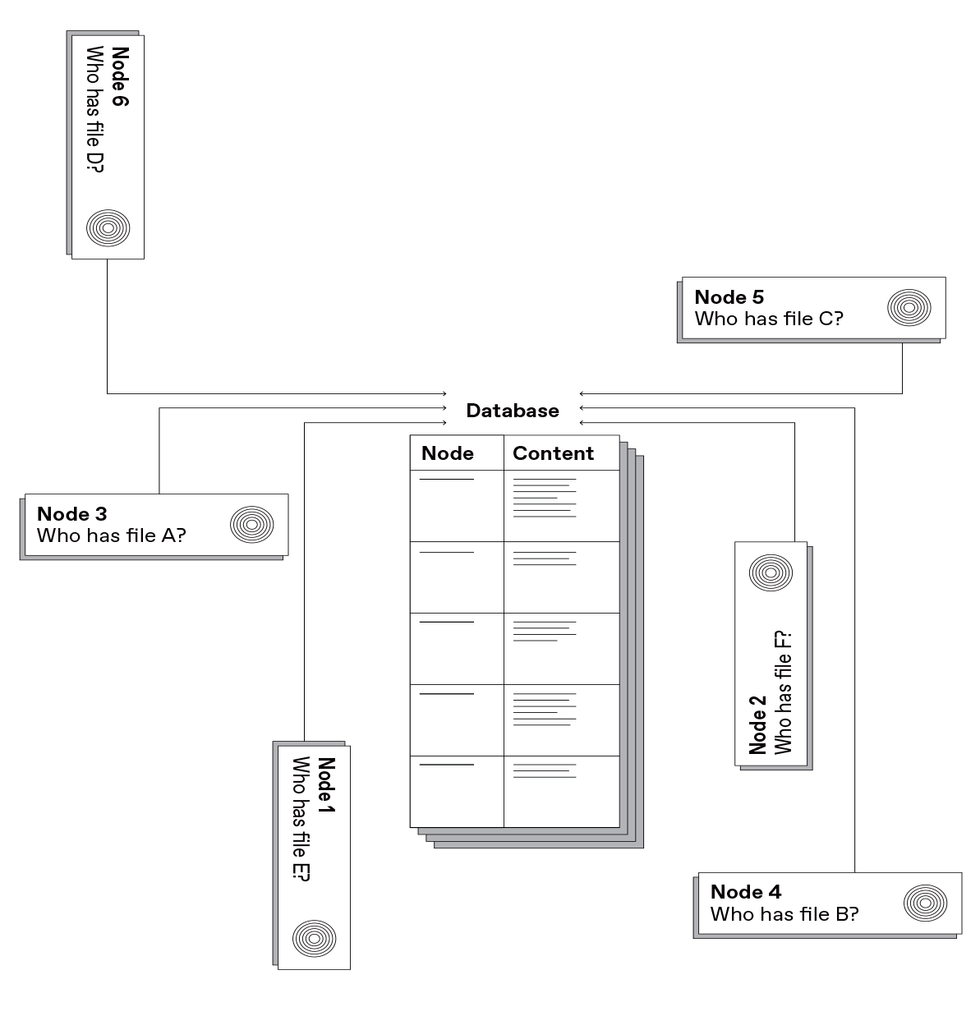 One scheme utilized by peer-to-peer programs to find out the situation of a file is to maintain that info in a centralized database. Napster, the primary large-scale peer-to-peer content-delivery system, used this strategy.Carl De Torres
One scheme utilized by peer-to-peer programs to find out the situation of a file is to maintain that info in a centralized database. Napster, the primary large-scale peer-to-peer content-delivery system, used this strategy.Carl De Torres
A extra environment friendly distribution scheme in that case can be for the information to be served to your gadget out of your neighbor’s gadget in a direct peer-to-peer method. But how would your gadget even know whom to ask? Welcome to the InterPlanetary File System (IPFS).
The InterPlanetary File System will get its title as a result of, in idea, it might be prolonged to share knowledge even between computer systems on totally different planets of the photo voltaic system. For now, although, we’re centered on rolling it out for simply Earth!
The key to IPFS is what’s referred to as content material addressing. Instead of asking a specific supplier, “Please send me this file,” your machine asks the community, “Who can send me this file?” It begins by querying friends: different computer systems within the person’s neighborhood, others in the identical home or workplace, others in the identical neighborhood, others in the identical metropolis—increasing progressively outward to globally distant areas, if want be, till the system finds a replica of what you’re searching for.
These queries are made utilizing IPFS, an alternative choice to the
Hypertext Transfer Protocol (HTTP), which powers the World Wide Web. Building on the rules of peer-to-peer networking and content-based addressing, IPFS permits for a decentralized and distributed community for knowledge storage and supply.
The advantages of IPFS embrace sooner and more-efficient distribution of content material. But they don’t cease there. IPFS may also enhance safety with content-integrity checking in order that knowledge can’t be tampered with by middleman actors. And with IPFS, the community can proceed working even when the connection to the originating server is lower or if the service that originally offered the content material is experiencing an outage—significantly essential in locations with networks that work solely intermittently. IPFS additionally affords resistance to censorship.
To perceive extra absolutely how IPFS differs from most of what takes place on-line at this time, let’s take a fast have a look at the Internet’s structure and a few earlier peer-to-peer approaches.
As talked about above, with at this time’s Internet structure, you request content material primarily based on a server’s tackle. This comes from the protocol that underlies the Internet and governs how knowledge flows from level to level, a scheme first described by Vint Cerf and Bob Kahn in a 1974 paper within the IEEE Transactions on Communications and now often called the Internet Protocol. The World Wide Web is constructed on high of the Internet Protocol. Browsing the Web consists of asking a selected machine, recognized by an IP tackle, for a given piece of knowledge.
Instead of asking a specific supplier, “Please send me this file,” your machine asks the community, “Who can send me this file?”
The course of begins when a person varieties a URL into the tackle bar of the browser, which takes the hostname portion and sends it to a
Domain Name System (DNS) server. That DNS server returns a corresponding numerical IP tackle. The person’s browser will then connect with the IP tackle and ask for the Web web page positioned at that URL.
In different phrases, even when a pc in the identical constructing has a replica of the specified knowledge, it can neither see the request, nor would it not have the ability to match it to the copy it holds as a result of the content material doesn’t have an intrinsic identifier—it isn’t content-addressed.
A content-addressing mannequin for the Internet would give knowledge, not gadgets, the main position. Requesters would ask for the content material explicitly, utilizing a singular identifier (akin to the
DOI quantity of a journal article or the ISBN of a e book), and the Internet would deal with forwarding the request to an obtainable peer that has a replica.
The main problem in doing so is that it might require adjustments to the core Internet infrastructure, which is owned and operated by 1000’s of ISPs worldwide, with no central authority in a position to management what all of them do. While this distributed structure is likely one of the Internet’s best strengths, it makes it practically not possible to make elementary adjustments to the system, which might then break issues for lots of the folks utilizing it. It’s typically very laborious even to implement incremental enhancements. A great instance of the problem encountered when introducing change is
IPv6, which expands the variety of attainable IP addresses. Today, virtually 25 years after its introduction, it nonetheless hasn’t reached 50 % adoption.
A method round this inertia is to implement adjustments at a better layer of abstraction, on high of current Internet protocols, requiring no modification to the underlying networking software program stacks or intermediate gadgets.
Other peer-to-peer programs apart from IPFS, resembling
BitTorrent and Freenet, have tried to do that by introducing programs that may function in parallel with the World Wide Web, albeit typically with Web interfaces. For instance, you’ll be able to click on on a Web hyperlink for the BitTorrent tracker related to a file, however this course of sometimes requires that the tracker knowledge be handed off to a separate utility out of your Web browser to deal with the transfers. And for those who can’t discover a tracker hyperlink, you’ll be able to’t discover the information.
Freenet additionally makes use of a distributed peer-to-peer system to retailer content material, which will be requested through an identifier and might even be accessed utilizing the Web’s HTTP protocol. But Freenet and IPFS have totally different goals: Freenet has a powerful concentrate on anonymity and manages the replication of knowledge in ways in which serve that objective however reduce efficiency and person management. IPFS offers versatile, high-performance sharing and retrieval mechanisms however retains management over knowledge within the palms of the customers.
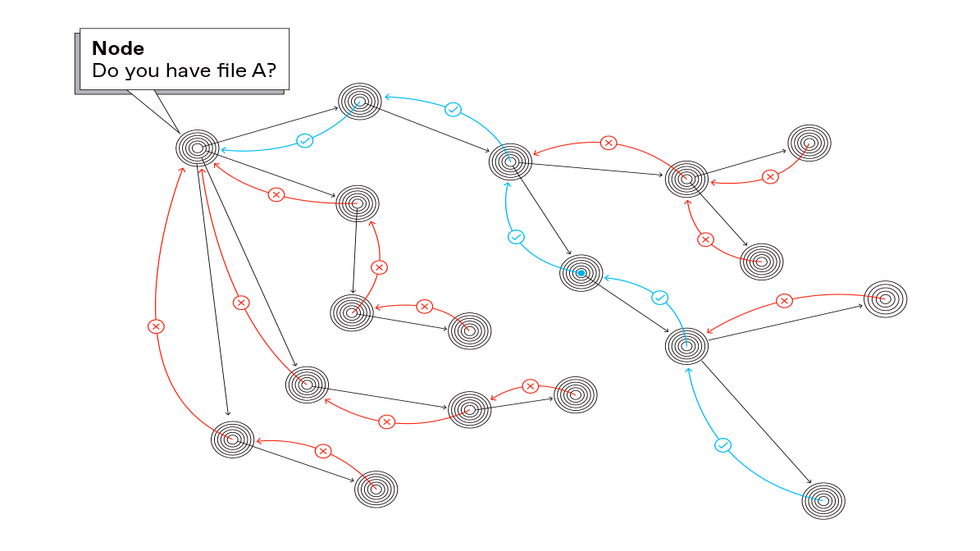 Another strategy to discovering a file in a peer-to-peer community known as question flooding. The node searching for a file broadcasts a request for it to all nodes to which it’s hooked up. If the node receiving the request doesn’t have the file [red], it forwards the request to all of the nodes to which it’s hooked up till lastly a node with the file passes a replica again to the requester [blue]. The Gnutella peer-to-peer community used this protocol.Carl De Torres
Another strategy to discovering a file in a peer-to-peer community known as question flooding. The node searching for a file broadcasts a request for it to all nodes to which it’s hooked up. If the node receiving the request doesn’t have the file [red], it forwards the request to all of the nodes to which it’s hooked up till lastly a node with the file passes a replica again to the requester [blue]. The Gnutella peer-to-peer community used this protocol.Carl De Torres
We designed IPFS as a protocol to improve the Web and to not create an alternate model. It is designed to make the Web higher, to permit folks to work offline, to make hyperlinks everlasting, to be sooner and safer, and to make it as straightforward as attainable to make use of.
IPFS began in 2013 as an open-source venture supported by Protocol Labs, the place we work, and constructed by a vibrant group and ecosystem with a whole bunch of organizations and 1000’s of builders. IPFS is constructed on a powerful basis of earlier work in peer-to-peer (P2P) networking and content-based addressing.
The core tenet of all P2P programs is that customers concurrently take part as shoppers (which request and obtain information from others)
and as servers (which retailer and ship information to others). The mixture of content material addressing and P2P offers the fitting components for fetching knowledge from the closest peer that holds a replica of what’s desired—or extra accurately, the closest one by way of community topology, although not essentially in bodily distance.
To make this occur, IPFS produces a fingerprint of the content material it holds (referred to as a
hash) that no different merchandise can have. That hash will be considered a singular tackle for that piece of content material. Changing a single bit in that content material will yield a completely totally different tackle. Computers eager to fetch this piece of content material broadcast a request for a file with this explicit hash.
Because identifiers are distinctive and by no means change, folks typically seek advice from IPFS because the “Permanent Web.” And with identifiers that by no means change, the community will have the ability to discover a particular file so long as some laptop on the community shops it.
Name persistence and immutability inherently present one other important property: verifiability. Having the content material and its identifier, a person can confirm that what was acquired is what was requested for and has not been tampered with, both in transit or by the supplier. This not solely improves safety but additionally helps safeguard the general public file and stop historical past from being rewritten.
You would possibly marvel what would occur with content material that must be up to date to incorporate contemporary info, resembling a Web web page. This is a sound concern and IPFS does have a collection of mechanisms that may level customers to probably the most up-to-date content material.
Reducing the duplication of knowledge shifting by way of the community and procuring it from close by sources will let ISPs present sooner service at decrease value.
The world had an opportunity to look at how content material addressing labored in April 2017 when the federal government of Turkey
blocked entry to Wikipedia as a result of an article on the platform described Turkey as a state that sponsored terrorism. Within every week, a full copy of the Turkish model of Wikipedia was added to IPFS, and it remained accessible to folks within the nation for the practically three years that the ban continued.
The same demonstration passed off half a 12 months later, when the Spanish authorities tried to suppress an independence referendum in Catalonia, ordering ISPs to dam associated web sites. Once once more, the knowledge
remained obtainable through IPFS.
IPFS is an open, permissionless community: Any person can be part of and fetch or present content material. Despite quite a few open-source success tales, the present Internet is closely primarily based on closed platforms, lots of which undertake lock-in techniques but additionally supply customers nice comfort. While IPFS can present improved effectivity, privateness, and safety, giving this decentralized platform the extent of usability that persons are accustomed to stays a problem.
You see, the peer-to-peer, unstructured nature of IPFS is each a power and a weak point. While CDNs have constructed sprawling infrastructure and superior strategies to supply high-quality service, IPFS nodes are operated by finish customers. The community due to this fact depends on their conduct—how lengthy their computer systems are on-line, how good their connectivity is, and what knowledge they resolve to cache. And typically these issues should not optimum.
One of the important thing analysis questions for the oldsters working at Protocol Labs is how one can hold the IPFS community resilient regardless of shortcomings within the nodes that make it up—and even when these nodes exhibit egocentric or malicious conduct. We’ll want to beat such points if we’re to maintain the efficiency of IPFS aggressive with standard distribution channels.
You could have seen that we haven’t but offered an instance of an IPFS tackle. That’s as a result of hash-based addressing ends in URLs that aren’t straightforward to spell out or kind.
For occasion, you could find the Wikipedia emblem on IPFS through the use of the next tackle in an appropriate browser:
ipfs://QmRW3V9znzFW9M5FYbitSEvd5dQrPWGvPvgQD6LM22Tv8D/. That lengthy string will be considered a digital fingerprint for the file holding that emblem.
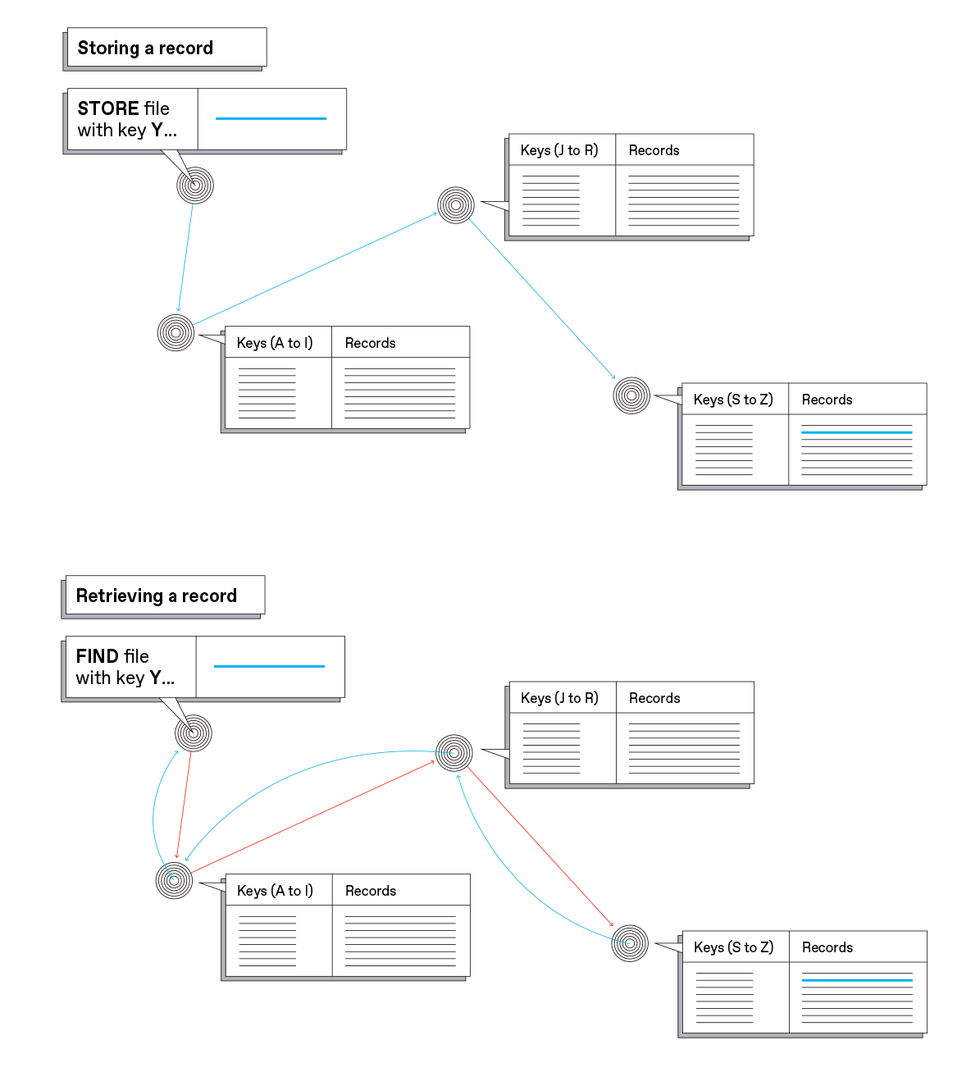 To hold observe of which nodes maintain which information, the InterPlanetary File System makes use of what’s referred to as a distributed hash desk. In this simplified view, three nodes maintain totally different components of a desk that has two columns: One column (Keys) comprises hashes of the saved information; the opposite column (Records) comprises the information themselves. Depending on what its hashed secret is, a file will get saved within the applicable place [left]—depicted right here as if the system checked the primary letter of hashes and saved totally different components of the alphabet in other places. The precise algorithm for distributing information is extra advanced, however the idea is analogous. Retrieving a file is environment friendly as a result of it’s attainable to find the file in response to what its hash is [right].Carl De Torres
To hold observe of which nodes maintain which information, the InterPlanetary File System makes use of what’s referred to as a distributed hash desk. In this simplified view, three nodes maintain totally different components of a desk that has two columns: One column (Keys) comprises hashes of the saved information; the opposite column (Records) comprises the information themselves. Depending on what its hashed secret is, a file will get saved within the applicable place [left]—depicted right here as if the system checked the primary letter of hashes and saved totally different components of the alphabet in other places. The precise algorithm for distributing information is extra advanced, however the idea is analogous. Retrieving a file is environment friendly as a result of it’s attainable to find the file in response to what its hash is [right].Carl De Torres
There are different content-addressing schemes that use human-readable naming, or hierarchical, URL-style naming, however every comes with its personal set of trade-offs. Finding sensible methods to make use of human-readable names with IPFS would go a good distance towards enhancing user-friendliness. It’s a objective, however we’re not there but.
Protocol Labs, has been tackling these and different technical, usability, and societal points for a lot of the final decade. Over this time, now we have been seeing quickly growing adoption of IPFS, with its community measurement doubling 12 months over 12 months. Scaling up at such speeds brings many challenges. But that’s par for the course when your intent is altering the Internet as we all know it.
Widespread adoption of content material addressing and IPFS ought to assist the entire Internet ecosystem. By empowering customers to request actual content material and confirm that they acquired it unaltered, IPFS will enhance belief and safety. Reducing the duplication of knowledge shifting by way of the community and procuring it from close by sources will let ISPs present sooner service at decrease value. Enabling the community to proceed offering service even when it turns into partitioned will make our infrastructure extra resilient to pure disasters and different large-scale disruptions.
But is there a darkish facet to decentralization? We typically hear issues about how peer-to-peer networks could also be utilized by dangerous actors to assist criminality. These issues are essential however typically overstated.
One space the place IPFS improves on HTTP is in permitting complete auditing of saved knowledge. For instance, due to its content-addressing performance and, particularly, to using distinctive and everlasting content material identifiers, IPFS makes it simpler to find out whether or not sure content material is current on the community, and which nodes are storing it. Moreover, IPFS makes it trivial for customers to resolve what content material they distribute and what content material they cease distributing (by merely deleting it from their machines).
At the identical time, IPFS offers no mechanisms to permit for censorship, provided that it operates as a distributed P2P file system with no central authority. So there is no such thing as a actor with the technical means to ban the storage and propagation of a file or to delete a file from different friends’ storage. Consequently, censorship of undesirable content material can’t be technically enforced, which represents a safeguard for customers whose freedom of speech is beneath risk. Lawful requests to take down content material are nonetheless attainable, however they must be addressed to the customers truly storing it, avoiding commonplace abuses (like illegitimate
DMCA takedown requests) towards which massive platforms have difficulties defending.
Ultimately, IPFS is an open community, ruled by group guidelines, and open to everybody. And you’ll be able to develop into part of it at this time! The
Brave browser ships with built-in IPFS assist, as does Opera for Android. There are browser extensions obtainable for Chrome and Firefox, and IPFS Desktop makes it straightforward to run an area node. Several organizations present IPFS-based internet hosting providers, whereas others function public gateways that mean you can fetch knowledge from IPFS by way of the browser with none particular software program.
These gateways act as entries to the P2P community and are essential to bootstrap adoption. Through some easy DNS magic, a website will be configured so {that a} person’s entry request will end result within the corresponding content material being retrieved and served by a gateway, in a method that’s utterly clear to the person.
So far, IPFS has been used to construct assorted purposes, together with programs for
e-commerce, safe distribution of scientific knowledge units, mirroring Wikipedia, creating new social networks, sharing most cancers knowledge, blockchain creation, safe and encrypted personal-file storage and sharing, developerinstruments, and knowledge analytics.
You could have used this community already: If you’ve ever visited the Protocol Labs web site (
Protocol.ai), you’ve retrieved pages of an internet site from IPFS with out even realizing it!
This article seems within the November 2022 print situation as “To the InterPlanetary File System—and Beyond!”
From Your Site Articles
Related Articles Around the Web
[ad_2]