
{kind=link}
[ad_1]

Language fashions (LMs) are the driving pressure behind many latest breakthroughs in pure language processing. Models like T5, LaMDA, GPT-3, and PaLM have demonstrated spectacular efficiency on numerous language duties. While a number of components can contribute to enhancing the efficiency of LMs, some latest research counsel that scaling up the mannequin’s dimension is essential for revealing emergent capabilities. In different phrases, some cases could be solved by small fashions, whereas others appear to profit from elevated scale.
Despite latest efforts that enabled the environment friendly coaching of LMs over massive quantities of knowledge, skilled fashions can nonetheless be gradual and expensive for sensible use. When producing textual content at inference time, most autoregressive LMs output content material much like how we communicate and write (phrase after phrase), predicting every new phrase primarily based on the previous phrases. This course of can’t be parallelized since LMs want to finish the prediction of 1 phrase earlier than beginning to compute the subsequent one. Moreover, predicting every phrase requires vital computation given the mannequin’s billions of parameters.
In “Confident Adaptive Language Modeling”, introduced at NeurIPS 2022, we introduce a brand new methodology for accelerating the textual content technology of LMs by enhancing effectivity at inference time. Our methodology, named CALM, is motivated by the instinct that some subsequent phrase predictions are simpler than others. When writing a sentence, some continuations are trivial, whereas others may require extra effort. Current LMs dedicate the identical quantity of compute energy for all predictions. Instead, CALM dynamically distributes the computational effort throughout technology timesteps. By selectively allocating extra computational sources solely to more durable predictions, CALM generates textual content sooner whereas preserving output high quality.
Confident Adaptive Language Modeling
When attainable, CALM skips some compute effort for sure predictions. To display this, we use the favored encoder-decoder T5 structure. The encoder reads the enter textual content (e.g., a information article to summarize) and converts the textual content to dense representations. Then, the decoder outputs the abstract by predicting it phrase by phrase. Both the encoder and decoder embody a protracted sequence of Transformer layers. Each layer contains attention and feedforward modules with many matrix multiplications. These layers steadily modify the hidden illustration that’s in the end used for predicting the subsequent phrase.
Instead of ready for all decoder layers to finish, CALM makes an attempt to foretell the subsequent phrase earlier, after some intermediate layer. To determine whether or not to decide to a sure prediction or to postpone the prediction to a later layer, we measure the mannequin’s confidence in its intermediate prediction. The remainder of the computation is skipped solely when the mannequin is assured sufficient that the prediction received’t change. For quantifying what’s “confident enough”, we calibrate a threshold that statistically satisfies arbitrary high quality ensures over the total output sequence.
 |
| Text technology with a daily language mannequin (high) and with CALM (backside). CALM makes an attempt to make early predictions. Once assured sufficient (darker blue tones), it skips forward and saves time. |
Language Models with Early Exits
Enabling this early exit technique for LMs requires minimal modifications to the coaching and inference processes. During coaching, we encourage the mannequin to supply significant representations in intermediate layers. Instead of predicting solely utilizing the highest layer, our studying loss operate is a weighted common over the predictions of all layers, assigning increased weight to high layers. Our experiments display that this considerably improves the intermediate layer predictions whereas preserving the total mannequin’s efficiency. In one mannequin variant, we additionally embody a small early-exit classifier skilled to categorise if the native intermediate layer prediction is in line with the highest layer. We prepare this classifier in a second fast step the place we freeze the remainder of the mannequin.
Once the mannequin is skilled, we want a technique to permit early-exiting. First, we outline a neighborhood confidence measure for capturing the mannequin’s confidence in its intermediate prediction. We discover three confidence measures (described within the outcomes part beneath): (1) softmax response, taking the utmost predicted chance out of the softmax distribution; (2) state propagation, the cosine distance between the present hidden illustration and the one from the earlier layer; and (3) early-exit classifier, the output of a classifier particularly skilled for predicting native consistency. We discover the softmax response to be statistically robust whereas being easy and quick to compute. The different two options are lighter in floating level operations (FLOPS).
Another problem is that the self-attention of every layer relies on hidden-states from earlier phrases. If we exit early for some phrase predictions, these hidden-states could be lacking. Instead, we attend again to the hidden state of the final computed layer.
Finally, we arrange the native confidence threshold for exiting early. In the subsequent part, we describe our managed course of for locating good threshold values. As a primary step, we simplify this infinite search house by constructing on a helpful statement: errors which can be made originally of the technology course of are extra detrimental since they’ll have an effect on the entire following outputs. Therefore, we begin with the next (extra conservative) threshold, and steadily scale back it with time. We use a unfavorable exponent with user-defined temperature to manage this decay fee. We discover this permits higher management over the performance-efficiency tradeoff (the obtained speedup per high quality degree).
Reliably Controlling the Quality of the Accelerated Model
Early exit selections should be native; they should occur when predicting every phrase. In observe, nevertheless, the ultimate output needs to be globally constant or similar to the unique mannequin. For instance, if the unique full mannequin generated “the concert was wonderful and long”, one would settle for CALM switching the order of the adjectives and outputting “the concert was long and wonderful”. However, on the native degree, the phrase “wonderful” was changed with “long”. Therefore, the 2 outputs are globally constant, however embody some native inconsistencies. We construct on the Learn then Test (LTT) framework to attach native confidence-based selections to globally constant outputs.
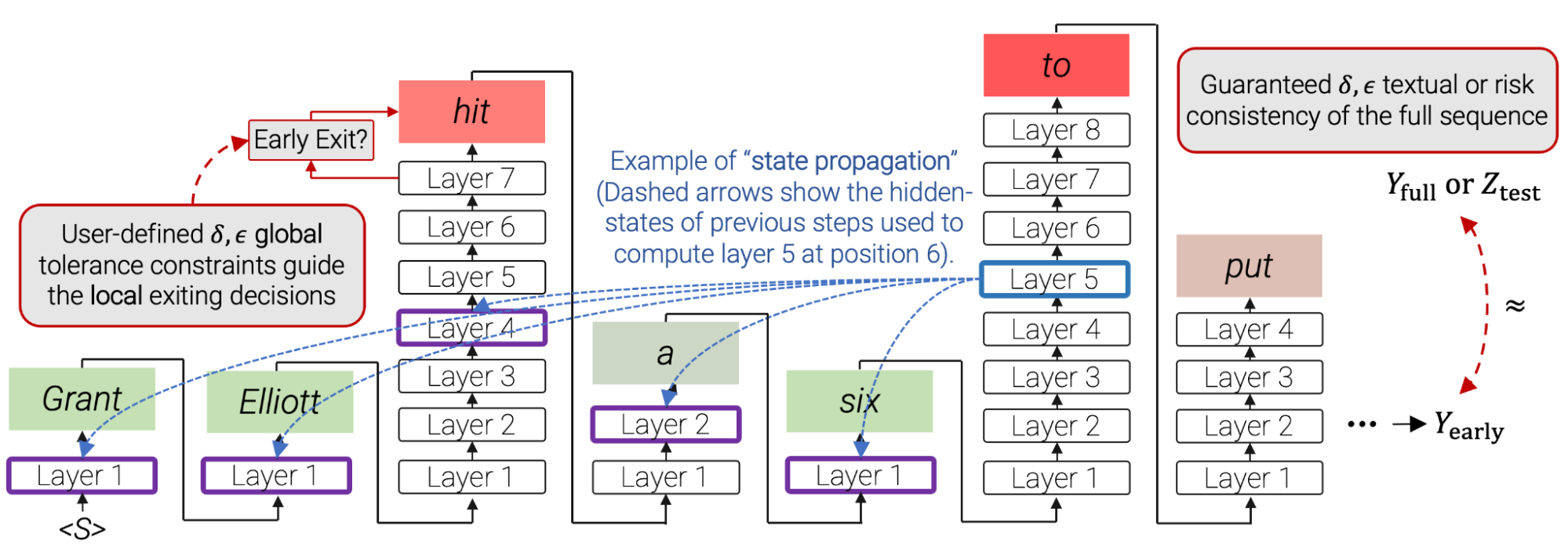 |
| In CALM, native per-timestep confidence thresholds for early exiting selections are derived, by way of LTT calibration, from user-defined consistency constraints over the total output textual content. Red packing containers point out that CALM used a lot of the decoder’s layers for that particular prediction. Green packing containers point out that CALM saved time through the use of only some Transformer layers. Full sentence proven within the final instance of this publish. |
First, we outline and formulate two forms of consistency constraints from which to decide on:
- Textual consistency: We sure the anticipated textual distance between the outputs of CALM and the outputs of the total mannequin. This doesn’t require any labeled information.
- Risk consistency: We sure the anticipated improve in loss that we permit for CALM in comparison with the total mannequin. This requires reference outputs in opposition to which to match.
For every of those constraints, we will set the tolerance that we permit and calibrate the boldness threshold to permit early exits whereas reliably satisfying our outlined constraint with an arbitrarily excessive chance.
CALM Saves Inference Time
We run experiments on three fashionable technology datasets: CNN/DM for summarization, WMT for machine translation, and SQuAD for query answering. We consider every of the three confidence measures (softmax response, state propagation and early-exit classifier) utilizing an 8-layer encoder-decoder mannequin. To consider world sequence-level efficiency, we use the usual Rouge-L, BLEU, and Token-F1 scores that measure distances in opposition to human-written references. We present that one can preserve full mannequin efficiency whereas utilizing solely a 3rd or half of the layers on common. CALM achieves this by dynamically distributing the compute effort throughout the prediction timesteps.
As an approximate higher sure, we additionally compute the predictions utilizing a native oracle confidence measure, which permits exiting on the first layer that results in the identical prediction as the highest one. On all three duties, the oracle measure can protect full mannequin efficiency when utilizing just one.5 decoder layers on common. In distinction to CALM, a static baseline makes use of the identical variety of layers for all predictions, requiring 3 to 7 layers (relying on the dataset) to protect its efficiency. This demonstrates why the dynamic allocation of compute effort is essential. Only a small fraction of the predictions require a lot of the mannequin’s complexity, whereas for others a lot much less ought to suffice.
 |
| Performance per activity in opposition to the typical variety of decoder layers used. |
Finally, we additionally discover that CALM permits sensible speedups. When benchmarking on TPUs, we saved virtually half of the compute time whereas sustaining the standard of the outputs.
 |
| Example of a generated information abstract. The high cell presents the reference human-written abstract. Below is the prediction of the total mannequin (8 layers) adopted by two completely different CALM output examples. The first CALM output is 2.9x sooner and the second output is 3.6x sooner than the total mannequin, benchmarked on TPUs. |
Conclusion
CALM permits sooner textual content technology with LMs, with out decreasing the standard of the output textual content. This is achieved by dynamically modifying the quantity of compute per technology timestep, permitting the mannequin to exit the computational sequence early when assured sufficient.
As language fashions proceed to develop in dimension, finding out tips on how to effectively use them turns into essential. CALM is orthogonal and could be mixed with many effectivity associated efforts, together with mannequin quantization, distillation, sparsity, efficient partitioning, and distributed management flows.
Acknowledgements
It was an honor and privilege to work on this with Adam Fisch, Ionel Gog, Seungyeon Kim, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, and Donald Metzler. We additionally thank Anselm Levskaya, Hyung Won Chung, Tao Wang, Paul Barham, Michael Isard, Orhan Firat, Carlos Riquelme, Aditya Menon, Zhifeng Chen, Sanjiv Kumar, and Jeff Dean for useful discussions and suggestions. Finally, we thank Tom Small for making ready the animation on this weblog publish.
[ad_2]