
{kind=link}
[ad_1]

|
In 2019, we introduced Amazon SageMaker Studio, the primary totally built-in growth surroundings (IDE) for knowledge science and machine studying (ML). SageMaker Studio offers you entry to totally managed Jupyter Notebooks that combine with purpose-built instruments to carry out all ML steps, from getting ready knowledge to coaching and debugging fashions, monitoring experiments, deploying and monitoring fashions, and managing pipelines.
Today, I’m excited to announce the subsequent technology of Amazon SageMaker Notebooks to extend effectivity throughout the ML growth workflow. You can now enhance knowledge high quality in minutes with the built-in knowledge preparation functionality, edit the identical notebooks together with your groups in actual time, and robotically convert pocket book code to production-ready jobs.
Let me present you what’s new!
New Notebook Capability for Simplified Data Preparation
The new built-in knowledge preparation functionality is powered by Amazon SageMaker Data Wrangler and is obtainable in SageMaker Studio notebooks. SageMaker Studio notebooks robotically generate key visualizations on high of Pandas knowledge frames that can assist you perceive knowledge distribution and determine knowledge high quality points, like lacking values, invalid knowledge, and outliers. You also can choose the goal column for ML fashions and generate ML-specific insights corresponding to imbalanced class or excessive correlation columns. You then obtain suggestions for knowledge transformations to resolve the problems. You can apply the info transformations proper within the UI, and SageMaker Studio notebooks robotically generate the corresponding transformation code within the pocket book cells that you need to use to replay your knowledge preparation pipeline.
Using the Built-in Data Preparation Capability
To get began, pip set up and import sagemaker_datawrangler together with the pandas Python package deal. Then, obtain the dataset you wish to analyze to the pocket book working listing, and skim the dataset with pandas.
import pandas as pd
import sagemaker_datawrangler
!aws s3 cp s3://<YOUR_S3_BUCKET>/knowledge.csv .
df = pd.read_csv("knowledge.csv")
Now, if you show the info body, it robotically exhibits key knowledge visualizations on the high of every column, surfaces knowledge insights, detects knowledge high quality points, and suggests options to enhance knowledge high quality. When you choose a column because the goal column for ML predictions, you get target-specific insights and warnings, corresponding to combined knowledge sorts in goal (for regression use instances) or too few situations per class (for classification use instances).
In this instance, I’m utilizing the Women’s E-Commerce Clothing Reviews dataset that incorporates buyer evaluations and rankings for ladies’s clothes. This dataset was obtained from Kaggle and has been modified by Amazon so as to add artificial knowledge high quality points.

You can evaluate the urged knowledge transformations to enhance the info high quality and apply them proper within the UI. For a listing of all supported knowledge transformations, take a look on the documentation. Once you apply an information transformation, SageMaker Studio notebooks robotically generate the code to breed these knowledge preparation steps in one other pocket book cell.
For my instance, I choose Rating as my goal column. Target column insights tells me in a high-priority warning that this column has too few situations per class and with a medium-priority warning that courses are too imbalanced. Let’s observe the strategies and drop uncommon goal values and drop lacking values. I may even observe the strategies for a number of the characteristic columns and drop lacking values within the Review Text column and drop the Division Name column.
Once I apply the transformations, the pocket book generates this code for me:
# Pandas code generated by sagemaker_datawrangler
output_df = df.copy(deep=True)
# Code to Drop uncommon goal values for column: Rating to resolve warning: Too few situations per class
rare_target_labels_to_drop = ['-100', '100']
output_df = output_df[~output_df['Rating'].isin(rare_target_labels_to_drop)]
# Code to Drop lacking for column: Rating to resolve warning: Missing values
output_df = output_df[output_df['Rating'].notnull()]
# Code to Drop lacking for column: Review Text to resolve warning: Missing values
output_df = output_df[output_df['Review Text'].notnull()]
# Code to Drop column for column: Division Name to resolve warning: Missing values
output_df=output_df.drop(columns=['Division Name'])I can now evaluate and modify the code if wanted or begin integrating the info transformations as a part of my ML growth workflow.
Introducing Shared Spaces for Team-Based Sharing and Real-Time Collaboration
SageMaker Studio now affords shared areas that give knowledge science and ML groups a workspace the place they will learn, edit, and run notebooks collectively in actual time to streamline collaboration and communication in the course of the growth course of. Shared areas present a shared Amazon EFS listing that you would be able to make the most of to share information inside a shared area. All taggable SageMaker sources that you just create in a shared area are robotically tagged that can assist you set up and have a filtered view of your ML sources, corresponding to coaching jobs, experiments, and fashions, which are related to the enterprise downside you’re employed on within the area. This additionally helps you monitor prices and plan budgets utilizing instruments corresponding to AWS Budgets and AWS Cost Explorer.
And that’s not all. You can now additionally create a number of SageMaker domains inside the identical AWS account to scope entry and isolate sources to totally different groups or enterprise items in your group. Now, let me present you the best way to create a shared area for customers inside a SageMaker area.
Using Shared Spaces
You can use the SageMaker console or the AWS CLI to create shared areas for a SageMaker area. To get began within the SageMaker console, go to Domains, choose or create a brand new area, and choose Space administration on the Domain particulars web page. Then, choose Create and provides the shared area a reputation.
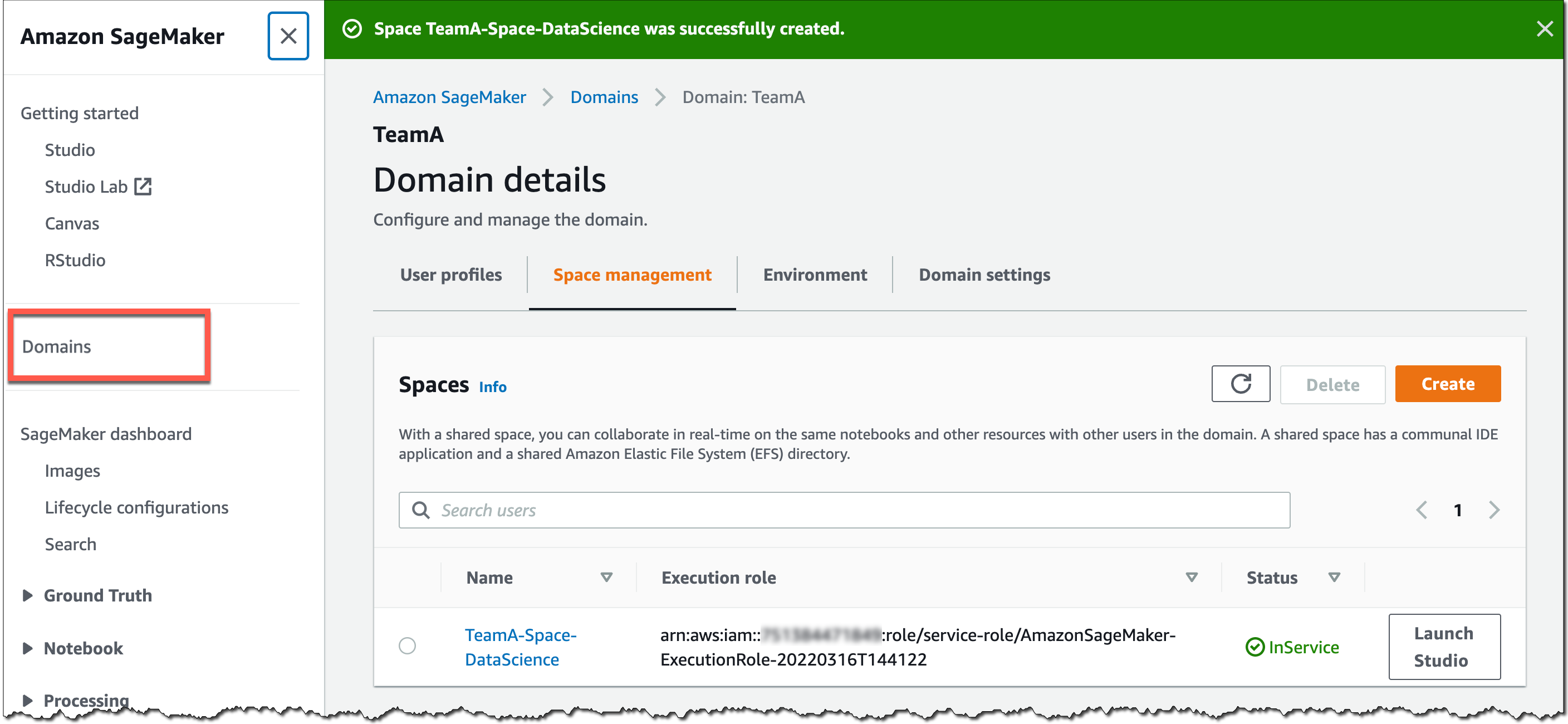
Users on this SageMaker area can now launch and be part of the shared area by way of their SageMaker area consumer profiles.
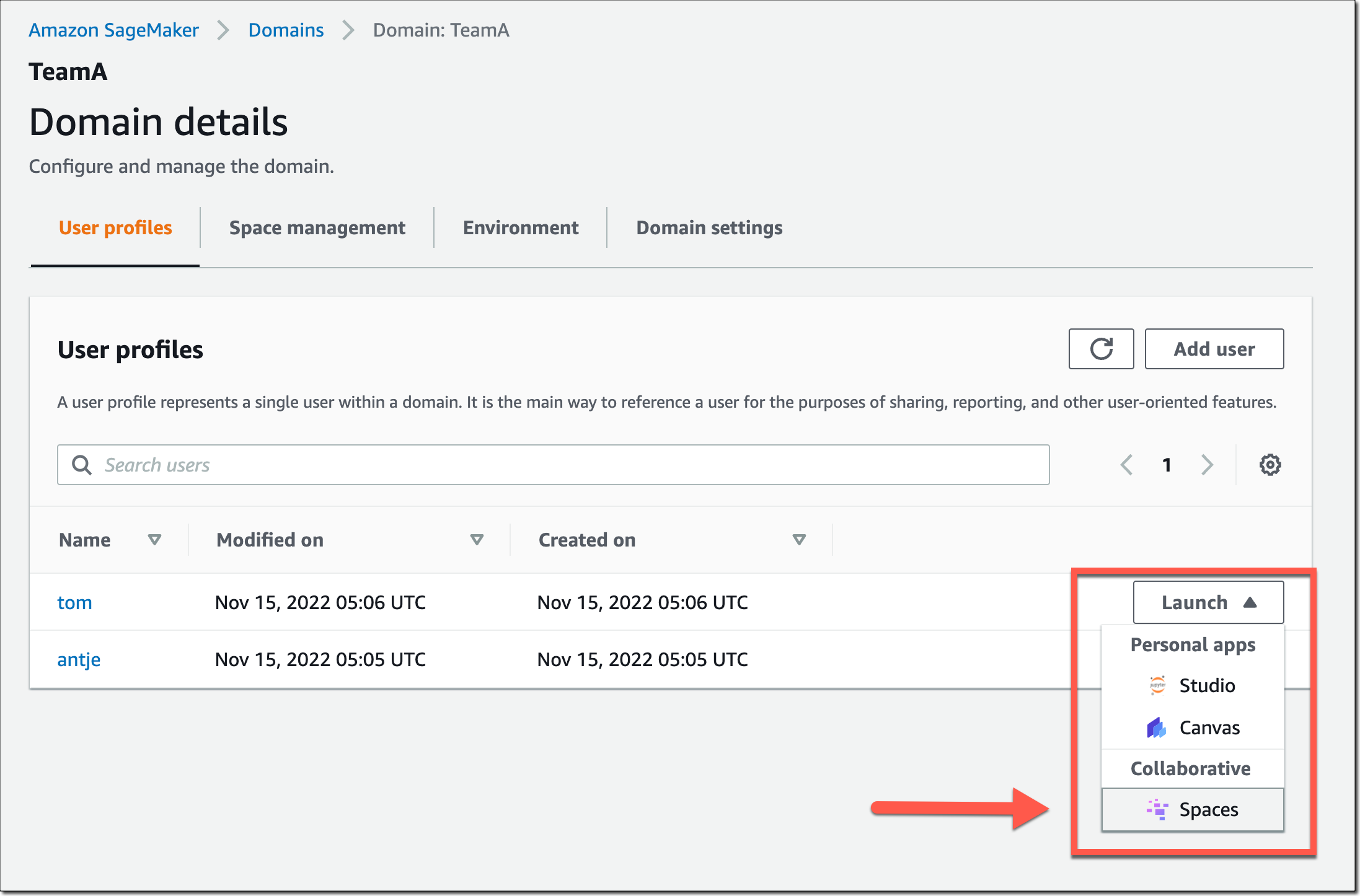
In a shared area, choose the brand new Collaborators icon within the left navigation menu. You can now see who else is at the moment lively on this area. The following screenshot exhibits consumer tom on the left, modifying a pocket book file. On the precise, consumer antje sees the edits in actual time, along with an annotation of the consumer identify that at the moment edits that pocket book cell.

New Notebook Capability to Automatically Convert Notebook Code to Production-Ready Jobs
You can now choose a pocket book and automate it as a job that may run in a manufacturing surroundings with out the necessity to handle the underlying infrastructure. When you create a SageMaker Notebook Job, SageMaker Studio takes a snapshot of the whole pocket book, packages its dependencies in a container, builds the infrastructure, runs the pocket book as an automatic job on a schedule you outline, and deprovisions the infrastructure upon job completion. This pocket book functionality is now additionally accessible in SageMaker Studio Lab, our free ML growth surroundings that gives the compute, storage, and safety to study and experiment with ML.
Using the Notebook Capability to Automate Notebooks
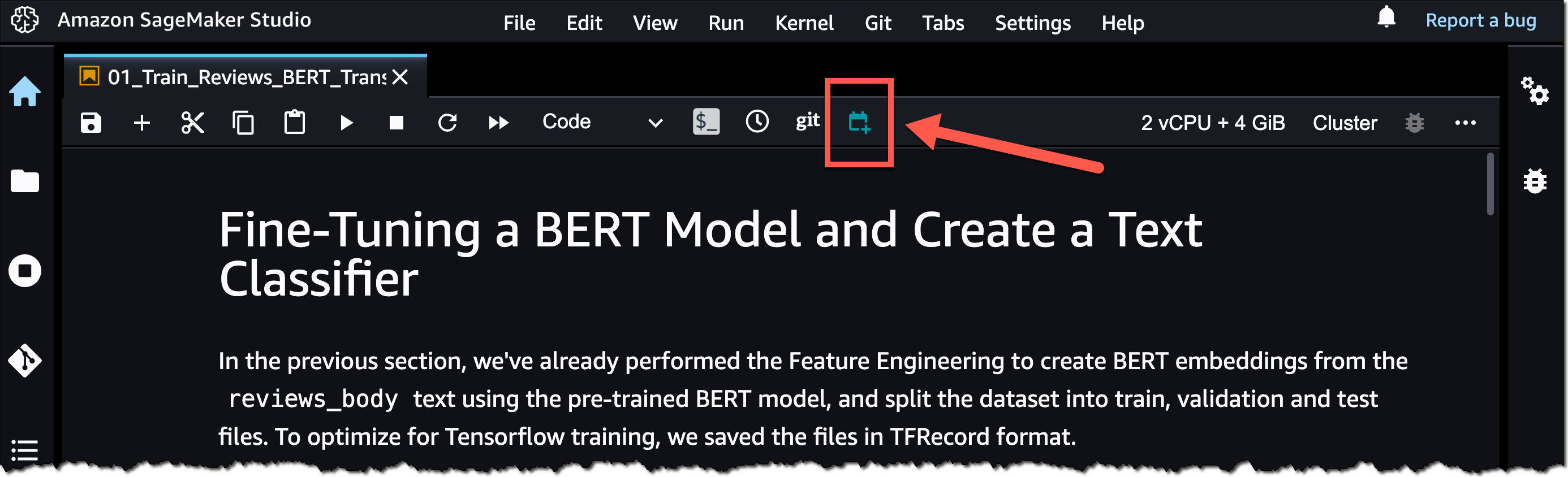
To get began, open a pocket book file in SageMaker Studio. Then, right-click your pocket book file and choose Create Notebook Job or choose the Create Notebook Job icon, as highlighted within the following screenshot.
Define a reputation for the Notebook Job, evaluate the enter file location, specify the compute sort to make use of, and whether or not to run the job instantly or on a schedule. Then, choose Create.
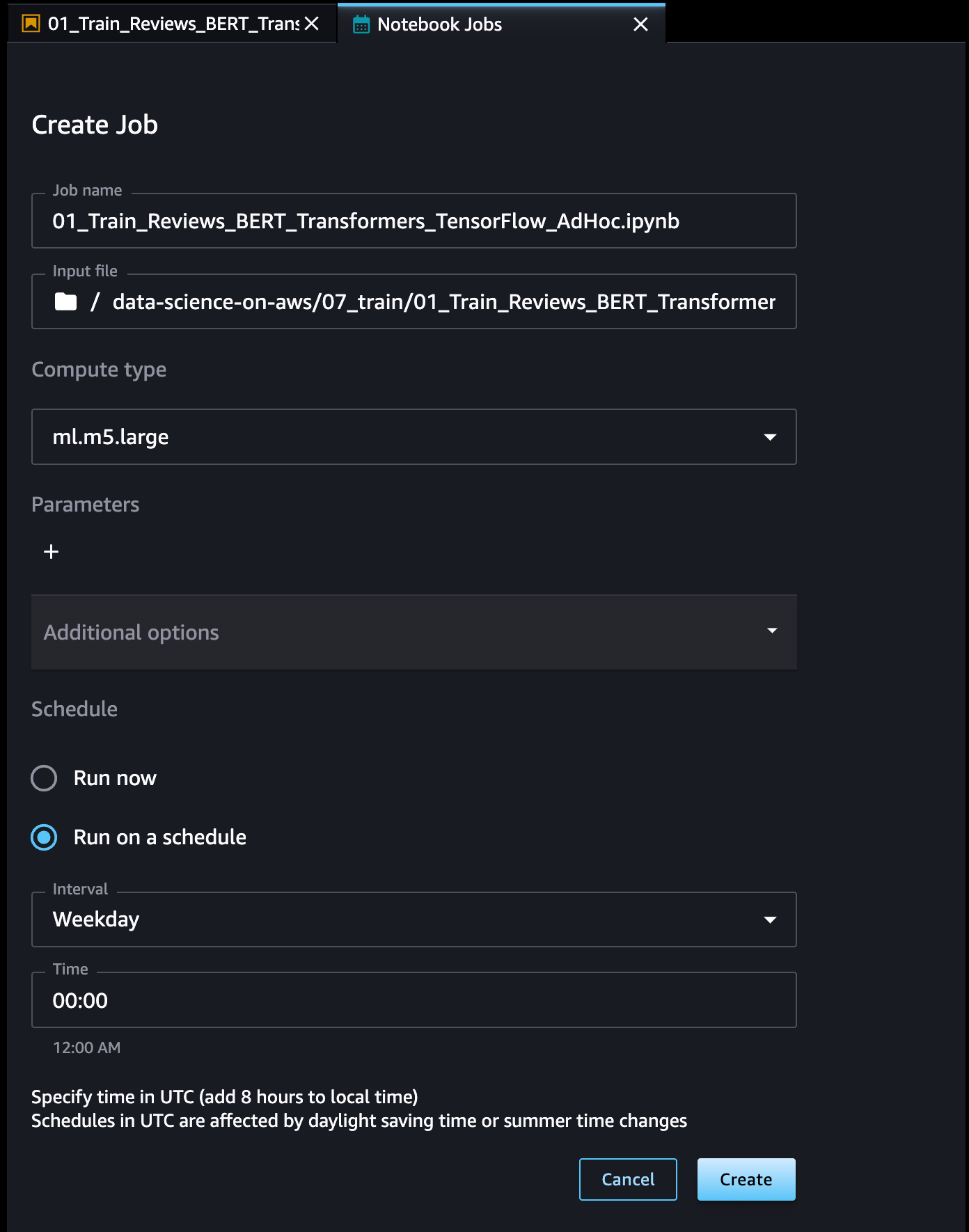
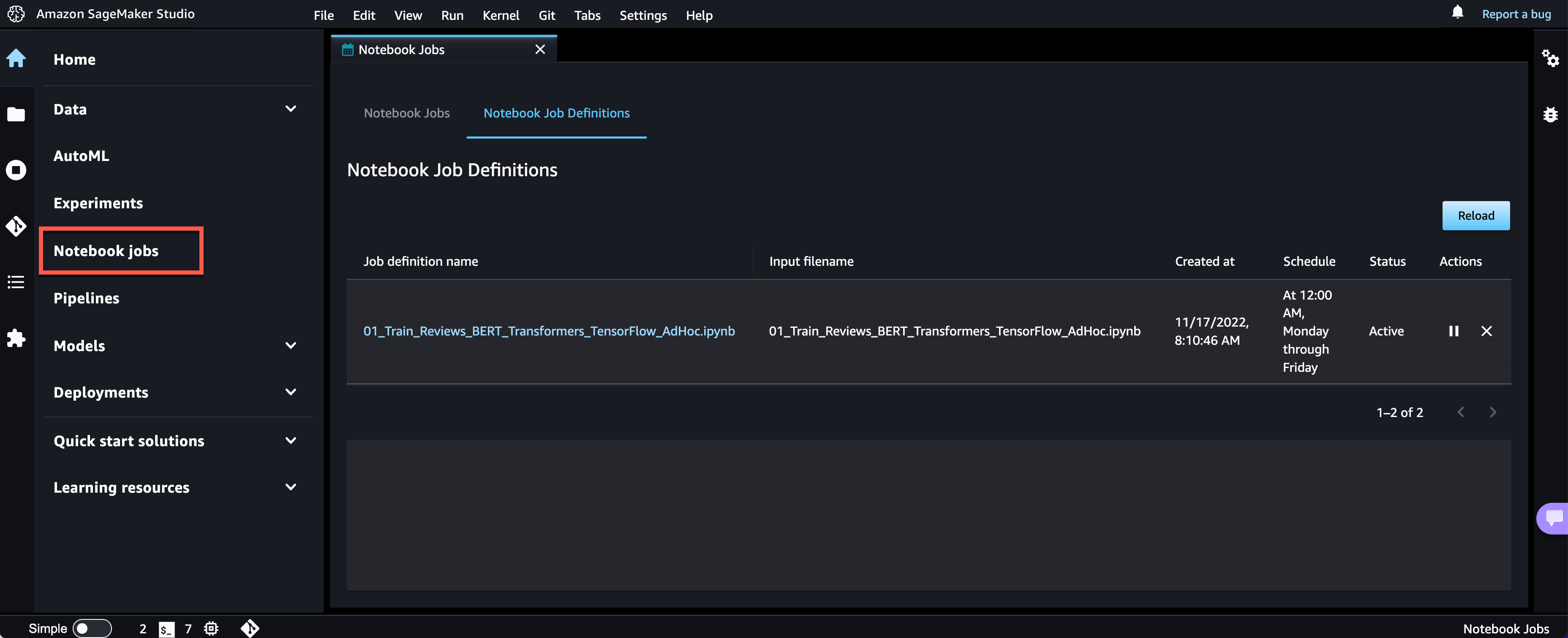
The Notebook Job has been created, and you may evaluate all Notebook Job Definitions within the UI.
Now Available
The new Amazon SageMaker Studio pocket book capabilities at the moment are accessible in all AWS Regions the place Amazon SageMaker Studio is obtainable apart from the AWS China Regions.
At launch, the built-in knowledge preparation functionality powered by SageMaker Data Wrangler is supported for SageMaker Studio notebooks and the next pocket book kernel photos:
- Python 3 (Data Science) with Python 3.7
- Python 3 (Data Science 2.0) with Python 3.8
- Python 3 (Data Science 3.0) with Python 3.10
- Spark Analytics 1.0 and a pair of.0
For extra data, go to Amazon SageMaker Notebooks.
— Antje
[ad_2]