
{kind=link}
[ad_1]
Previously, we introduced the 1,000 languages initiative and the Universal Speech Model with the aim of creating speech and language applied sciences out there to billions of customers around the globe. Part of this dedication includes creating high-quality speech synthesis applied sciences, which construct upon tasks akin to VDTTS and AudioLM, for customers that talk many alternative languages.
 |
After creating a brand new mannequin, one should consider whether or not the speech it generates is correct and pure: the content material should be related to the duty, the pronunciation appropriate, the tone applicable, and there ought to be no acoustic artifacts akin to cracks or signal-correlated noise. Such analysis is a serious bottleneck within the improvement of multilingual speech techniques.
The hottest technique to guage the standard of speech synthesis fashions is human analysis: a text-to-speech (TTS) engineer produces just a few thousand utterances from the newest mannequin, sends them for human analysis, and receives outcomes just a few days later. This analysis section sometimes includes listening assessments, throughout which dozens of annotators hearken to the utterances one after the opposite to find out how pure they sound. While people are nonetheless unbeaten at detecting whether or not a bit of textual content sounds pure, this course of might be impractical — particularly within the early levels of analysis tasks, when engineers want speedy suggestions to check and restrategize their strategy. Human analysis is pricey, time consuming, and could also be restricted by the supply of raters for the languages of curiosity.
Another barrier to progress is that totally different tasks and establishments sometimes use numerous scores, platforms and protocols, which makes apples-to-apples comparisons inconceivable. In this regard, speech synthesis applied sciences lag behind textual content era, the place researchers have lengthy complemented human analysis with computerized metrics akin to BLEU or, extra lately, BLEURT.
In “SQuId: Measuring Speech Naturalness in Many Languages“, to be introduced at ICASSP 2023, we introduce SQuId (Speech Quality Identification), a 600M parameter regression mannequin that describes to what extent a bit of speech sounds pure. SQuId relies on mSLAM (a pre-trained speech-text mannequin developed by Google), fine-tuned on over 1,000,000 high quality scores throughout 42 languages and examined in 65. We exhibit how SQuId can be utilized to enhance human scores for analysis of many languages. This is the most important revealed effort of this kind so far.
Evaluating TTS with SQuId
The most important speculation behind SQuId is that coaching a regression mannequin on beforehand collected scores can present us with a low-cost technique for assessing the standard of a TTS mannequin. The mannequin can subsequently be a priceless addition to a TTS researcher’s analysis toolbox, offering a near-instant, albeit much less correct different to human analysis.
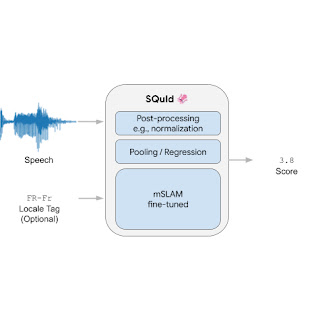
SQuId takes an utterance as enter and an non-compulsory locale tag (i.e., a localized variant of a language, akin to “Brazilian Portuguese” or “British English”). It returns a rating between 1 and 5 that signifies how pure the waveform sounds, with a better worth indicating a extra pure waveform.
Internally, the mannequin consists of three elements: (1) an encoder, (2) a pooling / regression layer, and (3) a completely linked layer. First, the encoder takes a spectrogram as enter and embeds it right into a smaller 2D matrix that accommodates 3,200 vectors of measurement 1,024, the place every vector encodes a time step. The pooling / regression layer aggregates the vectors, appends the locale tag, and feeds the outcome into a completely linked layer that returns a rating. Finally, we apply application-specific post-processing that rescales or normalizes the rating so it’s throughout the [1, 5] vary, which is widespread for naturalness human scores. We prepare the entire mannequin end-to-end with a regression loss.
The encoder is by far the most important and most essential piece of the mannequin. We used mSLAM, a pre-existing 600M-parameter Conformer pre-trained on each speech (51 languages) and textual content (101 languages).
 |
| The SQuId mannequin. |
To prepare and consider the mannequin, we created the SQuId corpus: a set of 1.9 million rated utterances throughout 66 languages, collected for over 2,000 analysis and product TTS tasks. The SQuId corpus covers a various array of techniques, together with concatenative and neural fashions, for a broad vary of use circumstances, akin to driving instructions and digital assistants. Manual inspection reveals that SQuId is uncovered to an unlimited vary of of TTS errors, akin to acoustic artifacts (e.g., cracks and pops), incorrect prosody (e.g., questions with out rising intonations in English), textual content normalization errors (e.g., verbalizing “7/7” as “seven divided by seven” quite than “July seventh”), or pronunciation errors (e.g., verbalizing “robust” as “toe”).
A typical difficulty that arises when coaching multilingual techniques is that the coaching information will not be uniformly out there for all of the languages of curiosity. SQuId was no exception. The following determine illustrates the dimensions of the corpus for every locale. We see that the distribution is basically dominated by US English.
 |
| Locale distribution within the SQuId dataset. |
How can we offer good efficiency for all languages when there are such variations? Inspired by earlier work on machine translation, in addition to previous work from the speech literature, we determined to coach one mannequin for all languages, quite than utilizing separate fashions for every language. The speculation is that if the mannequin is massive sufficient, then cross-locale switch can happen: the mannequin’s accuracy on every locale improves on account of collectively coaching on the others. As our experiments present, cross-locale proves to be a strong driver of efficiency.
Experimental outcomes
To perceive SQuId’s total efficiency, we examine it to a customized Big-SSL-MOS mannequin (described within the paper), a aggressive baseline impressed by MOS-SSL, a state-of-the-art TTS analysis system. Big-SSL-MOS relies on w2v-BERT and was educated on the VoiceMOS’22 Challenge dataset, the preferred dataset on the time of analysis. We experimented with a number of variants of the mannequin, and located that SQuId is as much as 50.0% extra correct.
 |
| SQuId versus state-of-the-art baselines. We measure settlement with human scores utilizing the Kendall Tau, the place a better worth represents higher accuracy. |
To perceive the influence of cross-locale switch, we run a collection of ablation research. We fluctuate the quantity of locales launched within the coaching set and measure the impact on SQuId’s accuracy. In English, which is already over-represented within the dataset, the impact of including locales is negligible.
 |
| SQuId’s efficiency on US English, utilizing 1, 8, and 42 locales throughout fine-tuning. |
However, cross-locale switch is far more efficient for many different locales:
 |
| SQuId’s efficiency on 4 chosen locales (Korean, French, Thai, and Tamil), utilizing 1, 8, and 42 locales throughout fine-tuning. For every locale, we additionally present the coaching set measurement. |
To push switch to its restrict, we held 24 locales out throughout coaching and used them for testing solely. Thus, we measure to what extent SQuId can take care of languages that it has by no means seen earlier than. The plot beneath exhibits that though the impact just isn’t uniform, cross-locale switch works.
 |
| SQuId’s efficiency on 4 “zero-shot” locales; utilizing 1, 8, and 42 locales throughout fine-tuning. |
When does cross-locale function, and the way? We current many extra ablations within the paper, and present that whereas language similarity performs a task (e.g., coaching on Brazilian Portuguese helps European Portuguese) it’s surprisingly removed from being the one issue that issues.
Conclusion and future work
We introduce SQuId, a 600M parameter regression mannequin that leverages the SQuId dataset and cross-locale studying to guage speech high quality and describe how pure it sounds. We exhibit that SQuId can complement human raters within the analysis of many languages. Future work consists of accuracy enhancements, increasing the vary of languages lined, and tackling new error sorts.
Acknowledgements
The creator of this publish is now a part of Google DeepMind. Many because of all authors of the paper: Ankur Bapna, Joshua Camp, Diana Mackinnon, Ankur P. Parikh, and Jason Riesa.
[ad_2]