
{kind=link}
[ad_1]
Last Updated on November 23, 2022
Structuring the information pipeline in a method that it may be effortlessly linked to your deep studying mannequin is a crucial side of any deep learning-based system. PyTorch packs every little thing to just do that.
While within the earlier tutorial, we used easy datasets, we’ll have to work with bigger datasets in actual world eventualities to be able to totally exploit the potential of deep studying and neural networks.
In this tutorial, you’ll learn to construct customized datasets in PyTorch. While the main target right here stays solely on the picture knowledge, ideas realized on this session could be utilized to any type of dataset equivalent to textual content or tabular datasets. So, right here you’ll be taught:
- How to work with pre-loaded picture datasets in PyTorch.
- How to use torchvision transforms on preloaded datasets.
- How to construct customized picture dataset class in PyTorch and apply numerous transforms on it.
Let’s get began.

Loading and Providing Datasets in PyTorch
Picture by Uriel SC. Some rights reserved.
This tutorial is in three components; they’re
- Preloaded Datasets in PyTorch
- Applying Torchvision Transforms on Image Datasets
- Building Custom Image Datasets
A wide range of preloaded datasets equivalent to CIFAR-10, MNIST, Fashion-MNIST, and many others. can be found within the PyTorch area library. You can import them from torchvision and carry out your experiments. Additionally, you’ll be able to benchmark your mannequin utilizing these datasets.
We’ll transfer on by importing Fashion-MNIST dataset from torchvision. The Fashion-MNIST dataset consists of 70,000 grayscale photos in 28×28 pixels, divided into ten courses, and every class incorporates 7,000 photos. There are 60,000 photos for coaching and 10,000 for testing.
Let’s begin by importing a couple of libraries we’ll use on this tutorial.
|
import torch from torch.utils.knowledge import Dataset from torchvision import datasets import torchvision.transforms as transforms import numpy as np import matplotlib.pyplot as plt torch.manual_seed(42) |
Let’s additionally outline a helper perform to show the pattern parts within the dataset utilizing matplotlib.
|
def imshow(sample_element, form = (28, 28)): plt.imshow(sample_element[0].numpy().reshape(form), cmap=“grey’) plt.title(‘Label=” + str(sample_element[1])) plt.present() |
Now, we’ll load the Fashion-MNIST dataset, utilizing the perform FashionMNIST() from torchvision.datasets. This perform takes some arguments:
root: specifies the trail the place we’re going to retailer our knowledge.prepare: signifies whether or not it’s prepare or check knowledge. We’ll set it to False as we don’t but want it for coaching.obtain: set toTrue, which means it’ll obtain the information from the web.rework: permits us to make use of any of the out there transforms that we have to apply on our dataset.
|
dataset = datasets.FashionMNIST( root=‘./knowledge’, prepare=False, obtain=True, rework=transforms.ToTensor() ) |
Let’s verify the category names together with their corresponding labels now we have within the Fashion-MNIST dataset.
|
courses = dataset.courses print(courses) |
It prints
|
[‘T-shirt/top’, ‘Trouser’, ‘Pullover’, ‘Dress’, ‘Coat’, ‘Sandal’, ‘Shirt’, ‘Sneaker’, ‘Bag’, ‘Ankle boot’] |
Similarly, for sophistication labels:
|
print(dataset.class_to_idx) |
It prints
|
{‘T-shirt/prime’: 0, ‘Trouser’: 1, ‘Pullover’: 2, ‘Dress’: 3, ‘Coat’: 4, ‘Sandal’: 5, ‘Shirt’: 6, ‘Sneaker’: 7, ‘Bag’: 8, ‘Ankle boot’: 9} |
Here is how we are able to visualize the primary component of the dataset with its corresponding label utilizing the helper perform outlined above.
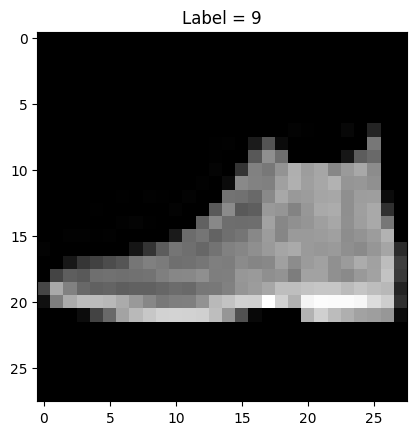
First component of the Fashion MNIST dataset
In many instances, we’ll have to use a number of transforms earlier than feeding the photographs to neural networks. For occasion, a number of occasions we’ll have to RandomCrop the photographs for knowledge augmentation.
As you’ll be able to see under, PyTorch allows us to select from a wide range of transforms.
This exhibits all out there rework features:
|
[‘AugMix’, ‘AutoAugment’, ‘AutoAugmentPolicy’, ‘CenterCrop’, ‘ColorJitter’, ‘Compose’, ‘ConvertImageDtype’, ‘ElasticTransform’, ‘FiveCrop’, ‘GaussianBlur’, ‘Grayscale’, ‘InterpolationMode’, ‘Lambda’, ‘LinearTransformation’, ‘Normalize’, ‘PILToTensor’, ‘Pad’, ‘RandAugment’, ‘RandomAdjustSharpness’, ‘RandomAffine’, ‘RandomApply’, ‘RandomAutocontrast’, ‘RandomChoice’, ‘RandomCrop’, ‘RandomEqualize’, ‘RandomErasing’, ‘RandomGrayscale’, ‘RandomHorizontalFlip’, ‘RandomInvert’, ‘RandomOrder’, ‘RandomPerspective’, ‘RandomPosterize’, ‘RandomResizedCrop’, ‘RandomRotation’, ‘RandomSolarize’, ‘RandomVerticalFlip’, ‘Resize’, ‘TenCrop’, ‘ToPILImage’, ‘ToTensor’, ‘TrivialAugmentWide’, ...] |
As an instance, let’s apply the RandomCrop rework to the Fashion-MNIST photos and convert them to a tensor. We can use rework.Compose to mix a number of transforms as we realized from the earlier tutorial.
|
randomcrop_totensor_transform = transforms.Compose([transforms.CenterCrop(16), transforms.ToTensor()]) dataset = datasets.FashionMNIST(root=‘./knowledge’, prepare=False, obtain=True, rework=randomcrop_totensor_transform) print(“form of the primary knowledge pattern: “, dataset[0][0].form) |
This prints
|
form of the primary knowledge pattern: torch.Size([1, 16, 16]) |
As you’ll be able to see picture has now been cropped to $16times 16$ pixels. Now, let’s plot the primary component of the dataset to see how they’ve been randomly cropped.
|
imshow(dataset[0], form=(16, 16)) |
This exhibits the next picture
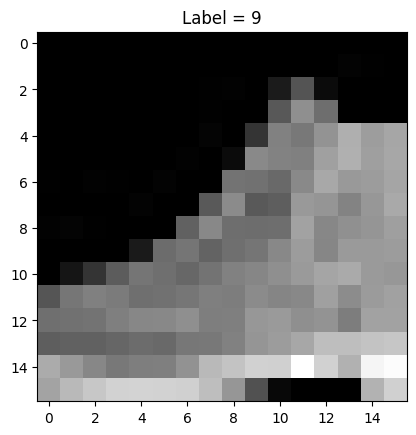
Cropped picture from Fashion MNIST dataset
Putting every little thing collectively, the entire code is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import torch from torch.utils.knowledge import Dataset from torchvision import datasets import torchvision.transforms as transforms import numpy as np import matplotlib.pyplot as plt torch.manual_seed(42)
def imshow(sample_element, form = (28, 28)): plt.imshow(sample_element[0].numpy().reshape(form), cmap=‘grey’) plt.title(‘Label=” + str(sample_element[1])) plt.present()
dataset = datasets.FashionMNIST( root=“./knowledge’, prepare=False, obtain=True, rework=transforms.ToTensor() )
courses = dataset.courses print(courses) print(dataset.class_to_idx)
imshow(dataset[0])
randomcrop_totensor_transform = transforms.Compose([transforms.CenterCrop(16), transforms.ToTensor()]) dataset = datasets.FashionMNIST( root=‘./knowledge’, prepare=False, obtain=True, rework=randomcrop_totensor_transform) )
print(“form of the primary knowledge pattern: “, dataset[0][0].form) imshow(dataset[0], form=(16, 16)) |
Until now now we have been discussing prebuilt datasets in PyTorch, however what if now we have to construct a customized dataset class for our picture dataset? While within the earlier tutorial we solely had a easy overview in regards to the elements of the Dataset class, right here we’ll construct a customized picture dataset class from scratch.
Firstly, within the constructor we outline the parameters of the category. The __init__ perform within the class instantiates the Dataset object. The listing the place photos and annotations are saved is initialized together with the transforms if we need to apply them on our dataset later. Here we assume now we have some photos in a listing construction like the next:
|
attface/ |– imagedata.csv |– s1/ | |– 1.png | |– 2.png | |– 3.png | … |– s2/ | |– 1.png | |– 2.png | |– 3.png | … … |
and the annotation is a CSV file like the next, positioned below the basis listing of the photographs (i.e., “attface” above):
|
s1/1.png,1 s1/2.png,1 s1/3.png,1 … s12/1.png,12 s12/2.png,12 s12/3.png,12 |
the place the primary column of the CSV knowledge is the trail to the picture and the second column is the label.
Similarly, we outline the __len__ perform within the class that returns the whole variety of samples in our picture dataset whereas the __getitem__ methodology reads and returns an information component from the dataset at a given index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import os import pandas as pd import numpy as np from torchvision.io import learn_picture
# creating object for our picture dataset class CustomDatasetForImages(Dataset): # defining constructor def __init__(self, annotations, listing, rework=None): # listing containing the photographs self.listing = listing annotations_file_dir = os.path.be a part of(self.listing, annotations) # loading the csv with information about photos self.labels = pd.read_csv(annotations_file_dir) # rework to be utilized on photos self.rework = rework
# Number of photos in dataset self.len = self.labels.form[0]
# getting the size def __len__(self): return len(self.labels)
# getting the information gadgets def __getitem__(self, idx): # defining the picture path image_path = os.path.be a part of(self.listing, self.labels.iloc[idx, 0]) # studying the photographs picture = read_image(image_path) # corresponding class labels of the photographs label = self.labels.iloc[idx, 1]
# apply the rework if not set to None if self.rework: picture = self.rework(picture)
# returning the picture and label return picture, label |
Now, we are able to create our dataset object and apply the transforms on it. We assume the picture knowledge are positioned below the listing named “attface” and the annotation CSV file is at “attface/imagedata.csv”. Then the dataset is created as follows:
|
listing = “attface” annotations = “imagedata.csv” custom_dataset = CustomDatasetForImages(annotations=annotations, listing=listing) |
Optionally, you’ll be able to add the rework perform to the dataset as effectively:
|
randomcrop_totensor_transform = transforms.RandomCrop(16) dataset = CustomDatasetForImages(annotations=annotations, listing=listing, rework=randomcrop_totensor_transform) |
You can use this practice picture dataset class to any of your datasets saved in your listing and apply the transforms to your necessities.
In this tutorial, you realized methods to work with picture datasets and transforms in PyTorch. Particularly, you realized:
- How to work with pre-loaded picture datasets in PyTorch.
- How to use torchvision transforms on pre-loaded datasets.
- How to construct customized picture dataset class in PyTorch and apply numerous transforms on it.
[ad_2]