
{kind=link}
[ad_1]
Language fashions are actually able to performing many new pure language processing (NLP) duties by studying directions, usually that they hadn’t seen earlier than. The potential to purpose on new duties is usually credited to coaching fashions on all kinds of distinctive directions, often known as “instruction tuning”, which was launched by FLAN and prolonged in T0, Super-Natural Instructions, MetaICL, and InstructGPT. However, a lot of the info that drives these advances stay unreleased to the broader analysis neighborhood.
In “The Flan Collection: Designing Data and Methods for Effective Instruction Tuning”, we carefully look at and launch a more recent and extra intensive publicly out there assortment of duties, templates, and strategies for instruction tuning to advance the neighborhood’s potential to research and enhance instruction-tuning strategies. This assortment was first used in Flan-T5 and Flan-PaLM, for which the latter achieved important enhancements over PaLM. We present that coaching a mannequin on this assortment yields improved efficiency over comparable public collections on all examined analysis benchmarks, e.g., a 3%+ enchancment on the 57 duties within the Massive Multitask Language Understanding (MMLU) analysis suite and eight% enchancment on LargeBench Hard (BBH). Analysis suggests the enhancements stem each from the bigger and extra numerous set of duties and from making use of a set of easy coaching and information augmentation strategies which might be low cost and straightforward to implement: mixing zero-shot, few-shot, and chain of thought prompts at coaching, enriching duties with enter inversion, and balancing process mixtures. Together, these strategies allow the ensuing language fashions to purpose extra competently over arbitrary duties, even these for which it hasn’t seen any fine-tuning examples. We hope making these findings and sources publicly out there will speed up analysis into extra highly effective and general-purpose language fashions.
Public instruction tuning information collections
Since 2020, a number of instruction tuning process collections have been launched in speedy succession, proven within the timeline under. Recent analysis has but to coalesce round a unified set of strategies, with completely different units of duties, mannequin sizes, and enter codecs all represented. This new assortment, referred to under as “Flan 2022”, combines prior collections from FLAN, P3/T0, and Natural Instructions with new dialog, program synthesis, and sophisticated reasoning duties.
 |
| A timeline of public instruction tuning collections, together with: UnifiedQA, CrossFit, Natural Instructions, FLAN, P3/T0, MetaICL, ExT5, Super-Natural Instructions, mT0, Unnatural Instructions, Self-Instruct, and OPT-IML Bench. The desk describes the discharge date, the duty assortment title, the mannequin title, the bottom mannequin(s) that have been finetuned with this assortment, the mannequin dimension, whether or not the ensuing mannequin is Public (inexperienced) or Not Public (crimson), whether or not they practice with zero-shot prompts (“ZS”), few-shot prompts (“FS”), chain-of-thought prompts (“CoT”) collectively (“+”) or individually (“/”), the variety of duties from this assortment in Flan 2022, the whole variety of examples, and a few notable strategies, associated to the collections, utilized in these works. Note that the variety of duties and examples differ underneath completely different assumptions and so are approximations. Counts for every are reported utilizing process definitions from the respective works. |
In addition to scaling to extra instructive coaching duties, The Flan Collection combines coaching with various kinds of input-output specs, together with simply directions (zero-shot prompting), directions with examples of the duty (few-shot prompting), and directions that ask for an evidence with the reply (chain of thought prompting). Except for InstructGPT, which leverages a group of proprietary information, Flan 2022 is the primary work to publicly reveal the robust advantages of blending these prompting settings collectively throughout coaching. Instead of a trade-off between the varied settings, mixing prompting settings throughout coaching improves all prompting settings at inference time, as proven under for each duties held-in and held-out from the set of fine-tuning duties.
 |
| Training collectively with zero-shot and few-shot immediate templates improves efficiency on each held-in and held-out duties. The stars point out the height efficiency in every setting. Red traces denote the zero-shot prompted analysis, lilac denotes few-shot prompted analysis. |
Evaluating instruction tuning strategies
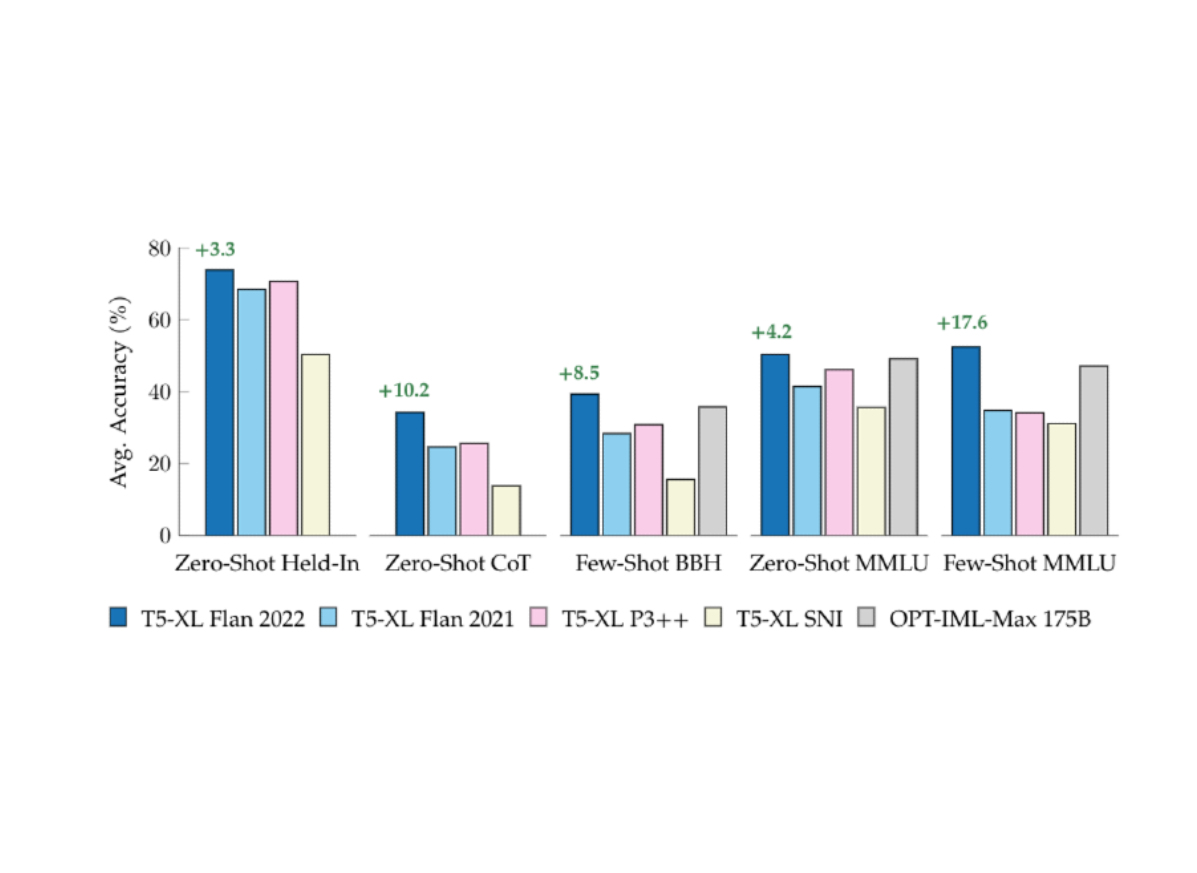
To perceive the general results of swapping one instruction tuning assortment for an additional, we fine-tune equivalently-sized T5 fashions on well-liked public instruction-tuning collections, together with Flan 2021, T0++, and Super-Natural Instructions. Each mannequin is then evaluated on a set of duties which might be already included in every of the instruction tuning collections, a set of 5 chain-of-thought duties, after which a set of 57 numerous duties from the MMLU benchmark, each with zero-shot and few-shot prompts. In every case, the brand new Flan 2022 mannequin, Flan-T5, outperforms these prior works, demonstrating a extra highly effective general-purpose NLP reasoner.
 |
| Comparing public instruction tuning collections on held-in, chain-of-thought, and held-out analysis suites, akin to LargeBench Hard and MMLU. All fashions besides OPT-IML-Max (175B) are educated by us, utilizing T5-XL with 3B parameters. Green textual content signifies enchancment over the following finest comparable T5-XL (3B) mannequin. |
Single process fine-tuning
In utilized settings, practitioners often deploy NLP fashions fine-tuned particularly for one goal process, the place coaching information is already out there. We look at this setting to know how Flan-T5 compares to T5 fashions as a place to begin for utilized practitioners. Three settings are in contrast: fine-tuning T5 instantly on the goal process, utilizing Flan-T5 with out additional fine-tuning on the goal process, and fine-tuning Flan-T5 on the goal process. For each held-in and held-out duties, fine-tuning Flan-T5 affords an enchancment over fine-tuning T5 instantly. In some situations, often the place coaching information is proscribed for a goal process, Flan-T5 with out additional fine-tuning outperforms T5 with direct fine-tuning.
 |
| Flan-T5 outperforms T5 on single-task fine-tuning. We examine single-task fine-tuned T5 (blue bars), single-task fine-tuned Flan-T5 (crimson), and Flan-T5 with none additional fine-tuning (beige). |
An extra good thing about utilizing Flan-T5 as a place to begin is that coaching is considerably quicker and cheaper, converging extra shortly than T5 fine-tuning, and often peaking at larger accuracies. This suggests much less task-specific coaching information could also be crucial to realize related or higher outcomes on a selected process.
 |
| Flan-T5 converges quicker than T5 on single-task fine-tuning, for every of 5 held-out duties from Flan fine-tuning. Flan-T5’s studying curve is indicated with the stable traces, and T5’s studying curve with the dashed line. All duties are held-out throughout Flan finetuning. |
There are important power effectivity advantages for the NLP neighborhood to undertake instruction-tuned fashions like Flan-T5 for single process fine-tuning, somewhat than typical non-instruction-tuned fashions. While pre-training and instruction fine-tuning are financially and computationally costly, they’re a one-time price, often amortized over hundreds of thousands of subsequent fine-tuning runs, which may grow to be extra pricey in mixture, for essentially the most outstanding fashions. Instruction-tuned fashions provide a promising resolution in considerably decreasing the quantity of fine-tuning steps wanted to realize the identical or higher efficiency.
Conclusion
The new Flan instruction tuning assortment unifies the preferred prior public collections and their strategies, whereas including new templates and easy enhancements like coaching with combined immediate settings. The ensuing methodology outperforms Flan, P3, and Super-Natural Instructions on held-in, chain of thought, MMLU, and BBH benchmarks by 3–17% throughout zero-shot and few-shot variants. Results counsel this new assortment serves as a extra performant place to begin for researchers and practitioners all in favour of each generalizing to new directions or fine-tuning on a single new process.
Acknowledgements
It was a privilege to work with Jason Wei, Barret Zoph, Le Hou, Hyung Won Chung, Tu Vu, Albert Webson, Denny Zhou, and Quoc V Le on this mission.
[ad_2]