
{kind=link}

Reinforcement studying (RL) algorithms can study abilities to resolve decision-making duties like enjoying video games, enabling robots to select up objects, and even optimizing microchip designs. However, operating RL algorithms in the true world requires costly lively information assortment. Pre-training on various datasets has confirmed to allow data-efficient fine-tuning for particular person downstream duties in pure language processing (NLP) and imaginative and prescient issues. In the identical approach that BERT or GPT-3 fashions present general-purpose initialization for NLP, massive RL–pre-trained fashions may present general-purpose initialization for decision-making. So, we ask the query: Can we allow comparable pre-training to speed up RL strategies and create a general-purpose “backbone” for environment friendly RL throughout numerous duties?
In “Offline Q-learning on Diverse Multi-Task Data Both Scales and Generalizes”, to be revealed at ICLR 2023, we focus on how we scaled offline RL, which can be utilized to coach worth capabilities on beforehand collected static datasets, to offer such a common pre-training methodology. We show that Scaled Q-Learning utilizing a various dataset is adequate to study representations that facilitate speedy switch to novel duties and quick on-line studying on new variations of a job, enhancing considerably over current illustration studying approaches and even Transformer-based strategies that use a lot bigger fashions.
 |
Scaled Q-learning: Multi-task pre-training with conservative Q-learning
To present a general-purpose pre-training method, offline RL must be scalable, permitting us to pre-train on information throughout completely different duties and make the most of expressive neural community fashions to accumulate highly effective pre-trained backbones, specialised to particular person downstream duties. We primarily based our offline RL pre-training methodology on conservative Q-learning (CQL), a easy offline RL methodology that mixes normal Q-learning updates with an extra regularizer that minimizes the worth of unseen actions. With discrete actions, the CQL regularizer is equal to a regular cross-entropy loss, which is an easy, one-line modification on normal deep Q-learning. A number of essential design selections made this attainable:
- Neural community dimension: We discovered that multi-game Q-learning required massive neural community architectures. While prior strategies usually used relatively shallow convolutional networks, we discovered that fashions as massive as a ResNet 101 led to vital enhancements over smaller fashions.
- Neural community structure: To study pre-trained backbones which can be helpful for brand new video games, our remaining structure makes use of a shared neural community spine, with separate 1-layer heads outputting Q-values of every recreation. This design avoids interference between the video games throughout pre-training, whereas nonetheless offering sufficient information sharing to study a single shared illustration. Our shared imaginative and prescient spine additionally utilized a discovered place embedding (akin to Transformer fashions) to maintain monitor of spatial info within the recreation.
- Representational regularization: Recent work has noticed that Q-learning tends to undergo from representational collapse points, the place even massive neural networks can fail to study efficient representations. To counteract this difficulty, we leverage our prior work to normalize the final layer options of the shared a part of the Q-network. Additionally, we utilized a categorical distributional RL loss for Q-learning, which is understood to offer richer representations that enhance downstream job efficiency.
The multi-task Atari benchmark
We consider our method for scalable offline RL on a collection of Atari video games, the place the purpose is to coach a single RL agent to play a group of video games utilizing heterogeneous information from low-quality (i.e., suboptimal) gamers, after which use the ensuing community spine to shortly study new variations in pre-training video games or utterly new video games. Training a single coverage that may play many alternative Atari video games is troublesome sufficient even with normal on-line deep RL strategies, as every recreation requires a unique technique and completely different representations. In the offline setting, some prior works, similar to multi-game resolution transformers, proposed to dispense with RL completely, and as a substitute make the most of conditional imitation studying in an try and scale with massive neural community architectures, similar to transformers. However, on this work, we present that this type of multi-game pre-training may be performed successfully by way of RL by using CQL together with a couple of cautious design selections, which we describe beneath.
Scalability on coaching video games
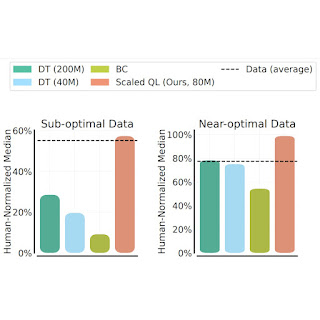
We consider the Scaled Q-Learning methodology’s efficiency and scalability utilizing two information compositions: (1) close to optimum information, consisting of all of the coaching information showing in replay buffers of earlier RL runs, and (2) low high quality information, consisting of information from the primary 20% of the trials within the replay buffer (i.e., solely information from extremely suboptimal insurance policies). In our outcomes beneath, we examine Scaled Q-Learning with an 80-million parameter mannequin to multi-game resolution transformers (DT) with both 40-million or 80-million parameter fashions, and a behavioral cloning (imitation studying) baseline (BC). We observe that Scaled Q-Learning is the one method that improves over the offline information, attaining about 80% of human normalized efficiency.
 |
Further, as proven beneath, Scaled Q-Learning improves when it comes to efficiency, but it surely additionally enjoys favorable scaling properties: simply as how the efficiency of pre-trained language and imaginative and prescient fashions improves as community sizes get greater, having fun with what is often referred as “power-law scaling”, we present that the efficiency of Scaled Q-learning enjoys comparable scaling properties. While this can be unsurprising, this type of scaling has been elusive in RL, with efficiency usually deteriorating with bigger mannequin sizes. This means that Scaled Q-Learning together with the above design decisions higher unlocks the power of offline RL to make the most of massive fashions.
 |
Fine-tuning to new video games and variations
To consider fine-tuning from this offline initialization, we take into account two settings: (1) fine-tuning to a brand new, completely unseen recreation with a small quantity of offline information from that recreation, similar to 2M transitions of gameplay, and (2) fine-tuning to a brand new variant of the video games with on-line interplay. The fine-tuning from offline gameplay information is illustrated beneath. Note that this situation is mostly extra favorable to imitation-style strategies, Decision Transformer and behavioral cloning, for the reason that offline information for the brand new video games is of comparatively high-quality. Nonetheless, we see that usually Scaled Q-learning improves over various approaches (80% on common), in addition to devoted illustration studying strategies, similar to MAE or CPC, which solely use the offline information to study visible representations somewhat than worth capabilities.
 |
In the web setting, we see even bigger enhancements from pre-training with Scaled Q-learning. In this case, illustration studying strategies like MAE yield minimal enchancment throughout on-line RL, whereas Scaled Q-Learning can efficiently combine prior information in regards to the pre-training video games to considerably enhance the ultimate rating after 20k on-line interplay steps.
These outcomes show that pre-training generalist worth perform backbones with multi-task offline RL can considerably enhance efficiency of RL on downstream duties, each in offline and on-line mode. Note that these fine-tuning duties are fairly troublesome: the assorted Atari video games, and even variants of the identical recreation, differ considerably in look and dynamics. For instance, the goal blocks in Breakout disappear within the variation of the sport as proven beneath, making management troublesome. However, the success of Scaled Q-learning, notably as in comparison with visible illustration studying methods, similar to MAE and CPC, means that the mannequin is in actual fact studying some illustration of the sport dynamics, somewhat than merely offering higher visible options.
 |
| Fine-tuning with on-line RL for variants of the sport Freeway, Hero, and Breakout. The new variant utilized in fine-tuning is proven within the backside row of every determine, the unique recreation seen in pre-training is within the prime row. Fine-tuning from Scaled Q-Learning considerably outperforms MAE (a visible illustration studying methodology) and studying from scratch with single-game DQN. |
Conclusion and takeaways
We introduced Scaled Q-Learning, a pre-training methodology for scaled offline RL that builds on the CQL algorithm, and demonstrated the way it permits environment friendly offline RL for multi-task coaching. This work made preliminary progress in the direction of enabling extra sensible real-world coaching of RL brokers as a substitute for pricey and sophisticated simulation-based pipelines or large-scale experiments. Perhaps in the long term, comparable work will result in usually succesful pre-trained RL brokers that develop broadly relevant exploration and interplay abilities from large-scale offline pre-training. Validating these outcomes on a broader vary of extra real looking duties, in domains similar to robotics (see some preliminary outcomes) and NLP, is a vital path for future analysis. Offline RL pre-training has a whole lot of potential, and we count on that we are going to see many advances on this space in future work.
Acknowledgements
This work was performed by Aviral Kumar, Rishabh Agarwal, Xinyang Geng, George Tucker, and Sergey Levine. Special because of Sherry Yang, Ofir Nachum, and Kuang-Huei Lee for assist with the multi-game resolution transformer codebase for analysis and the multi-game Atari benchmark, and Tom Small for illustrations and animation.