
{kind=link}

Talking to your Network
Embarking on my journey as a community engineer almost 20 years in the past, I used to be among the many early adopters who acknowledged the transformative potential of community automation. In 2015, after attending Cisco Live in San Diego, I gained a brand new appreciation of the realm of the doable. Leveraging instruments like Ansible and Cisco pyATS, I started to streamline processes and improve efficiencies inside community operations, setting a basis for what would turn out to be a career-long pursuit of innovation. This preliminary foray into automation was not nearly simplifying repetitive duties; it was about envisioning a future the place networks might be extra resilient, adaptable, and clever. As I navigated by the complexities of community programs, these applied sciences grew to become indispensable allies, serving to me to not solely handle but in addition to anticipate the wants of more and more refined networks.
In latest years, my exploration has taken a pivotal flip with the appearance of generative AI, marking a brand new chapter within the story of community automation. The integration of synthetic intelligence into community operations has opened up unprecedented prospects, permitting for even larger ranges of effectivity, predictive evaluation, and decision-making capabilities. This weblog, accompanying the CiscoU Tutorial, delves into the cutting-edge intersection of AI and community automation, highlighting my experiences with Docker, LangChain, Streamlit, and, after all, Cisco pyATS. It’s a mirrored image on how the panorama of community engineering is being reshaped by AI, remodeling not simply how we handle networks, however how we envision their progress and potential within the digital age. Through this narrative, I intention to share insights and sensible data on harnessing the facility of AI to enhance the capabilities of community automation, providing a glimpse into the way forward for community operations.
In the spirit of contemporary software program deployment practices, the answer I architected is encapsulated inside Docker, a platform that packages an software and all its dependencies in a digital container that may run on any Linux server. This encapsulation ensures that it really works seamlessly in numerous computing environments. The coronary heart of this dockerized answer lies inside three key information: the Dockerfile, the startup script, and the docker-compose.yml.
The Dockerfile serves because the blueprint for constructing the applying’s Docker picture. It begins with a base picture, ubuntu:newest, making certain that each one the operations have a stable basis. From there, it outlines a sequence of instructions that put together the setting:
FROM ubuntu:newest
# Set the noninteractive frontend (helpful for automated builds) ARG DEBIAN_FRONTEND=noninteractive # A sequence of RUN instructions to put in crucial packages RUN apt-get replace && apt-get set up -y wget sudo ... # Python, pip, and important instruments are put in RUN apt-get set up python3 -y && apt-get set up python3-pip -y ... # Specific Python packages are put in, together with pyATS[full] RUN pip set up pyats[full] # Other utilities like dos2unix for script compatibility changes RUN sudo apt-get set up dos2unix -y # Installation of LangChain and associated packages RUN pip set up -U langchain-openai langchain-community ... # Install Streamlit, the online framework RUN pip set up streamlit
Each command is preceded by an echo assertion that prints out the motion being taken, which is extremely useful for debugging and understanding the construct course of because it occurs.
The startup.sh script is a straightforward but essential part that dictates what occurs when the Docker container begins:
cd streamlit_langchain_pyats streamlit run chat_with_routing_table.py
It navigates into the listing containing the Streamlit app and begins the app utilizing streamlit run. This is the command that really will get our app up and operating inside the container.
Lastly, the docker-compose.yml file orchestrates the deployment of our Dockerized software. It defines the companies, volumes, and networks to run our containerized software:
model: '3' companies: streamlit_langchain_pyats: picture: [Docker Hub image] container_name: streamlit_langchain_pyats restart: at all times construct: context: ./ dockerfile: ./Dockerfile ports: - "8501:8501"
This docker-compose.yml file makes it extremely simple to handle the applying lifecycle, from beginning and stopping to rebuilding the applying. It binds the host’s port 8501 to the container’s port 8501, which is the default port for Streamlit functions.
Together, these information create a sturdy framework that ensures the Streamlit software — enhanced with the AI capabilities of LangChain and the highly effective testing options of Cisco pyATS — is containerized, making deployment and scaling constant and environment friendly.
The journey into the realm of automated testing begins with the creation of the testbed.yaml file. This YAML file is not only a configuration file; it’s the cornerstone of our automated testing technique. It comprises all of the important details about the units in our community: hostnames, IP addresses, machine varieties, and credentials. But why is it so essential? The testbed.yaml file serves as the one supply of reality for the pyATS framework to grasp the community will probably be interacting with. It’s the map that guides the automation instruments to the appropriate units, making certain that our scripts don’t get misplaced within the huge sea of the community topology.
Sample testbed.yaml
--- units: cat8000v: alias: "Sandbox Router" sort: "router" os: "iosxe" platform: Cat8000v credentials: default: username: developer password: C1sco12345 connections: cli: protocol: ssh ip: 10.10.20.48 port: 22 arguments: connection_timeout: 360
With our testbed outlined, we then flip our consideration to the _job file. This is the conductor of our automation orchestra, the management file that orchestrates your entire testing course of. It hundreds the testbed and the Python take a look at script into the pyATS framework, setting the stage for the execution of our automated assessments. It tells pyATS not solely what units to check but in addition the best way to take a look at them, and in what order. This stage of management is indispensable for operating advanced take a look at sequences throughout a variety of community units.
Sample _job.py pyATS Job
import os from genie.testbed import load def fundamental(runtime): # ---------------- # Load the testbed # ---------------- if not runtime.testbed: # If no testbed is supplied, load the default one. # Load default location of Testbed testbedfile = os.path.be part of('testbed.yaml') testbed = load(testbedfile) else: # Use the one supplied testbed = runtime.testbed # Find the situation of the script in relation to the job file testscript = os.path.be part of(os.path.dirname(__file__), 'show_ip_route_langchain.py') # run script runtime.duties.run(testscript=testscript, testbed=testbed)
Then comes the pièce de résistance, the Python take a look at script — let’s name it capture_routing_table.py. This script embodies the intelligence of our automated testing course of. It’s the place we’ve distilled our community experience right into a sequence of instructions and parsers that work together with the Cisco IOS XE units to retrieve the routing desk info. But it doesn’t cease there; this script is designed to seize the output and elegantly rework it right into a JSON construction. Why JSON, you ask? Because JSON is the lingua franca for knowledge interchange, making the output from our units available for any variety of downstream functions or interfaces which may must eat it. In doing so, we’re not simply automating a job; we’re future-proofing it.
Excerpt from the pyATS script
@aetest.take a look at def get_raw_config(self): raw_json = self.machine.parse("present ip route") self.parsed_json = {"data": raw_json} @aetest.take a look at def create_file(self): with open('Show_IP_Route.json', 'w') as f: f.write(json.dumps(self.parsed_json, indent=4, sort_keys=True))
By focusing solely on pyATS on this section, we lay a robust basis for community automation. The testbed.yaml file ensures that our script is aware of the place to go, the _job file offers it the directions on what to do, and the capture_routing_table.py script does the heavy lifting, turning uncooked knowledge into structured data. This strategy streamlines our processes, making it doable to conduct complete, repeatable, and dependable community testing at scale.
Enhancing AI Conversational Models with RAG and Network JSON: A Guide
In the ever-evolving subject of AI, conversational fashions have come a good distance. From easy rule-based programs to superior neural networks, these fashions can now mimic human-like conversations with a exceptional diploma of fluency. However, regardless of the leaps in generative capabilities, AI can typically stumble, offering solutions which can be nonsensical or “hallucinated” — a time period used when AI produces info that isn’t grounded in actuality. One method to mitigate that is by integrating Retrieval-Augmented Generation (RAG) into the AI pipeline, particularly at the side of structured knowledge sources like community JSON.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is a cutting-edge approach in AI language processing that mixes one of the best of two worlds: the generative energy of fashions like GPT (Generative Pre-trained Transformer) and the precision of retrieval-based programs. Essentially, RAG enhances a language mannequin’s responses by first consulting a database of knowledge. The mannequin retrieves related paperwork or knowledge after which makes use of this context to tell its generated output.
The RAG Process
The course of usually includes a number of key steps:
- Retrieval: When the mannequin receives a question, it searches by a database to search out related info.
- Augmentation: The retrieved info is then fed into the generative mannequin as further context.
- Generation: Armed with this context, the mannequin generates a response that’s not solely fluent but in addition factually grounded within the retrieved knowledge.
The Role of Network JSON in RAG
Network JSON refers to structured knowledge within the JSON (JavaScript Object Notation) format, usually utilized in community communications. Integrating community JSON with RAG serves as a bridge between the generative mannequin and the huge quantities of structured knowledge accessible on networks. This integration will be essential for a number of causes:
- Data-Driven Responses: By pulling in community JSON knowledge, the AI can floor its responses in actual, up-to-date info, lowering the danger of “hallucinations.”
- Enhanced Accuracy: Access to a big selection of structured knowledge means the AI’s solutions will be extra correct and informative.
- Contextual Relevance: RAG can use community JSON to grasp the context higher, resulting in extra related and exact solutions.
Why Use RAG with Network JSON?
Let’s discover why one may select to make use of RAG in tandem with community JSON by a simplified instance utilizing Python code:
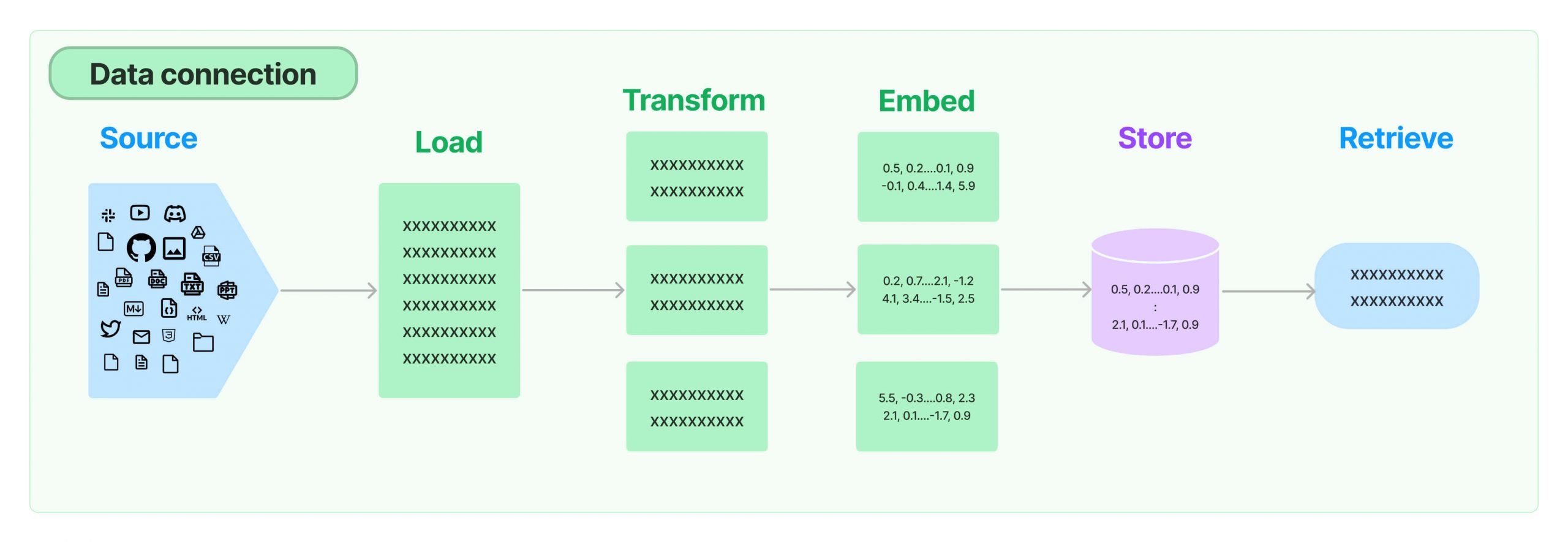
- Source and Load: The AI mannequin begins by sourcing knowledge, which might be community JSON information containing info from varied databases or the web.
- Transform: The knowledge may endure a change to make it appropriate for the AI to course of — for instance, splitting a big doc into manageable chunks.
- Embed: Next, the system converts the reworked knowledge into embeddings, that are numerical representations that encapsulate the semantic that means of the textual content.
- Store: These embeddings are then saved in a retrievable format.
- Retrieve: When a brand new question arrives, the AI makes use of RAG to retrieve essentially the most related embeddings to tell its response, thus making certain that the reply is grounded in factual knowledge.
By following these steps, the AI mannequin can drastically enhance the standard of the output, offering responses that aren’t solely coherent but in addition factually appropriate and extremely related to the consumer’s question.
class ChatWithRoutingTable: def __init__(self): self.conversation_history = [] self.load_text() self.split_into_chunks() self.store_in_chroma() self.setup_conversation_memory() self.setup_conversation_retrieval_chain() def load_text(self): self.loader = JSONLoader( file_path='Show_IP_Route.json', jq_schema=".data[]", text_content=False ) self.pages = self.loader.load_and_split() def split_into_chunks(self): # Create a textual content splitter self.text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=100, length_function=len, ) self.docs = self.text_splitter.split_documents(self.pages) def store_in_chroma(self): embeddings = OpenAIEmbeddings() self.vectordb = Chroma.from_documents(self.docs, embedding=embeddings) self.vectordb.persist() def setup_conversation_memory(self): self.reminiscence = ConversationBufferMemory(memory_key="chat_history", return_messages=True) def setup_conversation_retrieval_chain(self): self.qa = ConversationalRetrievalChain.from_llm(llm, self.vectordb.as_retriever(search_kwargs={"ok": 10}), reminiscence=self.reminiscence) def chat(self, query): # Format the consumer's immediate and add it to the dialog historical past user_prompt = f"User: {query}" self.conversation_history.append({"textual content": user_prompt, "sender": "consumer"}) # Format your entire dialog historical past for context, excluding the present immediate conversation_context = self.format_conversation_history(include_current=False) # Concatenate the present query with dialog context combined_input = f"Context: {conversation_context}nQuestion: {query}" # Generate a response utilizing the ConversationalRetrievalChain response = self.qa.invoke(combined_input) # Extract the reply from the response reply = response.get('reply', 'No reply discovered.') # Format the AI's response ai_response = f"Cisco IOS XE: {reply}" self.conversation_history.append({"textual content": ai_response, "sender": "bot"}) # Update the Streamlit session state by appending new historical past with each consumer immediate and AI response st.session_state['conversation_history'] += f"n{user_prompt}n{ai_response}" # Return the formatted AI response for fast show return ai_response
Conclusion
The integration of RAG with community JSON is a strong method to supercharge conversational AI. It results in extra correct, dependable, and contextually conscious interactions that customers can belief. By leveraging the huge quantities of accessible structured knowledge, AI fashions can step past the constraints of pure era and in the direction of a extra knowledgeable and clever conversational expertise.
Related sources
Share: