
{kind=link}
[ad_1]

MIT researchers developed an AI method that permits a robotic to develop complicated plans for manipulating an object utilizing its whole hand, not simply the fingertips. This mannequin can generate efficient plans in a couple of minute utilizing an ordinary laptop computer. Here, a robotic makes an attempt to rotate a bucket 180 levels. Image: Courtesy of the researchers
By Adam Zewe | MIT News
Imagine you wish to carry a big, heavy field up a flight of stairs. You may unfold your fingers out and elevate that field with each arms, then maintain it on high of your forearms and steadiness it in opposition to your chest, utilizing your complete physique to control the field.
Humans are usually good at whole-body manipulation, however robots battle with such duties. To the robotic, every spot the place the field may contact any level on the service’s fingers, arms, and torso represents a contact occasion that it should cause about. With billions of potential contact occasions, planning for this activity rapidly turns into intractable.
Now MIT researchers discovered a method to simplify this course of, often known as contact-rich manipulation planning. They use an AI method known as smoothing, which summarizes many contact occasions right into a smaller variety of choices, to allow even a easy algorithm to rapidly determine an efficient manipulation plan for the robotic.
While nonetheless in its early days, this technique may probably allow factories to make use of smaller, cellular robots that may manipulate objects with their whole arms or our bodies, reasonably than giant robotic arms that may solely grasp utilizing fingertips. This could assist scale back power consumption and drive down prices. In addition, this system may very well be helpful in robots despatched on exploration missions to Mars or different photo voltaic system our bodies, since they may adapt to the atmosphere rapidly utilizing solely an onboard pc.
“Rather than thinking about this as a black-box system, if we can leverage the structure of these kinds of robotic systems using models, there is an opportunity to accelerate the whole procedure of trying to make these decisions and come up with contact-rich plans,” says H.J. Terry Suh, {an electrical} engineering and pc science (EECS) graduate scholar and co-lead creator of a paper on this system.
Joining Suh on the paper are co-lead creator Tao Pang PhD ’23, a roboticist at Boston Dynamics AI Institute; Lujie Yang, an EECS graduate scholar; and senior creator Russ Tedrake, the Toyota Professor of EECS, Aeronautics and Astronautics, and Mechanical Engineering, and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL). The analysis seems this week in IEEE Transactions on Robotics.
Learning about studying
Reinforcement studying is a machine-learning method the place an agent, like a robotic, learns to finish a activity by trial and error with a reward for getting nearer to a purpose. Researchers say this sort of studying takes a black-box strategy as a result of the system should study every part concerning the world by trial and error.
It has been used successfully for contact-rich manipulation planning, the place the robotic seeks to study one of the simplest ways to maneuver an object in a specified method.
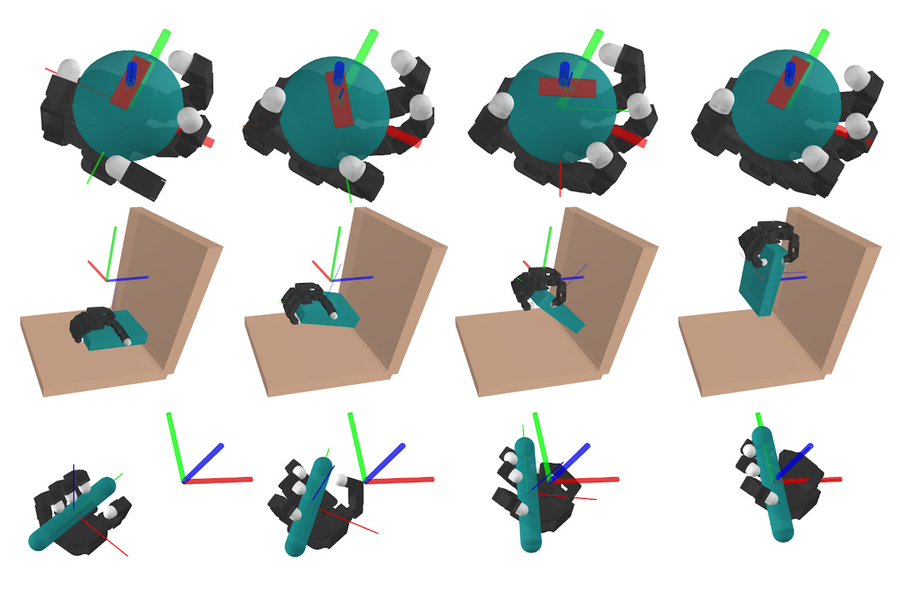
In these figures, a simulated robotic performs three contact-rich manipulation duties: in-hand manipulation of a ball, choosing up a plate, and manipulating a pen into a particular orientation. Image: Courtesy of the researchers
But as a result of there could also be billions of potential contact factors {that a} robotic should cause about when figuring out easy methods to use its fingers, arms, arms, and physique to work together with an object, this trial-and-error strategy requires an excessive amount of computation.
“Reinforcement learning may need to go through millions of years in simulation time to actually be able to learn a policy,” Suh provides.
On the opposite hand, if researchers particularly design a physics-based mannequin utilizing their information of the system and the duty they need the robotic to perform, that mannequin incorporates construction about this world that makes it extra environment friendly.
Yet physics-based approaches aren’t as efficient as reinforcement studying on the subject of contact-rich manipulation planning — Suh and Pang puzzled why.
They performed an in depth evaluation and located {that a} method often known as smoothing permits reinforcement studying to carry out so effectively.
Many of the selections a robotic may make when figuring out easy methods to manipulate an object aren’t necessary within the grand scheme of issues. For occasion, every infinitesimal adjustment of 1 finger, whether or not or not it leads to contact with the thing, doesn’t matter very a lot. Smoothing averages away lots of these unimportant, intermediate choices, leaving just a few necessary ones.
Reinforcement studying performs smoothing implicitly by making an attempt many contact factors after which computing a weighted common of the outcomes. Drawing on this perception, the MIT researchers designed a easy mannequin that performs the same sort of smoothing, enabling it to deal with core robot-object interactions and predict long-term habits. They confirmed that this strategy may very well be simply as efficient as reinforcement studying at producing complicated plans.
“If you know a bit more about your problem, you can design more efficient algorithms,” Pang says.
A successful mixture
Even although smoothing significantly simplifies the selections, looking out by the remaining choices can nonetheless be a troublesome drawback. So, the researchers mixed their mannequin with an algorithm that may quickly and effectively search by all doable choices the robotic may make.
With this mixture, the computation time was lower right down to a couple of minute on an ordinary laptop computer.
They first examined their strategy in simulations the place robotic arms got duties like shifting a pen to a desired configuration, opening a door, or choosing up a plate. In every occasion, their model-based strategy achieved the identical efficiency as reinforcement studying, however in a fraction of the time. They noticed comparable outcomes once they examined their mannequin in {hardware} on actual robotic arms.
“The same ideas that enable whole-body manipulation also work for planning with dexterous, human-like hands. Previously, most researchers said that reinforcement learning was the only approach that scaled to dexterous hands, but Terry and Tao showed that by taking this key idea of (randomized) smoothing from reinforcement learning, they can make more traditional planning methods work extremely well, too,” Tedrake says.
However, the mannequin they developed depends on an easier approximation of the actual world, so it can’t deal with very dynamic motions, reminiscent of objects falling. While efficient for slower manipulation duties, their strategy can’t create a plan that might allow a robotic to toss a can right into a trash bin, as an illustration. In the longer term, the researchers plan to boost their method so it may sort out these extremely dynamic motions.
“If you study your models carefully and really understand the problem you are trying to solve, there are definitely some gains you can achieve. There are benefits to doing things that are beyond the black box,” Suh says.
This work is funded, partly, by Amazon, MIT Lincoln Laboratory, the National Science Foundation, and the Ocado Group.

MIT News
[ad_2]