
{kind=link}
[ad_1]
The computational understanding of consumer interfaces (UI) is a key step in the direction of reaching clever UI behaviors. Previously, we investigated varied UI modeling duties, together with widget captioning, display summarization, and command grounding, that deal with numerous interplay situations comparable to automation and accessibility. We additionally demonstrated how machine studying can assist consumer expertise practitioners enhance UI high quality by diagnosing tappability confusion and offering insights for bettering UI design. These works together with these developed by others within the area have showcased how deep neural networks can doubtlessly remodel finish consumer experiences and the interplay design observe.
With these successes in addressing particular person UI duties, a pure query is whether or not we will receive foundational understandings of UIs that may profit particular UI duties. As our first try and reply this query, we developed a multi-task mannequin to handle a variety of UI duties concurrently. Although the work made some progress, just a few challenges stay. Previous UI fashions closely depend on UI view hierarchies — i.e., the construction or metadata of a cell UI display just like the Document Object Model for a webpage — that enable a mannequin to instantly purchase detailed info of UI objects on the display (e.g., their sorts, textual content content material and positions). This metadata has given earlier fashions benefits over their vision-only counterparts. However, view hierarchies will not be all the time accessible, and are sometimes corrupted with lacking object descriptions or misaligned construction info. As a outcome, regardless of the short-term good points from utilizing view hierarchies, it could finally hamper the mannequin efficiency and applicability. In addition, earlier fashions needed to cope with heterogeneous info throughout datasets and UI duties, which frequently resulted in complicated mannequin architectures that had been troublesome to scale or generalize throughout duties.
In “Spotlight: Mobile UI Understanding using Vision-Language Models with a Focus”, accepted for publication at ICLR 2023, we current a vision-only method that goals to attain normal UI understanding fully from uncooked pixels. We introduce a unified method to symbolize numerous UI duties, the knowledge for which will be universally represented by two core modalities: imaginative and prescient and language. The imaginative and prescient modality captures what an individual would see from a UI display, and the language modality will be pure language or any token sequences associated to the duty. We reveal that Spotlight considerably improves accuracy on a variety of UI duties, together with widget captioning, display summarization, command grounding and tappability prediction.
 |
Spotlight Model
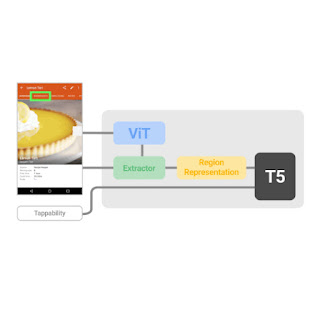
The Spotlight mannequin enter features a tuple of three objects: the screenshot, the area of curiosity on the display, and the textual content description of the duty. The output is a textual content description or response concerning the area of curiosity. This easy enter and output illustration of the mannequin is expressive to seize varied UI duties and permits scalable mannequin architectures. This mannequin design permits a spectrum of studying methods and setups, from task-specific fine-tuning, to multi-task studying and to few-shot studying. The Spotlight mannequin, as illustrated within the above determine, leverages current structure constructing blocks comparable to ViT and T5 which can be pre-trained within the high-resourced, normal vision-language area, which permits us to construct on high of the success of those normal area fashions.
Because UI duties are sometimes involved with a particular object or space on the display, which requires a mannequin to have the ability to give attention to the article or space of curiosity, we introduce a Focus Region Extractor to a vision-language mannequin that allows the mannequin to focus on the area in gentle of the display context.
In explicit, we design a Region Summarizer that acquires a latent illustration of a display area based mostly on ViT encodings by utilizing attention queries generated from the bounding field of the area (see paper for extra particulars). Specifically, every coordinate (a scalar worth, i.e., the left, high, proper or backside) of the bounding field, denoted as a yellow field on the screenshot, is first embedded by way of a multilayer perceptron (MLP) as a group of dense vectors, after which fed to a Transformer mannequin alongside their coordinate-type embedding. The dense vectors and their corresponding coordinate-type embeddings are shade coded to point their affiliation with every coordinate worth. Coordinate queries then attend to display encodings output by ViT by way of cross consideration, and the ultimate consideration output of the Transformer is used because the area illustration for the downstream decoding by T5.
 |
| A goal area on the display is summarized by utilizing its bounding field to question into display encodings from ViT by way of attentional mechanisms. |
Results
We pre-train the Spotlight mannequin utilizing two unlabeled datasets (an inside dataset based mostly on C4 corpus and an inside cell dataset) with 2.5 million cell UI screens and 80 million internet pages. We then individually fine-tune the pre-trained mannequin for every of the 4 downstream duties (captioning, summarization, grounding, and tappability). For widget captioning and display summarization duties, we report CIDEr scores, which measure how comparable a mannequin textual content description is to a set of references created by human raters. For command grounding, we report accuracy that measures the proportion of occasions the mannequin efficiently locates a goal object in response to a consumer command. For tappability prediction, we report F1 scores that measure the mannequin’s means to inform tappable objects from untappable ones.
In this experiment, we examine Spotlight with a number of benchmark fashions. Widget Caption makes use of view hierarchy and the picture of every UI object to generate a textual content description for the article. Similarly, Screen2Words makes use of view hierarchy and the screenshot in addition to auxiliary options (e.g., app description) to generate a abstract for the display. In the identical vein, VUT combines screenshots and think about hierarchies for performing a number of duties. Finally, the unique Tappability mannequin leverages object metadata from view hierarchy and the screenshot to foretell object tappability. Taperception, a follow-up mannequin of Tappability, makes use of a vision-only tappability prediction method. We study two Spotlight mannequin variants with respect to the dimensions of its ViT constructing block, together with B/16 and L/16. Spotlight drastically exceeded the state-of-the-art throughout 4 UI modeling duties.
| Model | Captioning | Summarization | Grounding | Tappability | |||||||||||
| Baselines |
Widget Caption | 97 | – | – | – | ||||||||||
| Screen2Words | – | 61.3 | – | – | |||||||||||
| VUT | 99.3 | 65.6 | 82.1 | – | |||||||||||
| Taperception | – | – | – | 85.5 | |||||||||||
| Tappability | – | – | – | 87.9 | |||||||||||
| Spotlight | B/16 | 136.6 | 103.5 | 95.7 | 86.9 | ||||||||||
| L/16 | 141.8 | 106.7 | 95.8 | 88.4 |
We then pursue a more difficult setup the place we ask the mannequin to study a number of duties concurrently as a result of a multi-task mannequin can considerably cut back mannequin footprint. As proven within the desk beneath, the experiments confirmed that our mannequin nonetheless performs competitively.
| Model | Captioning | Summarization | Grounding | Tappability | ||||||||||
| VUT multi-task | 99.3 | 65.1 | 80.8 | – | ||||||||||
| Spotlight B/16 | 140 | 102.7 | 90.8 | 89.4 | ||||||||||
| Spotlight L/16 | 141.3 | 99.2 | 94.2 | 89.5 |
To perceive how the Region Summarizer allows Spotlight to give attention to a goal area and related areas on the display, we analyze the consideration weights (which point out the place the mannequin consideration is on the screenshot) for each widget captioning and display summarization duties. In the determine beneath, for the widget captioning job, the mannequin predicts “select Chelsea team” for the checkbox on the left aspect, highlighted with a pink bounding field. We can see from its consideration heatmap (which illustrates the distribution of consideration weights) on the fitting that the mannequin learns to take care of not solely the goal area of the verify field, but additionally the textual content “Chelsea” on the far left to generate the caption. For the screen summarization example, the model predicts “page displaying the tutorial of a learning app” given the screenshot on the left. In this instance, the goal area is your complete display, and the mannequin learns to take care of essential elements on the display for summarization.
 |
| For the widget captioning job, the eye heatmap exhibits the mannequin attending to the checkbox, i.e., the goal object, and the textual content label on its left when producing a caption for the article. The pink bounding field within the determine is for illustration functions. |
 |
| For the display summarization job that the goal area encloses your complete display, the eye heatmap exhibits the mannequin attending to numerous places on the display that contribute to producing the abstract. |
Conclusion
We reveal that Spotlight outperforms earlier strategies that use each screenshots and think about hierarchies because the enter, and establishes state-of-the-art outcomes on a number of consultant UI duties. These duties vary from accessibility, automation to interplay design and analysis. Our vision-only method for cell UI understanding alleviates the necessity to use view hierarchy, permits the structure to simply scale and advantages from the success of huge vision-language fashions pre-trained for the overall area. Compared to latest massive vision-language mannequin efforts comparable to Flamingo and PaLI, Spotlight is comparatively small and our experiments present the pattern that bigger fashions yield higher efficiency. Spotlight will be simply utilized to extra UI duties and doubtlessly advance the fronts of many interplay and consumer expertise duties.
Acknowledgment
We thank Mandar Joshi and Tao Li for his or her assist in processing the online pre-training dataset, and Chin-Yi Cheng and Forrest Huang for his or her suggestions for proofreading the paper. Thanks to Tom Small for his assist in creating animated figures on this put up.
[ad_2]