
{kind=link}


Nvidia is driving excessive for the time being. The firm has managed to extend the efficiency of its chips on AI duties 1000-fold during the last 10 years, it’s raking in cash, and it’s reportedly very onerous to get your arms on its latest AI-accelerating GPU, the H100.
How did Nvidia get right here? The firm’s chief scientist, Bill Dally, managed to sum all of it up in a single slide throughout his keynote tackle to the IEEE’s Hot Chips 2023 symposium in Silicon Valley on high-performance microprocessors final week. Moore’s Law was a surprisingly small a part of Nvidia’s magic and new quantity codecs a really massive half. Put all of it collectively and also you get what Dally referred to as Huang’s Law (for Nvidia CEO Jensen Huang).
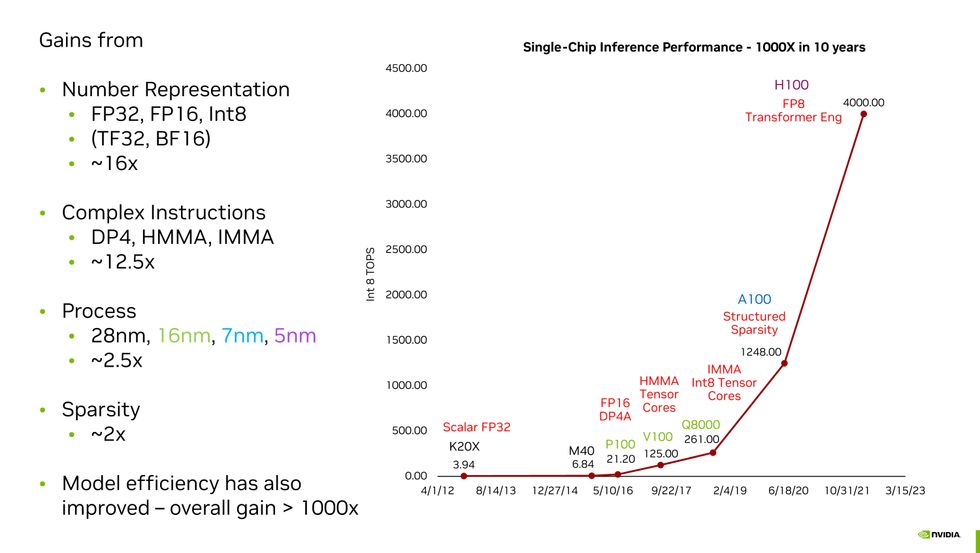
Nvidia chief scientist Bill Dally summed up how Nvidia has boosted the efficiency of its GPUs on AI duties 1000-fold over 10 years.Nvidia
Number Representation: 16x
“By and large, the biggest gain we got was from better number representation,” Dally informed engineers. These numbers characterize the important thing parameters of a neural community. One such parameter is weights—the energy of neuron-to-neuron connections in a mannequin—and one other is activations—what you multiply the sum of the weighted enter on the neuron to find out if it prompts, propagating info to the following layer. Before the P100, Nvidia GPUs represented these weights utilizing single precision floating level numerals. Defined by the IEEE 754 commonplace, these are 32 bits lengthy, with 23 bits representing a fraction, 8 bits performing primarily as an exponent utilized to the fraction, and one bit for the quantity’s signal.
But machine studying researchers had been rapidly studying that in lots of calculations, they may use much less exact numbers and their neural community would nonetheless give you solutions that had been simply as correct. The clear benefit of doing that is that the logic that does machine studying’s key computation—multiply and accumulate—will be made sooner, smaller, and extra environment friendly if they should course of fewer bits. (The power wanted for multiplication is proportional to the sq. of the variety of bits, Dally defined.) So, with the P100, Nvidia reduce that quantity in half, utilizing FP16. Google even got here up with its personal model referred to as bfloat16. (The distinction is within the relative variety of fraction bits, which provide you with precision, and exponent bits, which provide you with vary. Bfloat16 has the identical variety of vary bits as FP32, so it’s simpler to change forwards and backwards between the 2 codecs.)
Fast ahead to as we speak, and Nvidia’s main GPU, the H100, can do sure components of large transformer neural networks, like ChatGPT and different massive language fashions, utilizing 8-bit numbers. Nvidia did discover, nevertheless, that it’s not a one-size-fits-all answer. Nvidia’s Hopper GPU structure, for instance, really computes utilizing two totally different FP8 codecs, one with barely extra accuracy, the opposite with barely extra vary. Nvidia’s particular sauce is in figuring out when to make use of which format.
Dally and his crew have all types of fascinating concepts for squeezing extra AI out of even fewer bits. And it’s clear the floating level system isn’t ultimate. One of the principle issues is that floating level accuracy is fairly constant regardless of how massive or small the quantity. But the parameters for neural networks don’t make use of huge numbers, they’re clustered proper round 0. So, Nvidia’s R&D focus is discovering environment friendly methods to characterize numbers so they’re extra correct close to zero.
Complex Instructions: 12.5x
“The overhead of fetching and decoding an instruction is many times that of doing a simple arithmetic operation,” stated Dally. He identified one kind of multiplication, which had an overhead that consumed a full twenty occasions the 1.5 picojoules used to do the mathematics itself. By architecting its GPUs to carry out massive computations in a single instruction reasonably than a sequence of them, Nvidia made some enormous good points. There’s nonetheless overhead, Dally stated, however with complicated directions, it’s amortized over extra math. For instance, the complicated instruction integer matrix multiply and accumulate (IMMA) has an overhead that’s simply 16 p.c of the power value of the mathematics.
Moore’s Law: 2.5x
Maintaining the progress of Moore’s Law is the topic of billons and billions of {dollars} of funding, some very complicated engineering, and a bunch of worldwide angst. But it’s solely liable for a fraction of Nvidia’s GPU good points. The firm has persistently made use of essentially the most superior manufacturing expertise out there; the H100 is made with TSMC’s N5 (5 nanometer) course of and the chip foundry solely started preliminary manufacturing of its subsequent era N3 in late 2022.
Sparsity: 2x
After coaching, there are various neurons in a neural community that will as properly not have been there within the first place. For some networks “you can prune out half or more of the neurons and lose no accuracy,” stated Dally. Their weight values are zero, or actually near it; so they simply don’t contribute the output, and together with them in computations is a waste of time and power.
Making these networks “sparse“ to reduce the computational load is tricky business. But with the A100, the H100’s predecessor, Nvidia introduced what it calls structured sparsity. It’s hardware that can force two out of every four possible pruning events to happen, leading to a new smaller matrix computation.
“We’re not done with sparsity,” Dally stated. “We need to do something with activations and can have greater sparsity in weights as well.”