
{kind=link}
[ad_1]
In December 2019, we made a daring announcement about how we’d endlessly change the economics of the web and drive innovation at speeds like nobody had ever seen earlier than. These have been formidable claims, and never surprisingly, many individuals took a wait-and-see perspective. Since then, we’ve continued to innovate at an more and more quick tempo, main the {industry} with revolutionary options that meet our clients’ wants.
Today, simply three and a half years after launching Cisco Silicon One™, we’re proud to announce our fourth-generation set of gadgets, the Cisco Silicon One G200 and Cisco Silicon One G202, which we’re sampling to clients now. Typically, new generations are launched each 18 to 24 months, demonstrating a tempo of innovation that’s two occasions sooner than regular silicon improvement.
The Cisco Silicon One G200 affords the advantages of our unified structure and focuses particularly on enhanced Ethernet-based synthetic intelligence/machine studying (AI/ML) and web-scale backbone deployments. The Cisco Silicon One G200 is a 5 nm, 51.2 Tbps, 512 x 112 Gbps serializer-deserializer (SerDes) system. It is a uniquely programmable, deterministic, low-latency system with superior visibility and management, making it the best selection for web-scale networks.
The Cisco Silicon One G202 brings comparable advantages to clients who nonetheless wish to use the 50G SerDes for connecting optics to the change. It is a 5 nm, 25.6 Tbps, 512 x 56 Gbps SerDes system with the identical traits because the Cisco Silicon One G200 however with half the efficiency.
To obtain the imaginative and prescient of Cisco Silicon One, it was crucial for us to put money into key applied sciences. Seven years in the past, Cisco started investing in our personal high-speed SerDes improvement and realized instantly that as speeds enhance, the {industry} should transfer to analog-to-digital (ADC)-based SerDes. SerDes acts as a basic constructing block of networking interconnect for high-performance compute and AI deployments. Today, we’re happy to announce our next-generation, ultra-high efficiency, and low-power 112 Gbps ADC SerDes able to ultra-long attain channels supporting 4-meter direct-attach cables (DACs), conventional optics, linear drive optics (LDO), and co-packaged optics (CPO), whereas minimizing silicon die space and energy.

The Cisco Silicon One G200 and G202 are uniquely positioned within the {industry} with superior options to optimize real-world efficiency of AI/ML workloads—whereas concurrently driving down the associated fee, energy, and latency of the community with important improvements.
The Cisco Silicon One G200 is the best answer for Ethernet-based AI/ML networks for a number of causes:
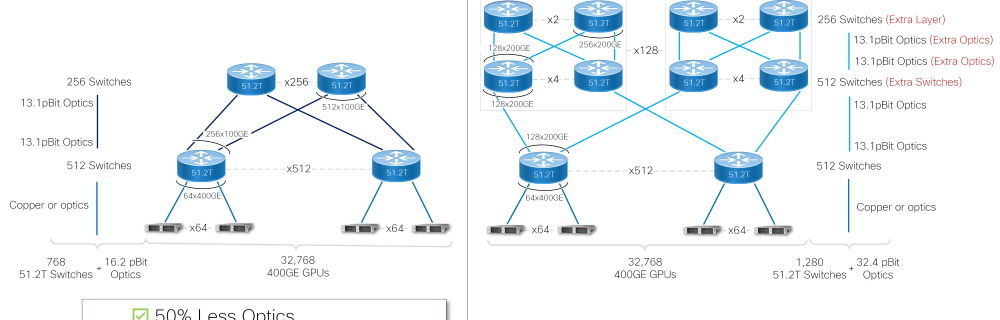
~ With the {industry}’s highest radix change, with 512 x 100GE Ethernet ports on one system, clients can construct a 32K 400G GPUs AI/ML cluster with a 2-layer community requiring 50% much less optics, 40% fewer switches, and 33% fewer networking layers—drastically decreasing the environmental footprint of the AI/ML cluster. This saves as much as 9 million kWh per yr, which in response to the U.S. Environmental Protection Agency is equal to greater than 6,000 metric tons of carbon dioxide (CO2e) or burning 7.3 million kilos of coal per yr.
~ Advanced congestion-aware load balancing strategies allow networks to keep away from conventional congestion occasions.
~ Advanced packet-spraying strategies reduce creation of congestion scorching spots within the community.
~ Advanced hardware-based link-failure restoration delivers optimum efficiency throughout huge web-scale networks, even within the presence of faults.
Here’s a more in-depth have a look at a few of our many Cisco Silicon One–associated improvements:
Converged structure
~ Cisco Silicon One offers one structure that may be deployed throughout buyer networks, from routing roles to web-scale front-end networks to web-scale back-end networks, dramatically decreasing deployment timelines, whereas concurrently minimizing ongoing operations prices by enabling a converged infrastructure.
~ Using a typical software program improvement package (SDK) and commonplace Switch Abstraction Interface (SAI) layers, clients want solely port the Cisco Silicon One setting to their community working system (NOS) as soon as and make use of that funding throughout various community roles.
~ Like all our gadgets, the Cisco Silicon One G200 has a big and totally unified packet-buffer optimizing burst-absorption and throughput in giant web-scale networks. This minimizes head-of-line blocking by absorbing bursts as an alternative of the era of precedence move management.
Optimization throughout all the worth chain
~ The Cisco Silicon One G200 has as much as two occasions greater radix than different options with 512 Ethernet MACs, enabling clients to considerably cut back the associated fee, energy, and latency of community deployments by eradicating layers of their community.
~ With our personal internally developed, next-generation, SerDes know-how, the Cisco Silicon One G200 system is able to driving 43 dB bump-to-bump channels that allow co-packaged optics (CPO), linear pluggable objects (LPO), and the usage of 4-meter 26 AWG copper cables, which is effectively past IEEE requirements for optimum in-rack connectivity.
~ The Silicon One G200 is over two occasions extra energy environment friendly with two occasions decrease latency in comparison with our already optimized Cisco Silicon One G100 system.
~ The bodily design and format of the system is constructed with a system-first method, permitting clients to run system followers slower, dramatically lowering system energy draw.
Innovative load balancing and fault detection
~ Support for non-correlated, weighted equal-cost multipath (WECMP) and equal-cost multipath (ECMP) load balancing capabilities with near-ideal traits assist to keep away from hash polarization, even throughout huge networks.
~ Congestion-aware load balancing for stateful ECMP, move, and flowlet allows optimum community throughput with optimum flow-completion time and job-completion time (JCT).
~ Congestion-aware stateless packet spraying allows close to superb JCT through the use of all obtainable community bandwidth, no matter move traits.
~ Support for hardware-based redistribution of packets based mostly on hyperlink failures allows Cisco Silicon One G200 to optimize real-world throughput of huge scale networks.
Advanced packet processor
~ The Cisco Silicon One G200 makes use of the {industry}’s first totally customized, P4 programmable parallel packet processor able to launching greater than 435 billion lookups per second. It helps superior options like SRv6 Micro-SID (uSID) at full price and is extendable with full run-to-completion processing for much more complicated flows. This distinctive packet processing structure allows flexibility with deterministic low latency and energy.
Deep visibility and analytics
~ Programmable processors allow help for normal and rising web-scale in-band telemetry requirements offering industry-leading community visibility.
~ Embedded {hardware} analyzers detect microbursts with pre- and post-event logging of temporal move data, giving community operators the power to research community occasions after the actual fact with {hardware} time visibility.
A brand new era of community capabilities
Gone are the times when the {industry} operated in silos. With its one unified structure, Cisco Silicon One erases the arduous dividing strains which have outlined our {industry} for too lengthy. Customers not want to fret about architectural variations rooted in previous creativeness and know-how limitations. Today, clients can deploy Cisco Silicon One in a mess of the way throughout their networks.
With the Cisco Silicon One G200 and G202 gadgets, we lengthen the attain of Cisco Silicon One with optimized high-bandwidth gadgets purpose-built for backbone and AI/ML deployments. Customers can get monetary savings by deploying fewer and extra environment friendly gadgets, get pleasure from new deployment topologies with ultra-long-reach SerDes, enhance their AI/ML job efficiency with revolutionary load balancing and fault discovery strategies, and enhance community debuggability with superior telemetry and {hardware} analyzers.
If you’ve been watching since we first introduced Cisco Silicon One in December 2019, it’s straightforward to see that that is only the start. We’re trying ahead to persevering with to speed up the worth addition for our clients.
Stay tuned for extra thrilling Cisco Silicon One developments.
Learn extra about
structure, gadgets, and advantages.
Additional Resources
Read my first weblog on Silicon One: Building AI/ML Networks with Cisco Silicon One
Share:
[ad_2]