
{kind=link}
[ad_1]

|
Last December, Sébastien Stormacq wrote in regards to the availability of a distributed map state for AWS Step Functions, a brand new function that permits you to orchestrate large-scale parallel workloads within the cloud. That’s when Charles Burton, an information programs engineer for an organization referred to as CyberGRX, discovered about it and refactored his workflow, decreasing the processing time for his machine studying (ML) processing job from 8 days to 56 minutes. Before, working the job required an engineer to continually monitor it; now, it runs in lower than an hour with no assist wanted. In addition, the brand new implementation with AWS Step Functions Distributed Map prices lower than what it did initially.
What CyberGRX achieved with this answer is an ideal instance of what serverless applied sciences embrace: letting the cloud do as a lot of the undifferentiated heavy lifting as doable so the engineers and information scientists have extra time to give attention to what’s necessary for the enterprise. In this case, meaning persevering with to enhance the mannequin and the processes for one of many key choices from CyberGRX, a cyber danger evaluation of third events utilizing ML insights from its giant and rising database.
What’s the enterprise problem?
CyberGRX shares third-party cyber danger (TPCRM) information with their prospects. They predict, with excessive confidence, how a third-party firm will reply to a danger evaluation questionnaire. To do that, they should run their predictive mannequin on each firm of their platform; they at present have predictive information on greater than 225,000 corporations. Whenever there’s a brand new firm or the info modifications for an organization, they regenerate their predictive mannequin by processing their complete dataset. Over time, CyberGRX information scientists enhance the mannequin or add new options to it, which additionally requires the mannequin to be regenerated.
The problem is working this job for 225,000 corporations in a well timed method, with as few hands-on sources as doable. The job runs a set of operations for every firm, and each firm calculation is impartial of different corporations. This implies that within the perfect case, each firm may be processed on the identical time. However, implementing such a large parallelization is a difficult drawback to unravel.
First iteration
With that in thoughts, the corporate constructed their first iteration of the pipeline utilizing Kubernetes and Argo Workflows, an open-source container-native workflow engine for orchestrating parallel jobs on Kubernetes. These have been instruments they have been accustomed to, as they have been already utilizing them of their infrastructure.
But as quickly as they tried to run the job for all the businesses on the platform, they ran up towards the bounds of what their system might deal with effectively. Because the answer trusted a centralized controller, Argo Workflows, it was not strong, and the controller was scaled to its most capability throughout this time. At that point, they solely had 150,000 corporations. And working the job with all the corporations took round 8 days, throughout which the system would crash and should be restarted. It was very labor intensive, and it at all times required an engineer on name to watch and troubleshoot the job.
The tipping level got here when Charles joined the Analytics group originally of 2022. One of his first duties was to do a full mannequin run on roughly 170,000 corporations at the moment. The mannequin run lasted the entire week and ended at 2:00 AM on a Sunday. That’s when he determined their system wanted to evolve.
Second iteration
With the ache of the final time he ran the mannequin recent in his thoughts, Charles thought by means of how he might rewrite the workflow. His first thought was to make use of AWS Lambda and SQS, however he realized that he wanted an orchestrator in that answer. That’s why he selected Step Functions, a serverless service that helps you automate processes, orchestrate microservices, and create information and ML pipelines; plus, it scales as wanted.
Charles received the brand new model of the workflow with Step Functions working in about 2 weeks. The first step he took was adapting his present Docker picture to run in Lambda utilizing Lambda’s container picture packaging format. Because the container already labored for his information processing duties, this replace was easy. He scheduled Lambda provisioned concurrency to guarantee that all capabilities he wanted have been prepared when he began the job. He additionally configured reserved concurrency to guarantee that Lambda would have the ability to deal with this most variety of concurrent executions at a time. In order to assist so many capabilities executing on the identical time, he raised the concurrent execution quota for Lambda per account.
And to guarantee that the steps have been run in parallel, he used Step Functions and the map state. The map state allowed Charles to run a set of workflow steps for every merchandise in a dataset. The iterations run in parallel. Because Step Functions map state provides 40 concurrent executions and CyberGRX wanted extra parallelization, they created an answer that launched a number of state machines in parallel; on this method, they have been in a position to iterate quick throughout all the businesses. Creating this advanced answer, required a preprocessor that dealt with the heuristics of the concurrency of the system and break up the enter information throughout a number of state machines.
This second iteration was already higher than the primary one, as now it was in a position to end the execution with no issues, and it might iterate over 200,000 corporations in 90 minutes. However, the preprocessor was a really advanced a part of the system, and it was hitting the bounds of the Lambda and Step Functions APIs because of the quantity of parallelization.

Third and closing iteration
Then, throughout AWS re:Invent 2022, AWS introduced a distributed map for Step Functions, a brand new kind of map state that permits you to write Step Functions to coordinate large-scale parallel workloads. Using this new function, you may simply iterate over thousands and thousands of objects saved in Amazon Simple Storage Service (Amazon S3), after which the distributed map can launch as much as 10,000 parallel sub-workflows to course of the info.
When Charles learn within the News Blog article in regards to the 10,000 parallel workflow executions, he instantly considered making an attempt this new state. In a few weeks, Charles constructed the brand new iteration of the workflow.
Because the distributed map state break up the enter into completely different processors and dealt with the concurrency of the completely different executions, Charles was in a position to drop the advanced preprocessor code.
The new course of was the only that it’s ever been; now every time they need to run the job, they only add a file to Amazon S3 with the enter information. This motion triggers an Amazon EventBridge rule that targets the state machine with the distributed map. The state machine then executes with that file as an enter and publishes the outcomes to an Amazon Simple Notification Service (Amazon SNS) subject.
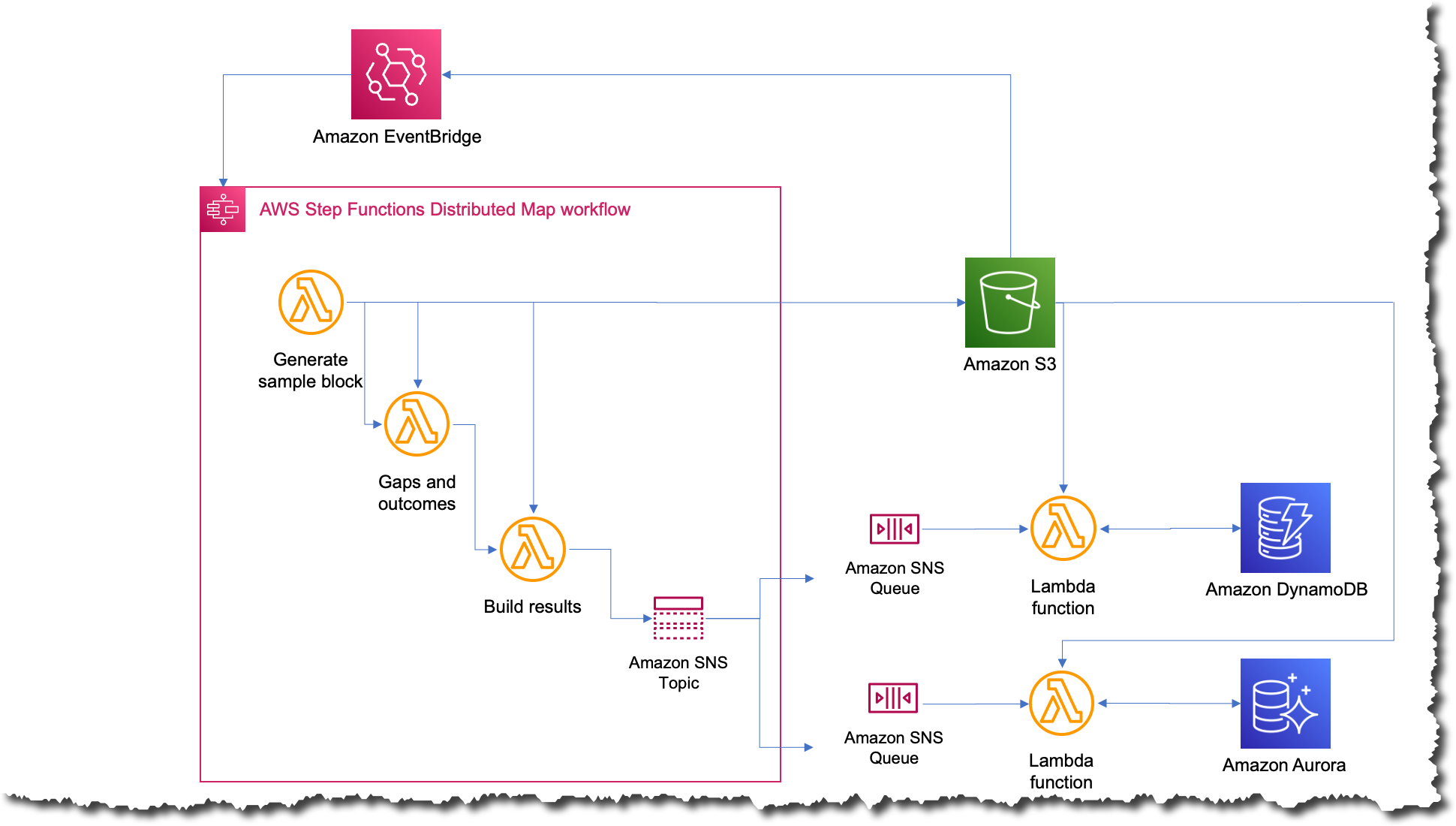
What was the affect?
A couple of weeks after finishing the third iteration, they needed to run the job on all 227,000 corporations of their platform. When the job completed, Charles’ group was blown away; the entire course of took solely 56 minutes to finish. They estimated that in these 56 minutes, the job ran greater than 57 billion calculations.

The following picture exhibits an Amazon CloudWatch graph of the concurrent executions for one Lambda operate through the time that the workflow was working. There are nearly 10,000 capabilities working in parallel throughout this time.

Simplifying and shortening the time to run the job opens a variety of potentialities for CyberGRX and the info science group. The advantages began immediately the second one of many information scientists wished to run the job to check some enhancements that they had made for the mannequin. They have been in a position to run it independently with out requiring an engineer to assist them.
And, as a result of the predictive mannequin itself is without doubt one of the key choices from CyberGRX, the corporate now has a extra aggressive product for the reason that predictive evaluation may be refined each day.
Learn extra about utilizing AWS Step Functions:
You may also examine the Serverless Workflows Collection that we now have out there in Serverless Land so that you can check and be taught extra about this new functionality.
— Marcia
[ad_2]