
{kind=link}
[ad_1]
For good purpose there may be a variety of dialogue about multi-cloud amongst enterprise knowledge architects, CIO/CDOs, trade analysts and tech illuminati. But what’s multi-cloud? The time period suffers from ambiguity and misunderstanding that always plague rising expertise structure ideas.
We’re finest to grasp what multi-cloud is (and isn’t) within the body of the “pain” multi-cloud ought to resolve. The time period “multi-cloud” is mostly related to the proposition of escaping cloud vendor lock-in and the challenges that stem from lock-in. As we’ve written within the publish, Reframing Lock-in In the Era of Data-Driven Transformation, we subscribe to a “data-gravity” model of lock-in the place the principle “problem” is the problem in making knowledge accessible to the cloud functions, native and third-party knowledge companies supplied by cloud suppliers.
If at present’s model of cloud vendor lock-in is about knowledge – particularly making knowledge accessible to functions, and native and third-party knowledge companies within the cloud – then multi-cloud have to be a data-centric resolution that solves for the challenges of constructing knowledge accessible to the best functions and companies anytime and wherever.
Getting by with Multiple Cloud Solutions to Data Gravity
Common apply amongst organizations who’re already utilizing functions and companies in a number of clouds is to repeat and transfer knowledge in order that knowledge resides in every of the clouds wherein the group is internet hosting functions and utilizing companies.
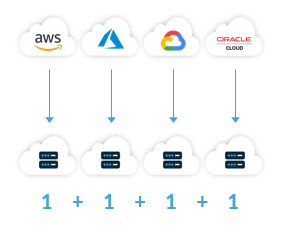
It could be a misnomer to seek advice from this “application-first” strategy to fixing knowledge gravity as multi-cloud. Rather, this strategy is finest understood as a a number of cloud strategy. Typical ache factors that stem from a a number of cloud strategy to creating knowledge accessible to functions and companies in a number of public clouds embody:
- Operational complexity
- Difficulty synchronizing knowledge throughout a number of locations
- Costs related to duplicating knowledge
- Uncontrollable egress and switch prices related to shifting knowledge out of/between clouds
- Security, compliance, privateness and governance challenges
- Inability to optimize the associated fee/efficiency trade-off for every workload
- Inability to leverage the perfect cloud sources or companies for every job’s necessities
All of those challenges can impede the progress of data-driven transformation initiatives leading to a enterprise ceding benefit to opponents with extra nimble knowledge architectures.
Although there exists software program that may facilitate the duplication and synchronization of information throughout a number of public clouds, it stays operationally troublesome, expensive and time consuming, and in some circumstances impractical to take action, significantly with giant knowledge units. This is a matter of physics; with the velocity of sunshine being a rate-limiting issue difficult by safety, governance, compliance and different components.
Multiple cloud approaches to fixing for knowledge gravity emerge from an antiquated application-level view of lock-in, the place the placement of the appliance determines the placement of the info. If we reframe our view of lock-in as a data-gravity downside, we’re liberated to re-imagine the answer; shifting from an application-first view to a data-first view.
Re-imagining Cloud Architecture with a Data-First Approach to Solving Data Gravity
What is required to resolve knowledge gravity is a data-first structure for the general public cloud. Such an answer would allow a one knowledge retailer to current knowledge to functions, and native and third-party knowledge companies in a number of clouds concurrently. In a data-first structure, every software and repair may learn and write to the identical knowledge set, concurrently. Such an structure requires a mix of cloud-adjacent knowledge and networking to current that knowledge into functions and companies in a number of clouds.
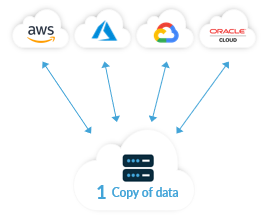
This data-first idea of the answer to data-gravity is actually multi-cloud by design with one copy of information hooked up to functions and companies in a number of public clouds (together with a number of availability zones) concurrently.
Putting Multi-Cloud in Context
It is especially important and pressing for IT organizations to resolve the challenges of information gravity within the period of data-driven transformation the place the shortcoming to make knowledge available can depart a company falling behind its opponents. Enabling data-driven transformation requires re-imaging cloud architecture with an answer that defies knowledge gravity by presenting knowledge to functions and companies in a number of public clouds slightly than shifting knowledge to the place functions and companies reside. In making this shift from application-centric cloud design ideas to data-first cloud design ideas, it turns into apparent with the advantage of hindsight {that a} true multi-cloud knowledge structure is an enabler of data-driven enterprise transformation.
By Derek Pilling
[ad_2]