
{kind=link}
[ad_1]
Reinforcement studying (RL) can allow robots to study complicated behaviors by means of trial-and-error interplay, getting higher and higher over time. Several of our prior works explored how RL can allow intricate robotic expertise, reminiscent of robotic greedy, multi-task studying, and even enjoying desk tennis. Although robotic RL has come a great distance, we nonetheless do not see RL-enabled robots in on a regular basis settings. The actual world is complicated, numerous, and adjustments over time, presenting a significant problem for robotic programs. However, we imagine that RL ought to provide us a wonderful device for tackling exactly these challenges: by frequently working towards, getting higher, and studying on the job, robots ought to be capable to adapt to the world because it adjustments round them.
In “Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators”, we focus on how we studied this downside by means of a current large-scale experiment, the place we deployed a fleet of 23 RL-enabled robots over two years in Google workplace buildings to kind waste and recycling. Our robotic system combines scalable deep RL from real-world information with bootstrapping from coaching in simulation and auxiliary object notion inputs to spice up generalization, whereas retaining the advantages of end-to-end coaching, which we validate with 4,800 analysis trials throughout 240 waste station configurations.
Problem setup
When folks don’t kind their trash correctly, batches of recyclables can change into contaminated and compost might be improperly discarded into landfills. In our experiment, a robotic roamed round an workplace constructing looking for “waste stations” (bins for recyclables, compost, and trash). The robotic was tasked with approaching every waste station to kind it, transferring objects between the bins so that every one recyclables (cans, bottles) have been positioned within the recyclable bin, all of the compostable objects (cardboard containers, paper cups) have been positioned within the compost bin, and all the pieces else was positioned within the landfill trash bin. Here is what that appears like:
This job is just not as straightforward because it appears. Just having the ability to decide up the huge number of objects that folks deposit into waste bins presents a significant studying problem. Robots additionally should determine the suitable bin for every object and kind them as rapidly and effectively as potential. In the actual world, the robots can encounter a wide range of conditions with distinctive objects, just like the examples from actual workplace buildings beneath:
 |
Learning from numerous expertise
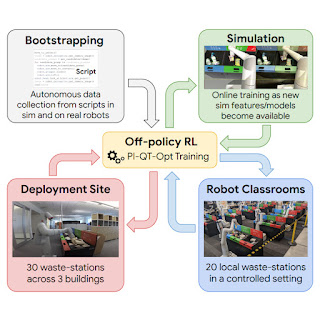
Learning on the job helps, however earlier than even attending to that time, we have to bootstrap the robots with a fundamental set of expertise. To this finish, we use 4 sources of expertise: (1) a set of straightforward hand-designed insurance policies which have a really low success price, however serve to offer some preliminary expertise, (2) a simulated coaching framework that makes use of sim-to-real switch to offer some preliminary bin sorting methods, (3) “robot classrooms” the place the robots frequently apply at a set of consultant waste stations, and (4) the actual deployment setting, the place robots apply in actual workplace buildings with actual trash.
 |
| A diagram of RL at scale. We bootstrap insurance policies from information generated with a script (top-left). We then practice a sim-to-real mannequin and generate extra information in simulation (top-right). At every deployment cycle, we add information collected in our school rooms (bottom-right). We additional deploy and acquire information in workplace buildings (bottom-left). |
Our RL framework is predicated on QT-Opt, which we beforehand utilized to study bin greedy in laboratory settings, in addition to a variety of different expertise. In simulation, we bootstrap from easy scripted insurance policies and use RL, with a CycleGAN-based switch technique that makes use of RetinaGAN to make the simulated photos seem extra life-like.
From right here, it’s off to the classroom. While real-world workplace buildings can present essentially the most consultant expertise, the throughput when it comes to information assortment is proscribed — some days there will likely be loads of trash to kind, some days not a lot. Our robots acquire a big portion of their expertise in “robot classrooms.” In the classroom proven beneath, 20 robots apply the waste sorting job:
While these robots are coaching within the school rooms, different robots are concurrently studying on the job in 3 workplace buildings, with 30 waste stations:
Sorting efficiency
In the tip, we gathered 540k trials within the school rooms and 32.5k trials from deployment. Overall system efficiency improved as extra information was collected. We evaluated our remaining system within the school rooms to permit for managed comparisons, establishing situations based mostly on what the robots noticed throughout deployment. The remaining system may precisely kind about 84% of the objects on common, with efficiency growing steadily as extra information was added. In the actual world, we logged statistics from three real-world deployments between 2021 and 2022, and located that our system may cut back contamination within the waste bins by between 40% and 50% by weight. Our paper offers additional insights on the technical design, ablations finding out varied design choices, and extra detailed statistics on the experiments.
Conclusion and future work
Our experiments confirmed that RL-based programs can allow robots to deal with real-world duties in actual workplace environments, with a mixture of offline and on-line information enabling robots to adapt to the broad variability of real-world conditions. At the identical time, studying in additional managed “classroom” environments, each in simulation and in the actual world, can present a strong bootstrapping mechanism to get the RL “flywheel” spinning to allow this adaptation. There remains to be rather a lot left to do: our remaining RL insurance policies don’t succeed each time, and bigger and extra highly effective fashions will likely be wanted to enhance their efficiency and prolong them to a broader vary of duties. Other sources of expertise, together with from different duties, different robots, and even Internet movies could serve to additional complement the bootstrapping expertise that we obtained from simulation and school rooms. These are thrilling issues to deal with sooner or later. Please see the total paper right here, and the supplementary video supplies on the venture webpage.
Acknowledgements
This analysis was performed by a number of researchers at Robotics at Google and Everyday Robots, with contributions from Alexander Herzog, Kanishka Rao, Karol Hausman, Yao Lu, Paul Wohlhart, Mengyuan Yan, Jessica Lin, Montserrat Gonzalez Arenas, Ted Xiao, Daniel Kappler, Daniel Ho, Jarek Rettinghouse, Yevgen Chebotar, Kuang-Huei Lee, Keerthana Gopalakrishnan, Ryan Julian, Adrian Li, Chuyuan Kelly Fu, Bob Wei, Sangeetha Ramesh, Khem Holden, Kim Kleiven, David Rendleman, Sean Kirmani, Jeff Bingham, Jon Weisz, Ying Xu, Wenlong Lu, Matthew Bennice, Cody Fong, David Do, Jessica Lam, Yunfei Bai, Benjie Holson, Michael Quinlan, Noah Brown, Mrinal Kalakrishnan, Julian Ibarz, Peter Pastor, Sergey Levine and the complete Everyday Robots group.
[ad_2]