
{kind=link}
[ad_1]
As we proceed to combine generative AI into our each day lives, it’s vital to know the potential harms that may come up from its use. Our ongoing dedication to advance secure, safe, and reliable AI contains transparency in regards to the capabilities and limitations of huge language fashions (LLMs). We prioritize analysis on societal dangers and constructing safe, secure AI, and concentrate on creating and deploying AI methods for the general public good. You can learn extra about Microsoft’s strategy to securing generative AI with new instruments we not too long ago introduced as obtainable or coming quickly to Microsoft Azure AI Studio for generative AI app builders.
We additionally made a dedication to determine and mitigate dangers and share data on novel, potential threats. For instance, earlier this yr Microsoft shared the rules shaping Microsoft’s coverage and actions blocking the nation-state superior persistent threats (APTs), superior persistent manipulators (APMs), and cybercriminal syndicates we observe from utilizing our AI instruments and APIs.
In this weblog submit, we are going to focus on a few of the key points surrounding AI harms and vulnerabilities, and the steps we’re taking to handle the chance.
The potential for malicious manipulation of LLMs
One of the primary issues with AI is its potential misuse for malicious functions. To forestall this, AI methods at Microsoft are constructed with a number of layers of defenses all through their structure. One function of those defenses is to restrict what the LLM will do, to align with the builders’ human values and objectives. But generally dangerous actors try and bypass these safeguards with the intent to attain unauthorized actions, which can end in what is named a “jailbreak.” The penalties can vary from the unapproved however much less dangerous—like getting the AI interface to speak like a pirate—to the very severe, resembling inducing AI to supply detailed directions on the right way to obtain unlawful actions. As a end result, a great deal of effort goes into shoring up these jailbreak defenses to guard AI-integrated functions from these behaviors.
While AI-integrated functions may be attacked like conventional software program (with strategies like buffer overflows and cross-site scripting), they will also be weak to extra specialised assaults that exploit their distinctive traits, together with the manipulation or injection of malicious directions by speaking to the AI mannequin via the person immediate. We can break these dangers into two teams of assault methods:
- Malicious prompts: When the person enter makes an attempt to avoid security methods with a purpose to obtain a harmful objective. Also known as person/direct immediate injection assault, or UPIA.
- Poisoned content material: When a well-intentioned person asks the AI system to course of a seemingly innocent doc (resembling summarizing an e-mail) that comprises content material created by a malicious third social gathering with the aim of exploiting a flaw within the AI system. Also often known as cross/oblique immediate injection assault, or XPIA.
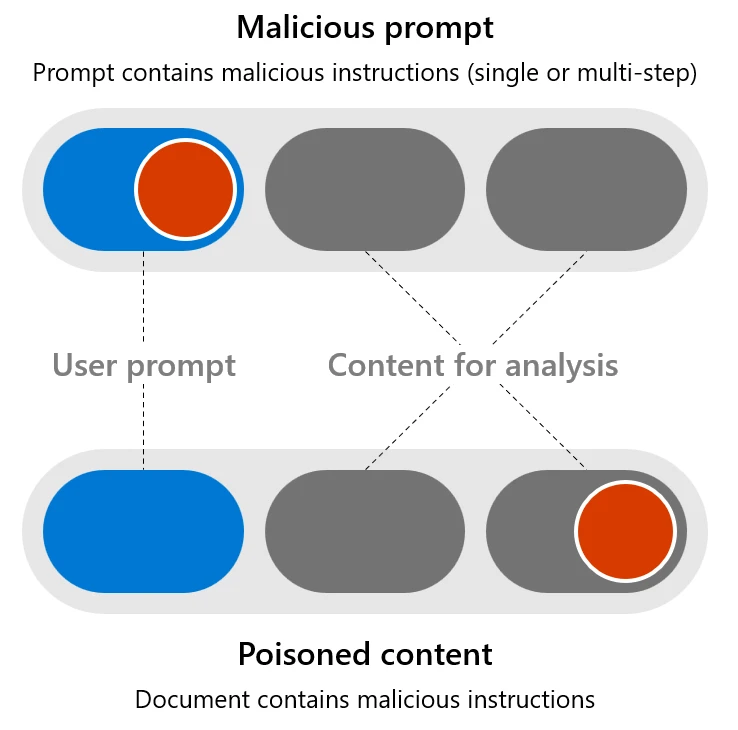
Today we’ll share two of our workforce’s advances on this area: the invention of a robust method to neutralize poisoned content material, and the invention of a novel household of malicious immediate assaults, and the right way to defend in opposition to them with a number of layers of mitigations.
Neutralizing poisoned content material (Spotlighting)
Prompt injection assaults via poisoned content material are a serious safety threat as a result of an attacker who does this may doubtlessly difficulty instructions to the AI system as in the event that they had been the person. For instance, a malicious e-mail may comprise a payload that, when summarized, would trigger the system to look the person’s e-mail (utilizing the person’s credentials) for different emails with delicate topics—say, “Password Reset”—and exfiltrate the contents of these emails to the attacker by fetching a picture from an attacker-controlled URL. As such capabilities are of apparent curiosity to a variety of adversaries, defending in opposition to them is a key requirement for the secure and safe operation of any AI service.
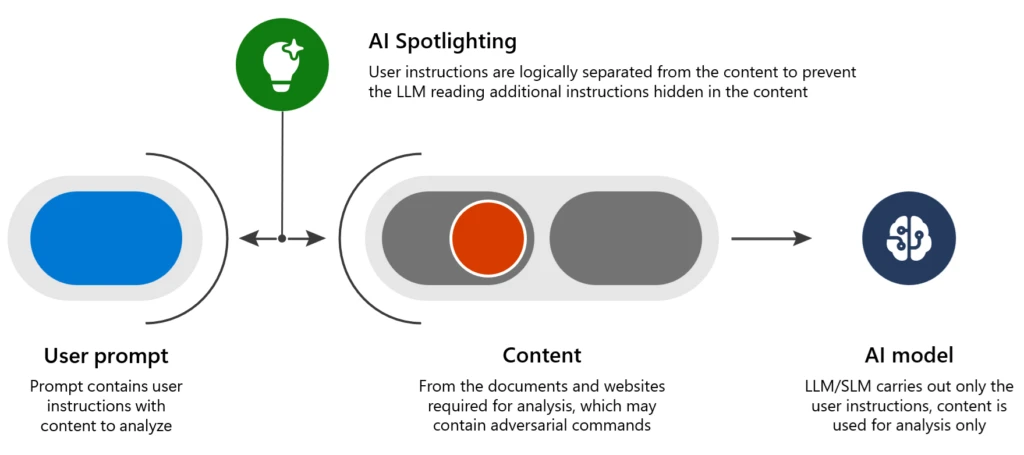
Our specialists have developed a household of methods known as Spotlighting that reduces the success fee of those assaults from greater than 20% to under the edge of detection, with minimal impact on the AI’s total efficiency:
- Spotlighting (also called knowledge marking) to make the exterior knowledge clearly separable from directions by the LLM, with completely different marking strategies providing a spread of high quality and robustness tradeoffs that depend upon the mannequin in use.
Mitigating the chance of multiturn threats (Crescendo)
Our researchers found a novel generalization of jailbreak assaults, which we name Crescendo. This assault can finest be described as a multiturn LLM jailbreak, and we have now discovered that it may well obtain a variety of malicious objectives in opposition to probably the most well-known LLMs used at the moment. Crescendo may also bypass lots of the current content material security filters, if not appropriately addressed. Once we found this jailbreak method, we rapidly shared our technical findings with different AI distributors so they may decide whether or not they had been affected and take actions they deem acceptable. The distributors we contacted are conscious of the potential affect of Crescendo assaults and targeted on defending their respective platforms, in response to their very own AI implementations and safeguards.
At its core, Crescendo tips LLMs into producing malicious content material by exploiting their very own responses. By asking rigorously crafted questions or prompts that step by step lead the LLM to a desired final result, moderately than asking for the objective all of sudden, it’s attainable to bypass guardrails and filters—this may normally be achieved in fewer than 10 interplay turns. You can examine Crescendo’s outcomes throughout quite a lot of LLMs and chat providers, and extra about how and why it really works, in our analysis paper.
While Crescendo assaults had been a shocking discovery, it is very important word that these assaults didn’t straight pose a menace to the privateness of customers in any other case interacting with the Crescendo-targeted AI system, or the safety of the AI system, itself. Rather, what Crescendo assaults bypass and defeat is content material filtering regulating the LLM, serving to to forestall an AI interface from behaving in undesirable methods. We are dedicated to repeatedly researching and addressing these, and different kinds of assaults, to assist preserve the safe operation and efficiency of AI methods for all.
In the case of Crescendo, our groups made software program updates to the LLM expertise behind Microsoft’s AI choices, together with our Copilot AI assistants, to mitigate the affect of this multiturn AI guardrail bypass. It is vital to notice that as extra researchers inside and outdoors Microsoft inevitably concentrate on discovering and publicizing AI bypass methods, Microsoft will proceed taking motion to replace protections in our merchandise, as main contributors to AI safety analysis, bug bounties and collaboration.
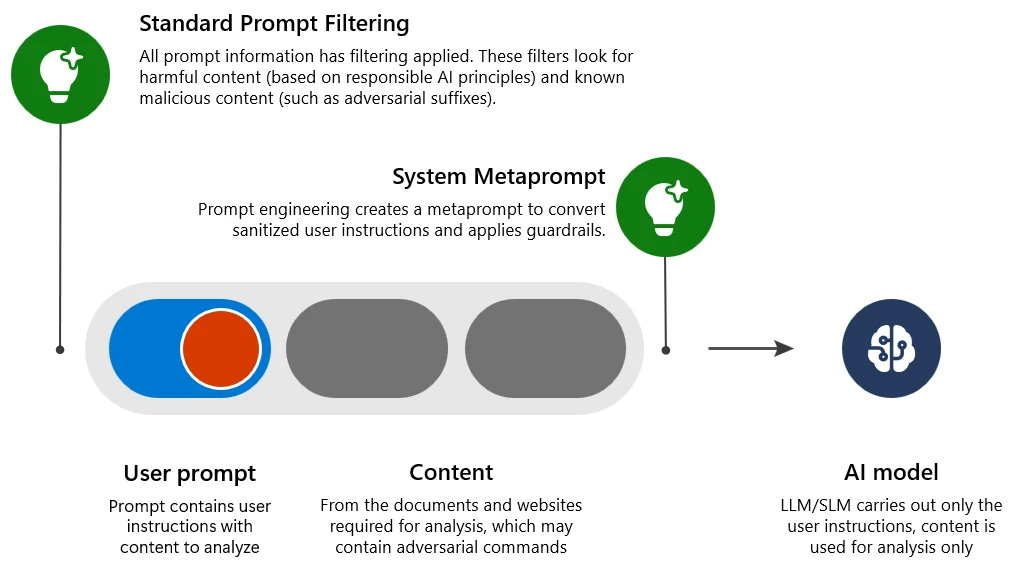
To perceive how we addressed the difficulty, allow us to first assessment how we mitigate a regular malicious immediate assault (single step, also called a one-shot jailbreak):
- Standard immediate filtering: Detect and reject inputs that comprise dangerous or malicious intent, which could circumvent the guardrails (inflicting a jailbreak assault).
- System metaprompt: Prompt engineering within the system to obviously clarify to the LLM the right way to behave and supply further guardrails.
Defending in opposition to Crescendo initially confronted some sensible issues. At first, we couldn’t detect a “jailbreak intent” with normal immediate filtering, as every particular person immediate will not be, by itself, a menace, and key phrases alone are inadequate to detect the sort of hurt. Only when mixed is the menace sample clear. Also, the LLM itself doesn’t see something out of the odd, since every successive step is well-rooted in what it had generated in a earlier step, with only a small further ask; this eliminates lots of the extra distinguished alerts that we may ordinarily use to forestall this type of assault.
To clear up the distinctive issues of multiturn LLM jailbreaks, we create further layers of mitigations to the earlier ones talked about above:
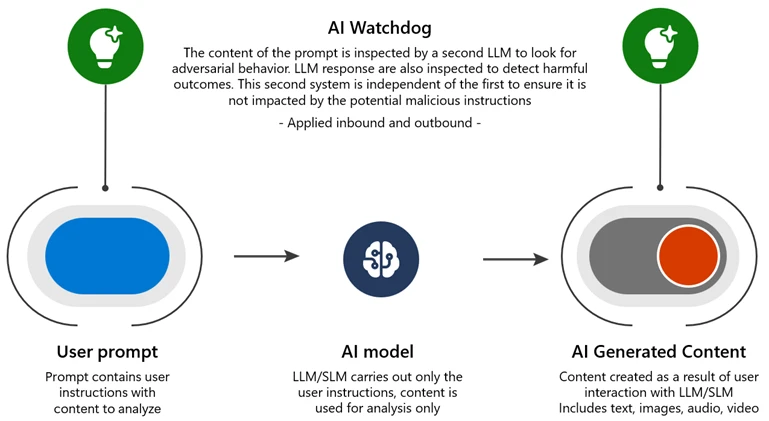
- Multiturn immediate filter: We have tailored enter filters to take a look at your complete sample of the prior dialog, not simply the speedy interplay. We discovered that even passing this bigger context window to current malicious intent detectors, with out bettering the detectors in any respect, considerably diminished the efficacy of Crescendo.
- AI Watchdog: Deploying an AI-driven detection system educated on adversarial examples, like a sniffer canine on the airport looking for contraband objects in baggage. As a separate AI system, it avoids being influenced by malicious directions. Microsoft Azure AI Content Safety is an instance of this strategy.
- Advanced analysis: We put money into analysis for extra complicated mitigations, derived from higher understanding of how LLM’s course of requests and go astray. These have the potential to guard not solely in opposition to Crescendo, however in opposition to the bigger household of social engineering assaults in opposition to LLM’s.
How Microsoft helps shield AI methods
AI has the potential to carry many advantages to our lives. But it is very important concentrate on new assault vectors and take steps to handle them. By working collectively and sharing vulnerability discoveries, we will proceed to enhance the protection and safety of AI methods. With the appropriate product protections in place, we proceed to be cautiously optimistic for the way forward for generative AI, and embrace the chances safely, with confidence. To study extra about creating accountable AI options with Azure AI, go to our web site.
To empower safety professionals and machine studying engineers to proactively discover dangers in their very own generative AI methods, Microsoft has launched an open automation framework, PyRIT (Python Risk Identification Toolkit for generative AI). Read extra in regards to the launch of PyRIT for generative AI Red teaming, and entry the PyRIT toolkit on GitHub. If you uncover new vulnerabilities in any AI platform, we encourage you to observe accountable disclosure practices for the platform proprietor. Microsoft’s personal process is defined right here: Microsoft AI Bounty.
The Crescendo Multi-Turn LLM Jailbreak Attack
Read about Crescendo’s outcomes throughout quite a lot of LLMs and chat providers, and extra about how and why it really works.

To study extra about Microsoft Security options, go to our web site. Bookmark the Security weblog to maintain up with our knowledgeable protection on safety issues. Also, observe us on LinkedIn (Microsoft Security) and X (@MSFTSecurity) for the newest information and updates on cybersecurity.
[ad_2]