
{kind=link}
[ad_1]
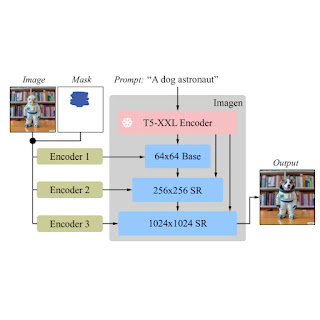
In the previous couple of years, text-to-image era analysis has seen an explosion of breakthroughs (notably, Imagen, Parti, DALL-E 2, and many others.) which have naturally permeated into associated subjects. In explicit, text-guided picture enhancing (TGIE) is a sensible process that includes enhancing generated and photographed visuals fairly than fully redoing them. Quick, automated, and controllable enhancing is a handy answer when recreating visuals could be time-consuming or infeasible (e.g., tweaking objects in trip images or perfecting fine-grained particulars on a cute pup generated from scratch). Further, TGIE represents a considerable alternative to enhance coaching of foundational fashions themselves. Multimodal fashions require numerous knowledge to coach correctly, and TGIE enhancing can allow the era and recombination of high-quality and scalable artificial knowledge that, maybe most significantly, can present strategies to optimize the distribution of coaching knowledge alongside any given axis.
In “Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting”, to be offered at CVPR 2023, we introduce Imagen Editor, a state-of-the-art answer for the duty of masked inpainting — i.e., when a consumer gives textual content directions alongside an overlay or “mask” (normally generated inside a drawing-type interface) indicating the realm of the picture they want to modify. We additionally introduce EditBench, a technique that gauges the standard of picture enhancing fashions. EditBench goes past the generally used coarse-grained “does this image match this text” strategies, and drills down to numerous kinds of attributes, objects, and scenes for a extra fine-grained understanding of mannequin efficiency. In explicit, it places robust emphasis on the faithfulness of image-text alignment with out shedding sight of picture high quality.
 |
| Given a picture, a user-defined masks, and a textual content immediate, Imagen Editor makes localized edits to the designated areas. The mannequin meaningfully incorporates the consumer’s intent and performs photorealistic edits. |
Imagen Editor
Imagen Editor is a diffusion-based mannequin fine-tuned on Imagen for enhancing. It targets improved representations of linguistic inputs, fine-grained management and high-fidelity outputs. Imagen Editor takes three inputs from the consumer: 1) the picture to be edited, 2) a binary masks to specify the edit area, and three) a textual content immediate — all three inputs information the output samples.
Imagen Editor relies on three core methods for high-quality text-guided picture inpainting. First, in contrast to prior inpainting fashions (e.g., Palette, Context Attention, Gated Convolution) that apply random field and stroke masks, Imagen Editor employs an object detector masking coverage with an object detector module that produces object masks throughout coaching. Object masks are based mostly on detected objects fairly than random patches and permit for extra principled alignment between edit textual content prompts and masked areas. Empirically, the tactic helps the mannequin stave off the prevalent subject of the textual content immediate being ignored when masked areas are small or solely partially cowl an object (e.g., CogView2).
 |
| Random masks (left) often seize background or intersect object boundaries, defining areas that may be plausibly inpainted simply from picture context alone. Object masks (proper) are more durable to inpaint from picture context alone, encouraging fashions to rely extra on textual content inputs throughout coaching. |
Next, throughout coaching and inference, Imagen Editor enhances excessive decision enhancing by conditioning on full decision (1024×1024 on this work), channel-wise concatenation of the enter picture and the masks (much like SR3, Palette, and GLIDE). For the bottom diffusion 64×64 mannequin and the 64×64→256×256 super-resolution fashions, we apply a parameterized downsampling convolution (e.g., convolution with a stride), which we empirically discover to be important for top constancy.
 |
| Imagen is fine-tuned for picture enhancing. All of the diffusion fashions, i.e., the bottom mannequin and super-resolution (SR) fashions, are conditioned on high-resolution 1024×1024 picture and masks inputs. To this finish, new convolutional picture encoders are launched. |
Finally, at inference we apply classifier-free steering (CFG) to bias samples to a specific conditioning, on this case, textual content prompts. CFG interpolates between the text-conditioned and unconditioned mannequin predictions to make sure robust alignment between the generated picture and the enter textual content immediate for text-guided picture inpainting. We comply with Imagen Video and use excessive steering weights with steering oscillation (a steering schedule that oscillates inside a price vary of steering weights). In the bottom mannequin (the stage-1 64x diffusion), the place making certain robust alignment with textual content is most crucial, we use a steering weight schedule that oscillates between 1 and 30. We observe that prime steering weights mixed with oscillating steering end in one of the best trade-off between pattern constancy and text-image alignment.
EditBench
The EditBench dataset for text-guided picture inpainting analysis incorporates 240 photographs, with 120 generated and 120 pure photographs. Generated photographs are synthesized by Parti and pure photographs are drawn from the Visual Genome and Open Images datasets. EditBench captures all kinds of language, picture sorts, and ranges of textual content immediate specificity (i.e., easy, wealthy, and full captions). Each instance consists of (1) a masked enter picture, (2) an enter textual content immediate, and (3) a high-quality output picture used as reference for computerized metrics. To present perception into the relative strengths and weaknesses of various fashions, EditBench prompts are designed to check fine-grained particulars alongside three classes: (1) attributes (e.g., materials, colour, form, measurement, rely); (2) object sorts (e.g., widespread, uncommon, textual content rendering); and (3) scenes (e.g., indoor, outside, sensible, or work). To perceive how totally different specs of prompts have an effect on mannequin efficiency, we offer three textual content immediate sorts: a single-attribute (Mask Simple) or a multi-attribute description of the masked object (Mask Rich) – or a complete picture description (Full Image). Mask Rich, particularly, probes the fashions’ capability to deal with advanced attribute binding and inclusion.
 |
| The full picture is used as a reference for profitable inpainting. The masks covers the goal object with a free-form, non-hinting form. We consider Mask Simple, Mask Rich and Full Image prompts, in step with typical text-to-image fashions. |
Due to the intrinsic weaknesses in present computerized analysis metrics (CLIPScore and CLIP-R-Precision) for TGIE, we maintain human analysis because the gold customary for EditBench. In the part beneath, we reveal how EditBench is utilized to mannequin analysis.
Evaluation
We consider the Imagen Editor mannequin — with object masking (IM) and with random masking (IM-RM) — towards comparable fashions, Stable Diffusion (SD) and DALL-E 2 (DL2). Imagen Editor outperforms these fashions by substantial margins throughout all EditBench analysis classes.
For Full Image prompts, single-image human analysis gives binary solutions to substantiate if the picture matches the caption. For Mask Simple prompts, single-image human analysis confirms if the article and attribute are correctly rendered, and certain appropriately (e.g., for a purple cat, a white cat on a purple desk could be an incorrect binding). Side-by-side human analysis makes use of Mask Rich prompts just for side-by-side comparisons between IM and every of the opposite three fashions (IM-RM, DL2, and SD), and signifies which picture matches with the caption higher for text-image alignment, and which picture is most sensible.
 |
| Human analysis. Full Image prompts elicit annotators’ general impression of text-image alignment; Mask Simple and Mask Rich examine for the right inclusion of explicit attributes, objects and attribute binding. |
For single-image human analysis, IM receives the best scores across-the-board (10–13% larger than the 2nd-highest performing mannequin). For the remainder, the efficiency order is IM-RM > DL2 > SD (with 3–6% distinction) apart from with Mask Simple, the place IM-RM falls 4-8% behind. As comparatively extra semantic content material is concerned in Full and Mask Rich, we conjecture IM-RM and IM are benefited by the upper performing T5 XXL textual content encoder.
 |
| Single-image human evaluations of text-guided picture inpainting on EditBench by immediate sort. For Mask Simple and Mask Rich prompts, text-image alignment is appropriate if the edited picture precisely contains each attribute and object specified within the immediate, together with the right attribute binding. Note that because of totally different analysis designs, Full vs. Mask-only prompts, outcomes are much less instantly comparable. |
EditBench focuses on fine-grained annotation, so we consider fashions for object and attribute sorts. For object sorts, IM leads in all classes, performing 10–11% higher than the 2nd-highest performing mannequin in widespread, uncommon, and text-rendering.
 |
| Single-image human evaluations on EditBench Mask Simple by object sort. As a cohort, fashions are higher at object rendering than text-rendering. |
For attribute sorts, IM is rated a lot larger (13–16%) than the 2nd highest performing mannequin, apart from in rely, the place DL2 is merely 1% behind.
 |
| Single-image human evaluations on EditBench Mask Simple by attribute sort. Object masking improves adherence to immediate attributes across-the-board (IM vs. IM-RM). |
Side-by-side in contrast with different fashions one-vs-one, IM leads in textual content alignment with a considerable margin, being most popular by annotators in comparison with SD, DL2, and IM-RM.
 |
| Side-by-side human analysis of picture realism & text-image alignment on EditBench Mask Rich prompts. For text-image alignment, Imagen Editor is most popular in all comparisons. |
Finally, we illustrate a consultant side-by-side comparative for all of the fashions. See the paper for extra examples.
 |
| Example mannequin outputs for Mask Simple vs. Mask Rich prompts. Object masking improves Imagen Editor’s fine-grained adherence to the immediate in comparison with the identical mannequin skilled with random masking. |
Conclusion
We offered Imagen Editor and EditBench, making important developments in text-guided picture inpainting and the analysis thereof. Imagen Editor is a text-guided picture inpainting fine-tuned from Imagen. EditBench is a complete systematic benchmark for text-guided picture inpainting, evaluating efficiency throughout a number of dimensions: attributes, objects, and scenes. Note that because of considerations in relation to accountable AI, we’re not releasing Imagen Editor to the general public. EditBench then again is launched in full for the advantage of the analysis group.
Acknowledgments
Thanks to Gunjan Baid, Nicole Brichtova, Sara Mahdavi, Kathy Meier-Hellstern, Zarana Parekh, Anusha Ramesh, Tris Warkentin, Austin Waters, and Vijay Vasudevan for his or her beneficiant assist. We give because of Igor Karpov, Isabel Kraus-Liang, Raghava Ram Pamidigantam, Mahesh Maddinala, and all of the nameless human annotators for his or her coordination to finish the human analysis duties. We are grateful to Huiwen Chang, Austin Tarango, and Douglas Eck for offering paper suggestions. Thanks to Erica Moreira and Victor Gomes for assist with useful resource coordination. Finally, because of the authors of DALL-E 2 for giving us permission to make use of their mannequin outputs for analysis functions.
[ad_2]