
{kind=link}

How a lot thought do you give to the place you retain your bits? Every day we produce extra knowledge, together with emails, texts, images, and social media posts. Though a lot of this content material is forgettable, daily we implicitly resolve to not do away with that knowledge. We maintain it someplace, be it in on a telephone, on a pc’s onerous drive, or within the cloud, the place it’s ultimately archived, normally on magnetic tape. Consider additional the numerous diversified gadgets and sensors now streaming knowledge onto the Web, and the vehicles, airplanes, and different autos that retailer journey knowledge for later use. All these billions of issues on the Internet of Things produce knowledge, and all that data additionally must be saved someplace.
Data is piling up exponentially, and the speed of data manufacturing is growing sooner than the storage density of tape, which can solely be capable to sustain with the deluge of information for a couple of extra years. The analysis agency Gartner
predicts that by 2030, the shortfall in enterprise storage capability alone might quantity to almost two-thirds of demand, or about 20 million petabytes. If we proceed down our present path, in coming a long time we would want not solely exponentially extra magnetic tape, disk drives, and flash reminiscence, however exponentially extra factories to provide these storage media, and exponentially extra knowledge facilities and warehouses to retailer them. Even if that is technically possible, it’s economically implausible.
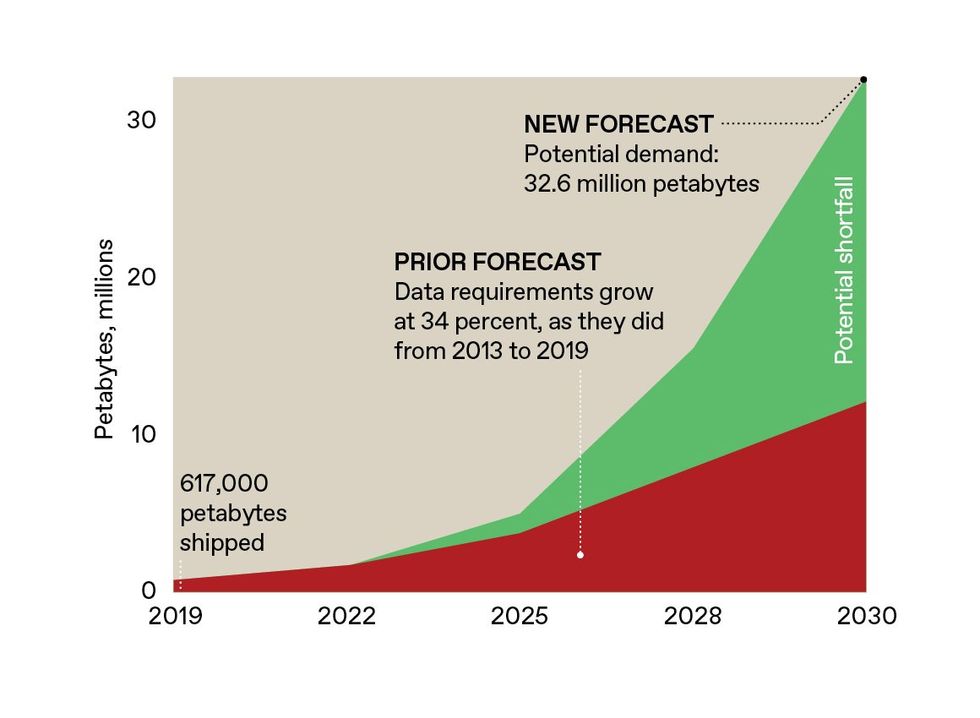 Prior projections for knowledge storage necessities estimated a worldwide want for about 12 million petabytes of capability by 2030. The analysis agency Gartner not too long ago issued new projections, elevating that estimate by 20 million petabytes. The world is just not on observe to provide sufficient of right this moment’s storage applied sciences to fill that hole.SOURCE: GARTNER
Prior projections for knowledge storage necessities estimated a worldwide want for about 12 million petabytes of capability by 2030. The analysis agency Gartner not too long ago issued new projections, elevating that estimate by 20 million petabytes. The world is just not on observe to provide sufficient of right this moment’s storage applied sciences to fill that hole.SOURCE: GARTNER
Fortunately, we’ve entry to an data storage expertise that’s low-cost, available, and steady at room temperature for millennia:
DNA, the fabric of genes. In a couple of years your onerous drive could also be stuffed with such squishy stuff.
Storing data in DNA is just not an advanced idea. Decades in the past, people discovered to sequence and synthesize DNA—that’s, to learn and write it. Each place in a single strand of DNA consists of certainly one of 4 nucleic acids, generally known as bases and represented as A, T, G, and C. In precept, every place within the DNA strand may very well be used to retailer two bits (A might symbolize 00, T may very well be 01, and so forth), however in apply, data is mostly saved at an efficient one bit—a 0 or a 1—per base.
Moreover, DNA exceeds by many occasions the storage density of magnetic tape or solid-state media. It has been calculated that each one the data on the Internet—which
one estimate places at about 120 zettabytes—may very well be saved in a quantity of DNA concerning the dimension of a sugar dice, or roughly a cubic centimeter. Achieving that density is theoretically attainable, however we might get by with a a lot decrease storage density. An efficient storage density of “one Internet per 1,000 cubic meters” would nonetheless end in one thing significantly smaller than a single knowledge heart housing tape right this moment.
 In 2018, researchers constructed this primary prototype of a machine that might write, retailer, and browse knowledge with DNA.MICROSOFT RESEARCH
In 2018, researchers constructed this primary prototype of a machine that might write, retailer, and browse knowledge with DNA.MICROSOFT RESEARCH
Most examples of DNA knowledge storage so far depend on chemically synthesizing quick stretches of DNA, as much as 200 or so bases. Standard chemical synthesis strategies are sufficient for demonstration tasks, and maybe early industrial efforts, that retailer modest quantities of music, pictures, textual content, and video, as much as maybe lots of of gigabytes. However, because the expertise matures, we might want to swap from chemical synthesis to a way more elegant, scalable, and sustainable answer: a semiconductor chip that makes use of enzymes to put in writing these sequences.
After the information has been written into the DNA, the molecule have to be saved secure someplace. Published examples embody drying small spots of DNA on
glass or paper, encasing the DNA in sugar or silica particles, or simply placing it in a take a look at tube. Reading may be achieved with any variety of industrial sequencing applied sciences.
Organizations around the globe are already taking the primary steps towards constructing a DNA drive that may each write and browse DNA knowledge. I’ve participated on this effort by way of a collaboration between
Microsoft and the Molecular Information Systems Lab of the Paul G. Allen School of Computer Science and Engineering on the University of Washington. We’ve made appreciable progress already, and we will see the way in which ahead.
How dangerous is the information storage drawback?
First, let’s have a look at the present state of storage. As talked about, magnetic tape storage has a scaling drawback. Making issues worse, tape degrades rapidly in comparison with the time scale on which we need to retailer data. To last more than a decade, tape have to be rigorously saved at cool temperatures and low humidity, which usually means the continual use of vitality for air con. And even when saved rigorously, tape must be changed periodically, so we’d like extra tape not only for all the brand new knowledge however to interchange the tape storing the previous knowledge.
To make sure, the storage density of magnetic tape has been
growing for many years, a development that may assist maintain our heads above the information flood for some time longer. But present practices are constructing fragility into the storage ecosystem. Backward compatibility is commonly assured for less than a era or two of the {hardware} used to learn that media, which may very well be just some years, requiring the lively upkeep of getting older {hardware} or ongoing knowledge migration. So all the information we’ve already saved digitally is prone to being misplaced to technological obsolescence.
The dialogue to this point has assumed that we’ll need to maintain all the information we produce, and that we’ll pay to take action. We ought to entertain the counterhypothesis: that we’ll as a substitute interact in systematic forgetting on a worldwide scale. This voluntary amnesia is likely to be achieved by not amassing as a lot knowledge concerning the world or by not saving all the information we accumulate, maybe solely preserving by-product calculations and conclusions. Or possibly not each particular person or group could have the identical entry to storage. If it turns into a restricted useful resource, knowledge storage might develop into a strategic expertise that allows an organization, or a rustic, to seize and course of all the information it needs, whereas opponents endure a storage deficit. But as but, there’s no signal that producers of information are prepared to lose any of it.
If we’re to keep away from both unintended or intentional forgetting, we have to give you a basically completely different answer for storing knowledge, one with the potential for exponential enhancements far past these anticipated for tape. DNA is by far essentially the most subtle, steady, and dense information-storage expertise people have ever come throughout or invented. Readable genomic
DNA has been recovered after having been frozen within the tundra for two million years. DNA is an intrinsic a part of life on this planet. As finest we will inform, nucleic acid–primarily based genetic data storage has endured on Earth for a minimum of 3 billion years, giving it an unassailable benefit as a backward- and forward-compatible knowledge storage medium.
What are the benefits of DNA knowledge storage?
To date, people have discovered to sequence and synthesize quick items of single-stranded DNA (ssDNA). However, in naturally occurring genomes, DNA is normally within the type of lengthy, double-stranded DNA (dsDNA). This dsDNA consists of two complementary sequences sure right into a construction that resembles a twisting ladder, the place sugar backbones type the aspect rails, and the paired bases—A with T, and G with C—type the steps of the ladder. Due to this construction, dsDNA is mostly extra strong than ssDNA.
Reading and writing DNA are each noisy molecular processes. To allow resiliency within the presence of this noise, digital data is encoded utilizing an algorithm that introduces redundancy and distributes data throughout many bases. Current algorithms encode data at a bodily density of 1 bit per 60 atoms (a pair of bases and the sugar backbones to which they’re hooked up).
 Edmon de Haro
Edmon de Haro
Synthesizing and sequencing DNA has develop into vital to the worldwide economic system, to human well being, and to understanding how organisms and ecosystems are altering round us. And we’re more likely to solely get higher at it over time. Indeed, each the fee and the per-instrument throughput of writing and studying DNA have been enhancing exponentially for many years, roughly maintaining with
Moore’s Law.
In biology labs around the globe, it’s now widespread apply to order chemically synthesized ssDNA from a industrial supplier; these molecules are delivered in lengths of as much as a number of hundred bases. It can be widespread to sequence DNA molecules which might be as much as hundreds of bases in size. In different phrases, we already convert digital data to and from DNA, however typically utilizing solely sequences that make sense by way of biology.
For DNA knowledge storage, although, we should write arbitrary sequences which might be for much longer, in all probability hundreds to tens of hundreds of bases. We’ll try this by adapting the naturally occurring organic course of and fusing it with semiconductor expertise to create high-density enter and output gadgets.
There is world curiosity in making a DNA drive. The members of the
DNA Data Storage Alliance, based in 2020, come from universities, corporations of all sizes, and authorities labs from around the globe. Funding companies within the United States, Europe, and Asia are investing within the expertise stack required to subject commercially related gadgets. Potential clients as various as movie studios, the U.S. National Archives, and Boeing have expressed curiosity in long-term knowledge storage in DNA.
Archival storage is likely to be the primary market to emerge, provided that it includes writing as soon as with solely rare studying, and but additionally calls for stability over many a long time, if not centuries. Storing data in DNA for that point span is definitely achievable. The difficult half is studying get the data into, and again out of, the molecule in an economically viable manner.
What are the R&D challenges of DNA knowledge storage?
The first soup-to-nuts automated prototype able to writing, storing, and studying DNA was constructed by my Microsoft and University of Washington colleagues in 2018.
The prototype built-in customary plumbing and chemistry to put in writing the DNA, with a sequencer from the corporate Oxford Nanopore Technologies to learn the DNA. This single-channel machine, which occupied a tabletop, had a throughput of 5 bytes over roughly 21 hours, with all however 40 minutes of that point consumed in writing “HELLO” into the DNA. It was a begin.
For a DNA drive to compete with right this moment’s archival tape drives, it should be capable to write about 2 gigabits per second, which at demonstrated DNA knowledge storage densities is about 2 billion bases per second. To put that in context, I estimate that the whole world marketplace for artificial DNA right this moment is not more than about 10 terabases per 12 months, which is the equal of about 300,000 bases per second over a 12 months. The complete DNA synthesis business would want to develop by roughly 4 orders of magnitude simply to compete with a single tape drive. Keeping up with the whole world demand for storage would require one other 8 orders of magnitude of enchancment by 2030.
Exponential progress in silicon-based expertise is how we wound up producing a lot knowledge. Similar exponential progress can be elementary within the transition to DNA storage.
But people have accomplished this sort of scaling up earlier than. Exponential progress in silicon-based expertise is how we wound up producing a lot knowledge. Similar exponential progress can be elementary within the transition to DNA storage.
My work with colleagues on the University of Washington and Microsoft has yielded many promising outcomes. This
collaboration has made progress on error-tolerant encoding of DNA, writing data into DNA sequences, stably storing that DNA, and recovering the data by studying the DNA. The staff has additionally explored the financial, environmental, and architectural benefits of DNA knowledge storage in comparison with options.
One of our objectives was to construct a semiconductor chip to allow high-density, high-throughput DNA synthesis.
That chip, which we accomplished in 2021, demonstrated that it’s attainable to digitally management electrochemical processes in tens of millions of 650-nanometer-diameter wells. While the chip itself was a technological step ahead, the chemical synthesis we used on that chip had a couple of drawbacks, regardless of being the business customary. The most important drawback is that it employs a unstable, corrosive, and poisonous natural solvent (acetonitrile), which no engineer needs anyplace close to the electronics of a working knowledge heart.
Moreover, primarily based on a sustainability evaluation of a theoretical DNA knowledge heart carried out my colleagues at Microsoft, I conclude that the amount of acetonitrile required for only one massive knowledge heart, by no means thoughts many massive knowledge facilities, would develop into logistically and economically prohibitive. To make sure, every knowledge heart may very well be geared up with a recycling facility to reuse the solvent, however that may be pricey.
Fortunately, there’s a completely different rising expertise for establishing DNA that doesn’t require such solvents, however as a substitute makes use of a benign salt answer. Companies like
DNA Script and Molecular Assemblies are commercializing automated methods that use enzymes to synthesize DNA. These strategies are changing conventional chemical DNA synthesis for some functions within the biotechnology business. The present era of methods use both easy plumbing or gentle to manage synthesis reactions. But it’s tough to examine how they are often scaled to attain a excessive sufficient throughput to allow a DNA data-storage machine working at even a fraction of two gigabases per second.
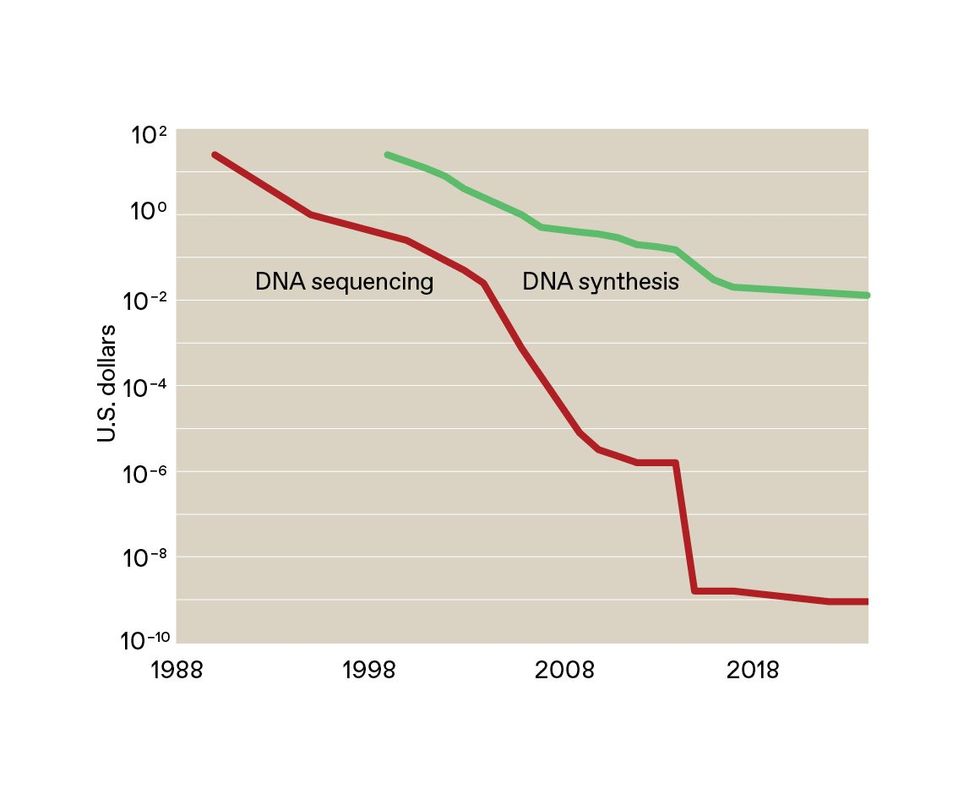 The value for sequencing DNA has plummeted from $25 per base in 1990 to lower than a millionth of a cent in 2024. The price of synthesizing lengthy items of double-stranded DNA can be declining, however synthesis must develop into less expensive for DNA knowledge storage to essentially take off.SOURCE: ROB CARLSON
The value for sequencing DNA has plummeted from $25 per base in 1990 to lower than a millionth of a cent in 2024. The price of synthesizing lengthy items of double-stranded DNA can be declining, however synthesis must develop into less expensive for DNA knowledge storage to essentially take off.SOURCE: ROB CARLSON
Still, the enzymes inside these methods are essential items of the DNA drive puzzle. Like DNA knowledge storage, the thought of utilizing enzymes to put in writing DNA is just not new, however industrial enzymatic synthesis turned possible solely within the final couple of years. Most such processes use an enzyme known as
terminal deoxynucleotidyl transferase, or TdT. Whereas most enzymes that function on DNA use one strand as a template to fill within the different strand, TdT can add arbitrary bases to single-stranded DNA.
Naturally occurring TdT is just not an awesome enzyme for synthesis, as a result of it incorporates the 4 bases with 4 completely different efficiencies, and it’s onerous to manage. Efforts over the previous decade have targeted on modifying the TdT and constructing it right into a system by which the enzyme may be higher managed.
Notably, these modifications to TdT have been made attainable by prior a long time of enchancment in studying and writing DNA, and the brand new modified enzymes at the moment are contributing to additional enhancements in writing, and thus modifying, genes and genomes. This phenomenon is identical sort of suggestions that drove a long time of exponential enchancment within the semiconductor business, by which corporations used extra succesful silicon chips to design the following era of silicon chips. Because that suggestions continues apace in each arenas, it received’t be lengthy earlier than we will mix the 2 applied sciences into one purposeful machine: a semiconductor chip that converts digital indicators into chemical states (for instance, adjustments in pH), and an enzymatic system that responds to these chemical states by including particular, particular person bases to construct a strand of artificial DNA.
The University of Washington and Microsoft staff, collaborating with the enzymatic synthesis firm
Ansa Biotechnologies, not too long ago took step one towards this machine. Using our high-density chip, we efficiently demonstrated electrochemical management of single-base enzymatic additions. The mission is now paused whereas the staff evaluates attainable subsequent steps.Nevertheless, even when this effort is just not resumed, somebody will make the expertise work. The path is comparatively clear; constructing a commercially related DNA drive is just a matter of money and time.
Looking past DNA knowledge storage
Eventually, the expertise for DNA storage will fully alter the economics of studying and writing every kind of genetic data. Even if the efficiency bar is about far beneath that of a tape drive, any industrial operation primarily based on studying and writing knowledge into DNA could have a throughput many occasions that of right this moment’s DNA synthesis business, with a vanishingly small price per base.
At the identical time, advances in DNA synthesis for DNA storage will enhance entry to DNA for different makes use of, notably within the biotechnology business, and can thereby broaden capabilities to reprogram life. Somewhere down the highway, when a DNA drive achieves a throughput of two gigabases per second (or 120 gigabases per minute), this field might synthesize the equal of about 20 full human genomes per minute. And when people mix our enhancing information of assemble a genome with entry to successfully free artificial DNA, we are going to enter a really completely different world.
The conversations we’ve right this moment about biosecurity, who has entry to DNA synthesis, and whether or not this expertise may be managed are barely scratching the floor of what’s to return. We’ll be capable to design microbes to provide chemical compounds and medicines, in addition to crops that may fend off pests or sequester minerals from the setting, similar to arsenic, carbon, or gold. At 2 gigabases per second, establishing organic countermeasures in opposition to novel pathogens will take a matter of minutes. But so too will establishing the genomes of novel pathogens. Indeed, this movement of data forwards and backwards between the digital and the organic will imply that each safety concern from the world of IT can even be launched into the world of biology. We should be vigilant about these prospects.
We are simply starting to learn to construct and program methods that combine digital logic and biochemistry. The future can be constructed not from DNA as we discover it, however from DNA as we are going to write it.
From Your Site Articles
Related Articles Around the Web