
{kind=link}
[ad_1]
As an information scientist, top-of-the-line issues about working with DataRobotic clients is the sheer number of extremely attention-grabbing questions that come up. Recently, a potential buyer requested me how I reconcile the truth that DataRobotic has a number of very profitable funding banks utilizing DataRobotic to boost the P&L of their buying and selling companies with my feedback that machine studying fashions aren’t all the time nice at predicting monetary asset costs. Peek into our dialog to study when machine studying does—and doesn’t—work nicely in monetary markets use circumstances.
Why is machine studying capable of carry out nicely in excessive frequency buying and selling purposes, however is so unhealthy at predicting asset costs longer-term?
While there have been some successes within the trade utilizing machine studying for worth prediction, they’ve been few and much between. As a rule of thumb, the shorter the prediction time horizon, the higher the chances of success.
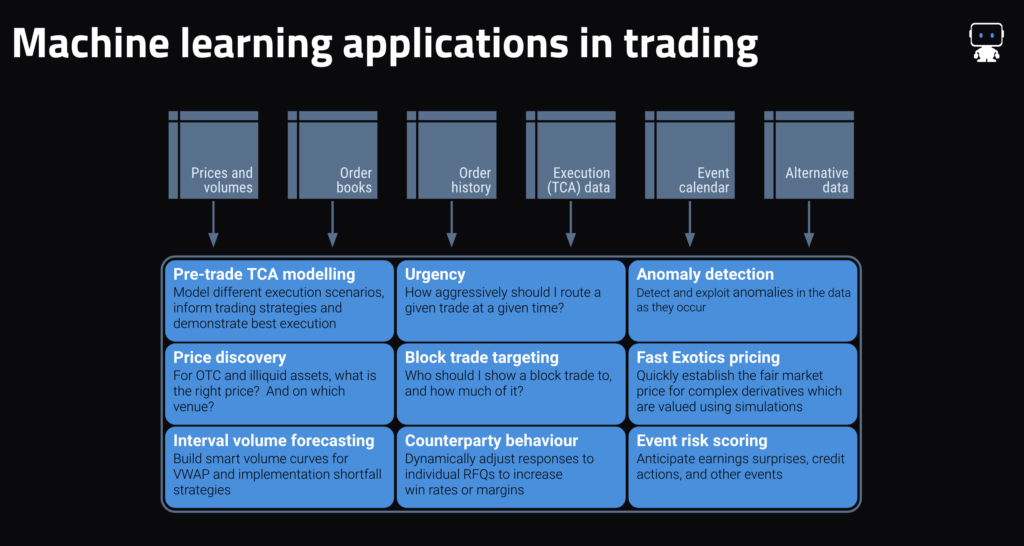
Generally talking, market making use circumstances that DataRobotic (and different machine studying approaches) excel at share a number of of the next traits:
- For ahead worth prediction: a really brief prediction horizon (usually inside the subsequent one to 10 seconds), the provision of fine order e book information, and an acknowledgment that even a mannequin that’s 55%–60% correct is helpful—it’s in the end a proportion recreation.
- For worth discovery (e.g., establishing an applicable worth illiquid securities, predicting the place liquidity can be situated, and figuring out applicable hedge ratios) in addition to extra typically: the existence of fine historic commerce information on the property to be priced (e.g., TRACE, Asian bond market reporting, ECNs’ commerce historical past) in addition to a transparent set of extra liquid property which can be utilized as predictors (e.g., extra liquid credit, bond futures, swaps markets, and many others.).
- For counterparty habits prediction: some type of structured information which comprises not solely received trades but additionally unsuccessful requests/responses.
- Across purposes: an data edge, as an example from commanding a big share of the stream in that asset class, or from having buyer habits information that can be utilized.
Areas the place any type of machine studying will wrestle are usually characterised by a number of of those points:
- Rapidly altering regimes, behaviors and drivers: a key motive why longer-term predictions are so laborious. We fairly often discover that the important thing mannequin drivers change very recurrently in most monetary markets, with a variable that’s a helpful indicator for one week or month having little data content material within the subsequent. Even in profitable purposes, fashions are re-trained and re-deployed very recurrently (usually a minimum of weekly).
- Infrequent information: a basic instance right here is month-to-month or much less frequent information. In such circumstances, the habits being modeled usually adjustments so typically that by the point that sufficient coaching information for machine studying has accrued (24 months or above), the market is in a special regime. For what it’s value, a number of of our clients have certainly had some success at, as an example, inventory choice utilizing predictions on a one-month horizon, however they’re (understandably) not telling us how they’re doing it.
- Sparse information: the place there’s inadequate information accessible to get a superb image of the market in combination, resembling sure OTC markets the place there aren’t any good ECNs.
- An absence of predictors: basically, information on previous habits of the variable being predicted (e.g., costs) isn’t sufficient. You additionally want information describing the drivers of that variable (e.g., order books, flows, expectations, positioning). Past efficiency is just not indicative of future outcomes… .
- Limited historical past of comparable regimes: as a result of machine studying fashions are all about recognising patterns in historic information, new markets or property might be very troublesome for ML fashions. This is thought in academia because the “cold start problem.” There are numerous methods to take care of it, however none of them are excellent.
- Not truly being a machine studying drawback: Value-at-Risk modeling is the basic instance right here—VaR isn’t a prediction of something, it’s a statistical summation of simulation outcomes. That mentioned, predicting the end result of a simulation is an ML drawback, and there are some good ML purposes in pricing advanced, path-dependent derivatives.
Finally, and apart from the above, a vital success think about any machine studying use case which shouldn’t be underestimated is the involvement of succesful and motivated individuals (usually quants and generally information scientists) who perceive the info (and find out how to manipulate it), enterprise processes, and worth levers. Success is often pushed by such individuals finishing up many iterative experiments on the issue at hand, which is in the end the place our platform is available in. As mentioned, we massively speed up that strategy of experimentation. There’s rather a lot that may be automated in machine studying, however area information can’t be.
To summarize: it’s honest to say that the likelihood of success in buying and selling use circumstances is positively correlated with the frequency of the buying and selling (or a minimum of negatively with the holding interval/horizon) with a number of exceptions to show the rule. It’s additionally value making an allowance for that machine studying is commonly higher at second-order use circumstances resembling predicting the drivers of markets, as an example, occasion threat and, to some extent, volumes, fairly than first-order worth predictions— topic to the above caveats.
About the writer

Managing Director, Financial Markets Data Science
Peter leads DataRobotic’s monetary markets information science apply and works intently with fintech, banking, and asset administration shoppers on quite a few high-ROI use circumstances for the DataRobotic AI Platform. Prior to becoming a member of DataRobotic, he gained twenty-five years’ expertise in senior quantitative analysis, portfolio administration, buying and selling, threat administration and information science roles at funding banks and asset managers together with Morgan Stanley, Warburg Pincus, Goldman Sachs, Credit Suisse, Lansdowne Partners and Invesco, in addition to spending a number of years as a accomplice at a start-up international equities hedge fund. Peter has an M.Sc. in Data Science from City, University of London, an MBA from Cranfield University School of Management, and a B.Sc. in Accounting and Financial Analysis from the University of Warwick. His paper, “Hunting High and Low: Visualising Shifting Correlations in Financial Markets”, was revealed within the July 2018 challenge of Computer Graphics Forum.
[ad_2]