
{kind=link}
[ad_1]
Large-scale fashions, equivalent to T5, GPT-3, PaLM, Flamingo and PaLI, have demonstrated the power to retailer substantial quantities of data when scaled to tens of billions of parameters and skilled on giant textual content and picture datasets. These fashions obtain state-of-the-art outcomes on downstream duties, equivalent to picture captioning, visible query answering and open vocabulary recognition. Despite such achievements, these fashions require an enormous quantity of knowledge for coaching and find yourself with an incredible variety of parameters (billions in lots of instances), leading to vital computational necessities. Moreover, the info used to coach these fashions can grow to be outdated, requiring re-training each time the world’s information is up to date. For instance, a mannequin skilled simply two years in the past would possibly yield outdated details about the present president of the United States.
In the fields of pure language processing (RETRO, REALM) and pc imaginative and prescient (KAT), researchers have tried to deal with these challenges utilizing retrieval-augmented fashions. Typically, these fashions use a spine that is ready to course of a single modality at a time, e.g., solely textual content or solely photographs, to encode and retrieve data from a information corpus. However, these retrieval-augmented fashions are unable to leverage all obtainable modalities in a question and information corpora, and should not discover the knowledge that’s most useful for producing the mannequin’s output.
To tackle these points, in “REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory”, to look at CVPR 2023, we introduce a visual-language mannequin that learns to make the most of a multi-source multi-modal “memory” to reply knowledge-intensive queries. REVEAL employs neural illustration studying to encode and convert numerous information sources right into a reminiscence construction consisting of key-value pairs. The keys function indices for the reminiscence gadgets, whereas the corresponding values retailer pertinent details about these gadgets. During coaching, REVEAL learns the important thing embeddings, worth tokens, and the power to retrieve data from this reminiscence to deal with knowledge-intensive queries. This strategy permits the mannequin parameters to give attention to reasoning concerning the question, slightly than being devoted to memorization.
 |
| We increase a visual-language mannequin with the power to retrieve a number of information entries from a various set of data sources, which helps era. |
Memory building from multimodal information corpora
Our strategy is just like REALM in that we precompute key and worth embeddings of data gadgets from completely different sources and index them in a unified information reminiscence, the place every information merchandise is encoded right into a key-value pair. Each secret is a d-dimensional embedding vector, whereas every worth is a sequence of token embeddings representing the information merchandise in additional element. In distinction to earlier work, REVEAL leverages a various set of multimodal information corpora, together with the WikiData information graph, Wikipedia passages and pictures, net image-text pairs and visible query answering information. Each information merchandise could possibly be textual content, a picture, a mixture of each (e.g., pages in Wikipedia) or a relationship or attribute from a knowledge graph (e.g., Barack Obama is 6’ 2” tall). During coaching, we repeatedly re-compute the reminiscence key and worth embeddings because the mannequin parameters get up to date. We replace the reminiscence asynchronously at each thousand coaching steps.
Scaling reminiscence utilizing compression
A naïve resolution for encoding a reminiscence worth is to maintain the entire sequence of tokens for every information merchandise. Then, the mannequin may fuse the enter question and the top-k retrieved reminiscence values by concatenating all their tokens collectively and feeding them right into a transformer encoder-decoder pipeline. This strategy has two points: (1) storing a whole bunch of hundreds of thousands of data gadgets in reminiscence is impractical if every reminiscence worth consists of a whole bunch of tokens and (2) the transformer encoder has a quadratic complexity with respect to the overall variety of tokens occasions ok for self-attention. Therefore, we suggest to make use of the Perceiver structure to encode and compress information gadgets. The Perceiver mannequin makes use of a transformer decoder to compress the total token sequence into an arbitrary size. This lets us retrieve top-ok reminiscence entries for ok as giant as 100.
The following determine illustrates the process of establishing the reminiscence key-value pairs. Each information merchandise is processed via a multi-modal visual-language encoder, leading to a sequence of picture and textual content tokens. The key head then transforms these tokens right into a compact embedding vector. The worth head (perceiver) condenses these tokens into fewer ones, retaining the pertinent details about the information merchandise inside them.
 |
| We encode the information entries from completely different corpora into unified key and worth embedding pairs, the place the keys are used to index the reminiscence and values comprise details about the entries. |
Large-scale pre-training on image-text pairs
To practice the REVEAL mannequin, we start with the large-scale corpus, collected from the general public Web with three billion picture alt-text caption pairs, launched in LiT. Since the dataset is noisy, we add a filter to take away information factors with captions shorter than 50 characters, which yields roughly 1.3 billion picture caption pairs. We then take these pairs, mixed with the textual content era goal utilized in SimVLM, to coach REVEAL. Given an image-text instance, we randomly pattern a prefix containing the primary few tokens of the textual content. We feed the textual content prefix and picture to the mannequin as enter with the target of producing the remainder of the textual content as output. The coaching aim is to situation the prefix and autoregressively generate the remaining textual content sequence.
To practice all elements of the REVEAL mannequin end-to-end, we have to heat begin the mannequin to a great state (setting preliminary values to mannequin parameters). Otherwise, if we have been to begin with random weights (cold-start), the retriever would usually return irrelevant reminiscence gadgets that might by no means generate helpful coaching indicators. To keep away from this cold-start drawback, we assemble an preliminary retrieval dataset with pseudo–ground-truth information to present the pre-training an inexpensive head begin.
We create a modified model of the WIT dataset for this function. Each image-caption pair in WIT additionally comes with a corresponding Wikipedia passage (phrases surrounding the textual content). We put collectively the encircling passage with the question picture and use it because the pseudo ground-truth information that corresponds to the enter question. The passage gives wealthy details about the picture and caption, which is helpful for initializing the mannequin.
To forestall the mannequin from counting on low-level picture options for retrieval, we apply random information augmentation to the enter question picture. Given this modified dataset that incorporates pseudo-retrieval ground-truth, we practice the question and reminiscence key embeddings to heat begin the mannequin.
REVEAL workflow
The general workflow of REVEAL consists of 4 main steps. First, REVEAL encodes a multimodal enter right into a sequence of token embeddings together with a condensed question embedding. Then, the mannequin interprets every multi-source information entry into unified pairs of key and worth embeddings, with the important thing being utilized for reminiscence indexing and the worth encompassing the complete details about the entry. Next, REVEAL retrieves the top-ok most associated information items from a number of information sources, returns the pre-processed worth embeddings saved in reminiscence, and re-encodes the values. Finally, REVEAL fuses the top-ok information items via an attentive information fusion layer by injecting the retrieval rating (dot product between question and key embeddings) as a previous throughout consideration calculation. This construction is instrumental in enabling the reminiscence, encoder, retriever and the generator to be concurrently skilled in an end-to-end trend.
 |
| Overall workflow of REVEAL. |
Results
We consider REVEAL on knowledge-based visible query answering duties utilizing OK-VQA and A-OKVQA datasets. We fine-tune our pre-trained mannequin on the VQA duties utilizing the identical generative goal the place the mannequin takes in an image-question pair as enter and generates the textual content reply as output. We show that REVEAL achieves higher outcomes on the A-OKVQA dataset than earlier makes an attempt that incorporate a hard and fast information or the works that make the most of giant language fashions (e.g., GPT-3) as an implicit supply of data.
 |
| Visual query answering outcomes on A-OKVQA. REVEAL achieves greater accuracy compared to earlier works together with ViLBERT, LXMERT, ClipCap, KRISP and GPV-2. |
We additionally consider REVEAL on the picture captioning benchmarks utilizing MSCOCO and NoCaps dataset. We immediately fine-tune REVEAL on the MSCOCO coaching break up by way of the cross-entropy generative goal. We measure our efficiency on the MSCOCO take a look at break up and NoCaps analysis set utilizing the CIDEr metric, which relies on the concept that good captions needs to be just like reference captions by way of phrase selection, grammar, that means, and content material. Our outcomes on MSCOCO caption and NoCaps datasets are proven under.
 |
| Image Captioning outcomes on MSCOCO and NoCaps utilizing the CIDEr metric. REVEAL achieves a better rating compared to Flamingo, VinVL, SimVLM and CoCa. |
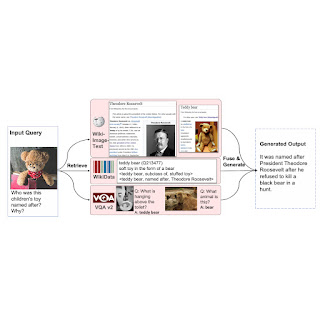
Below we present a few qualitative examples of how REVEAL retrieves related paperwork to reply visible questions.
 |
| REVEAL can use information from completely different sources to accurately reply the query. |
Conclusion
We current an end-to-end retrieval-augmented visible language (REVEAL) mannequin, which incorporates a information retriever that learns to make the most of a various set of data sources with completely different modalities. We practice REVEAL on an enormous image-text corpus with 4 numerous information corpora, and obtain state-of-the-art outcomes on knowledge-intensive visible query answering and picture caption duties. In the long run we wish to discover the power of this mannequin for attribution, and apply it to a broader class of multimodal duties.
Acknowledgements
This analysis was carried out by Ziniu Hu, Ahmet Iscen, Chen Sun, Zirui Wang, Kai-Wei Chang, Yizhou Sun, Cordelia Schmid, David A. Ross and Alireza Fathi.
[ad_2]