
{kind=link}
[ad_1]
CIOs and different expertise leaders have come to comprehend that generative AI (GenAI) use instances require cautious monitoring – there are inherent dangers with these functions, and robust observability capabilities helps to mitigate them. They’ve additionally realized that the identical information science accuracy metrics generally used for predictive use instances, whereas helpful, will not be utterly adequate for LLMOps.
When it involves monitoring LLM outputs, response correctness stays essential, however now organizations additionally want to fret about metrics associated to toxicity, readability, personally identifiable info (PII) leaks, incomplete info, and most significantly, LLM prices. While all these metrics are new and essential for particular use instances, quantifying the unknown LLM prices is usually the one which comes up first in our buyer discussions.
This article shares a generalizable strategy to defining and monitoring customized, use case-specific efficiency metrics for generative AI use instances for deployments which might be monitored with DataRobotic AI Production.
Remember that fashions don’t must be constructed with DataRobotic to make use of the intensive governance and monitoring performance. Also do not forget that DataRobotic presents many deployment metrics out-of-the-box within the classes of Service Health, Data Drift, Accuracy and Fairness. The current dialogue is about including your personal user-defined Custom Metrics to a monitored deployment.
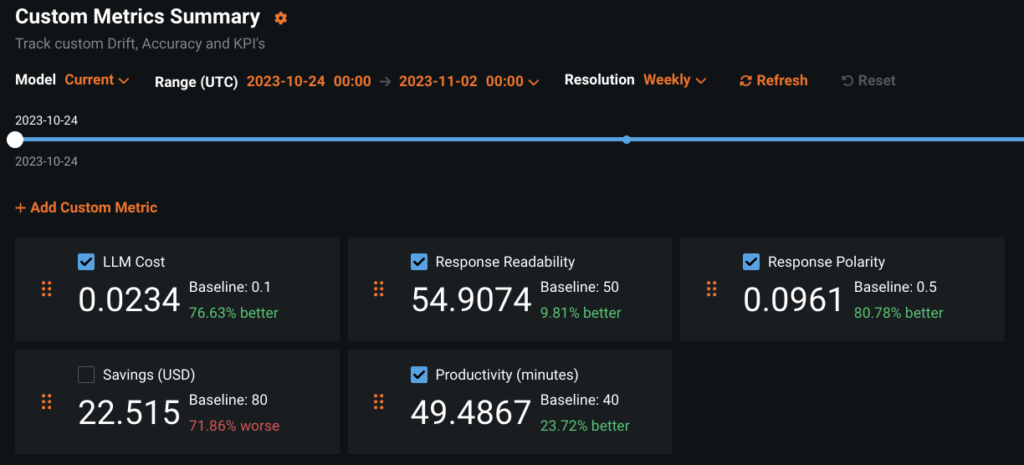
To illustrate this function, we’re utilizing a logistics-industry instance revealed on DataRobotic Community Github you can replicate by yourself with a DataRobotic license or with a free trial account. If you select to get hands-on, additionally watch the video beneath and evaluate the documentation on Custom Metrics.
Monitoring Metrics for Generative AI Use Cases
While DataRobotic presents you the pliability to outline any customized metric, the construction that follows will enable you slender your metrics right down to a manageable set that also offers broad visibility. If you outline one or two metrics in every of the classes beneath you’ll be capable to monitor value, end-user expertise, LLM misbehaviors, and worth creation. Let’s dive into every in future element.
Total Cost of Ownership
Metrics on this class monitor the expense of working the generative AI resolution. In the case of self-hosted LLMs, this might be the direct compute prices incurred. When utilizing externally-hosted LLMs this might be a operate of the price of every API name.
Defining your customized value metric for an exterior LLM would require information of the pricing mannequin. As of this writing the Azure OpenAI pricing web page lists the worth for utilizing GPT-3.5-Turbo 4K as $0.0015 per 1000 tokens within the immediate, plus $0.002 per 1000 tokens within the response. The following get_gpt_3_5_cost operate calculates the worth per prediction when utilizing these hard-coded costs and token counts for the immediate and response calculated with the assistance of Tiktoken.
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
def get_gpt_token_count(textual content):
return len(encoding.encode(textual content))
def get_gpt_3_5_cost(
immediate, response, prompt_token_cost=0.0015 / 1000, response_token_cost=0.002 / 1000
):
return (
get_gpt_token_count(immediate) * prompt_token_cost
+ get_gpt_token_count(response) * response_token_cost
)User Experience
Metrics on this class monitor the standard of the responses from the attitude of the supposed finish person. Quality will range primarily based on the use case and the person. You may desire a chatbot for a paralegal researcher to supply lengthy solutions written formally with numerous particulars. However, a chatbot for answering fundamental questions in regards to the dashboard lights in your automobile ought to reply plainly with out utilizing unfamiliar automotive phrases.
Two starter metrics for person expertise are response size and readability. You already noticed above find out how to seize the generated response size and the way it pertains to value. There are many choices for readability metrics. All of them are primarily based on some mixtures of common phrase size, common variety of syllables in phrases, and common sentence size. Flesch-Kincaid is one such readability metric with broad adoption. On a scale of 0 to 100, increased scores point out that the textual content is simpler to learn. Here is a simple approach to calculate the Readability of the generative response with the assistance of the textstat package deal.
import textstat
def get_response_readability(response):
return textstat.flesch_reading_ease(response)Safety and Regulatory Metrics
This class comprises metrics to watch generative AI options for content material that may be offensive (Safety) or violate the legislation (Regulatory). The proper metrics to symbolize this class will range enormously by use case and by the laws that apply to your {industry} or your location.
It is essential to notice that metrics on this class apply to the prompts submitted by customers and the responses generated by giant language fashions. You may want to monitor prompts for abusive and poisonous language, overt bias, prompt-injection hacks, or PII leaks. You may want to monitor generative responses for toxicity and bias as effectively, plus hallucinations and polarity.
Monitoring response polarity is helpful for guaranteeing that the answer isn’t producing textual content with a constant damaging outlook. In the linked instance which offers with proactive emails to tell prospects of cargo standing, the polarity of the generated e-mail is checked earlier than it’s proven to the top person. If the e-mail is extraordinarily damaging, it’s over-written with a message that instructs the shopper to contact buyer help for an replace on their cargo. Here is one approach to outline a Polarity metric with the assistance of the TextBlob package deal.
import numpy as np
from textblob import TextBlob
def get_response_polarity(response):
blob = TextBlob(response)
return np.imply([sentence.sentiment.polarity for sentence in blob.sentences])Business Value
CIO are below growing strain to exhibit clear enterprise worth from generative AI options. In a super world, the ROI, and find out how to calculate it, is a consideration in approving the use case to be constructed. But, within the present rush to experiment with generative AI, that has not at all times been the case. Adding enterprise worth metrics to a GenAI resolution that was constructed as a proof-of-concept can assist safe long-term funding for it and for the subsequent use case.
Generative AI 101 for Executives: a Video Crash Course
We can’t construct your generative AI technique for you, however we will steer you in the suitable path
The metrics on this class are solely use-case dependent. To illustrate this, take into account find out how to measure the enterprise worth of the pattern use case coping with proactive notifications to prospects in regards to the standing of their shipments.
One approach to measure the worth is to contemplate the typical typing pace of a buyer help agent who, within the absence of the generative resolution, would sort out a customized e-mail from scratch. Ignoring the time required to analysis the standing of the shopper’s cargo and simply quantifying the typing time at 150 phrases per minute and $20 per hour may very well be computed as follows.
def get_productivity(response):
return get_gpt_token_count(response) * 20 / (150 * 60)More possible the actual enterprise influence can be in lowered calls to the contact heart and better buyer satisfaction. Let’s stipulate that this enterprise has skilled a 30% decline in name quantity since implementing the generative AI resolution. In that case the actual financial savings related to every e-mail proactively despatched might be calculated as follows.
def get_savings(CONTAINER_NUMBER):
prob = 0.3
email_cost = $0.05
call_cost = $4.00
return prob * (call_cost - email_cost)Create and Submit Custom Metrics in DataRobotic
Create Custom Metric
Once you could have definitions and names on your customized metrics, including them to a deployment may be very straight-forward. You can add metrics to the Custom Metrics tab of a Deployment utilizing the button +Add Custom Metric within the UI or with code. For each routes, you’ll want to produce the knowledge proven on this dialogue field beneath.
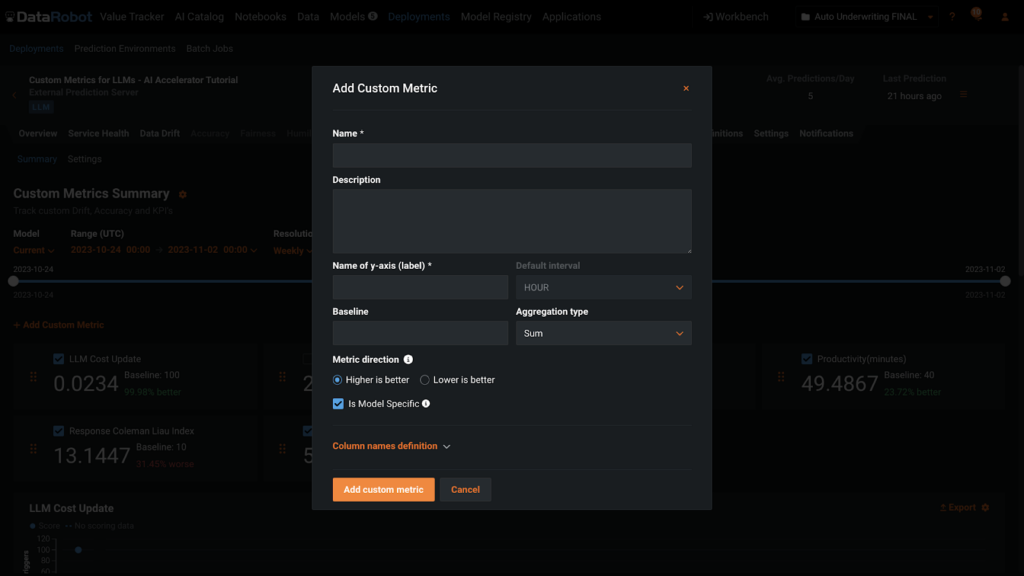
Submit Custom Metric
There are a number of choices for submitting customized metrics to a deployment that are coated intimately in the help documentation. Depending on the way you outline the metrics, you may know the values instantly or there could also be a delay and also you’ll have to affiliate them with the deployment at a later date.
It is greatest follow to conjoin the submission of metric particulars with the LLM prediction to keep away from lacking any info. In this screenshot beneath, which is an excerpt from a bigger operate, you see llm.predict() within the first row. Next you see the Polarity take a look at and the override logic. Finally, you see the submission of the metrics to the deployment.
Put one other approach, there is no such thing as a approach for a person to make use of this generative resolution, with out having the metrics recorded. Each name to the LLM and its response is totally monitored.
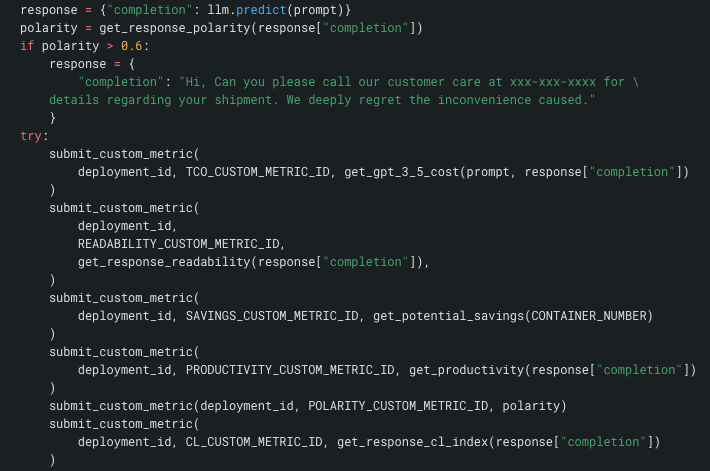
DataRobotic for Generative AI
We hope this deep dive into metrics for Generative AI provides you a greater understanding of find out how to use the DataRobotic AI Platform for working and governing your generative AI use instances. While this text targeted narrowly on monitoring metrics, the DataRobotic AI Platform can assist you with simplifying all the AI lifecycle – to construct, function, and govern enterprise-grade generative AI options, safely and reliably.
Enjoy the liberty to work with all the very best instruments and methods, throughout cloud environments, multi functional place. Breakdown silos and stop new ones with one constant expertise. Deploy and keep protected, high-quality, generative AI functions and options in manufacturing.
[ad_2]