
{kind=link}
[ad_1]
This week two new, however contrasting AI-driven graphics algorithms are providing novel methods for finish customers to make extremely granular and efficient adjustments to things in pictures.
The first is Imagic, from Google Research, in affiliation with Israel’s Institute of Technology and Weizmann Institute of Science. Imagic presents text-conditioned, fine-grained modifying of objects by way of the fine-tuning of diffusion fashions.

Change what you want, and depart the remaining – Imagic guarantees granular modifying of solely the components that you just wish to be modified. Source: https://arxiv.org/pdf/2210.09276.pdf
Anyone who has ever tried to alter only one factor in a Stable Diffusion re-render will know solely too nicely that for each profitable edit, the system will change 5 issues that you just appreciated simply the best way they have been. It’s a shortcoming that at the moment has lots of the most gifted SD lovers always shuffling between Stable Diffusion and Photoshop, to repair this type of ‘collateral damage’. From this standpoint alone, Imagic’s achievements appear notable.
At the time of writing, Imagic as but lacks even a promotional video, and, given Google’s circumspect angle to releasing unfettered picture synthesis instruments, it’s unsure to what extent, if any, we’ll get an opportunity to check the system.
The second providing is Runway ML’s slightly extra accessible Erase and Replace facility, a new characteristic within the ‘AI Magic Tools’ part of its solely on-line suite of machine studying-based visible results utilities.
Runway ML’s Erase and Replace characteristic, already seen in a preview for a text-to-video modifying system. Source: https://www.youtube.com/watch?v=41Qb58ZPO60
Let’s check out Runway’s outing first.
Erase and Replace
Like Imagic, Erase and Replace offers solely with nonetheless photos, although Runway has previewed the identical performance in a text-to-video modifying resolution that’s not but launched:

Though anybody can take a look at out the brand new Erase and Replace on photos, the video model shouldn’t be but publicly accessible. Source: https://twitter.com/runwayml/status/1568220303808991232
Though Runway ML has not launched particulars of the applied sciences behind Erase and Replace, the pace at which you’ll substitute a home plant with a fairly convincing bust of Ronald Reagan suggests {that a} diffusion mannequin similar to Stable Diffusion (or, far much less seemingly, a licensed-out DALL-E 2) is the engine that’s reinventing the item of your alternative in Erase and Replace.

Replacing a home plant with a bust of The Gipper isn’t fairly as quick as this, nevertheless it’s fairly quick. Source: https://app.runwayml.com/
The system has some DALL-E 2 kind restrictions – photos or textual content that flag the Erase and Replace filters will set off a warning about attainable account suspension within the occasion of additional infractions – virtually a boilerplate clone of OpenAI’s ongoing insurance policies for DALL-E 2 .
Many of the outcomes lack the standard tough edges of Stable Diffusion. Runway ML are traders and analysis companions in SD, and it’s attainable that they’ve educated a proprietary mannequin that’s superior to the open supply 1.4 checkpoint weights that the remainder of us are at the moment wrestling with (as many different improvement teams, hobbyist {and professional} alike, are at the moment coaching or fine-tuning Stable Diffusion fashions).
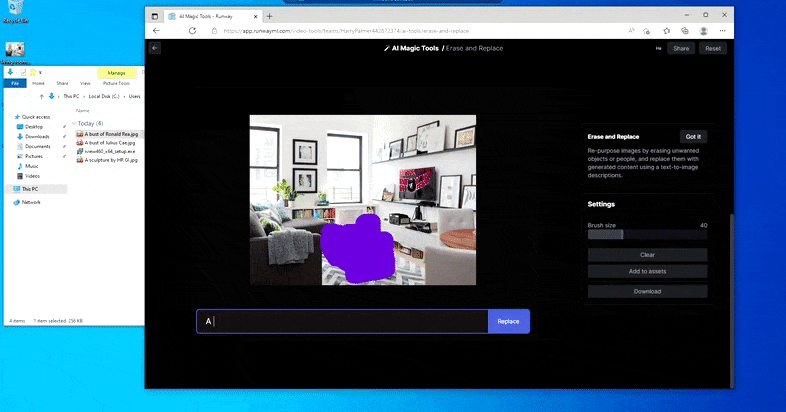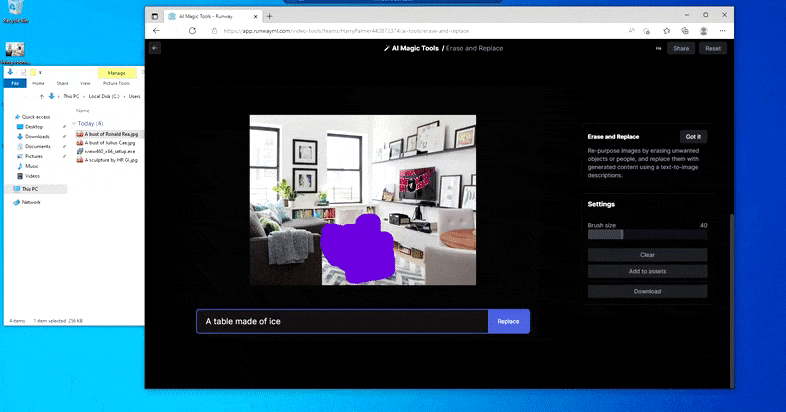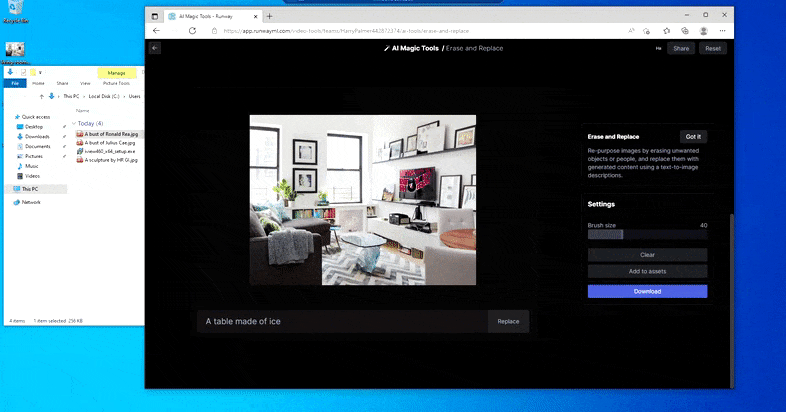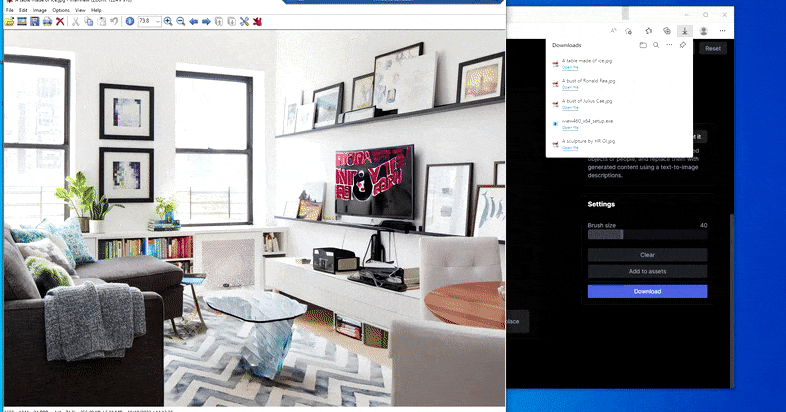
Substituting a home desk for a ‘table made of ice’ in Runway ML’s Erase and Replace.
As with Imagic (see beneath), Erase and Replace is ‘object-oriented’, because it have been – you possibly can’t simply erase an ’empty’ a part of the image and inpaint it with the results of your textual content immediate; in that state of affairs, the system will merely hint the closest obvious object alongside the masks’s line-of-sight (similar to a wall, or a tv), and apply the transformation there.
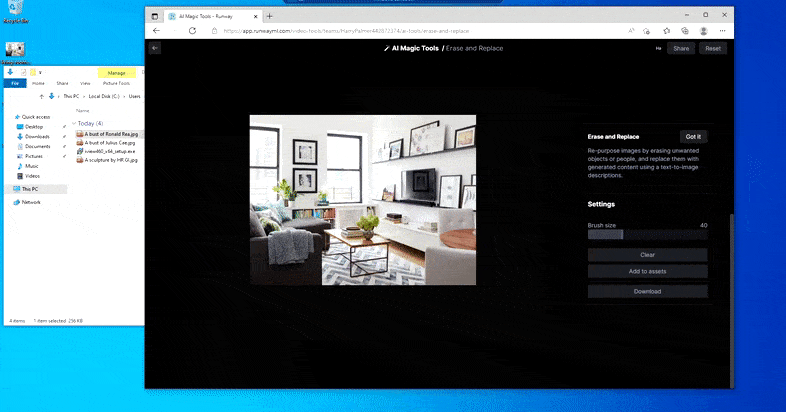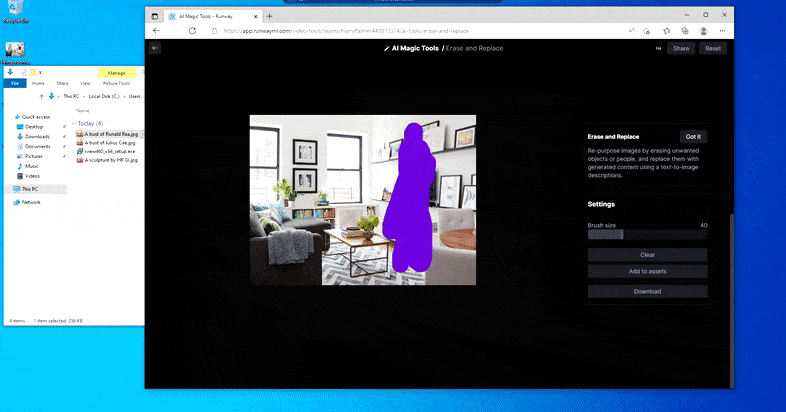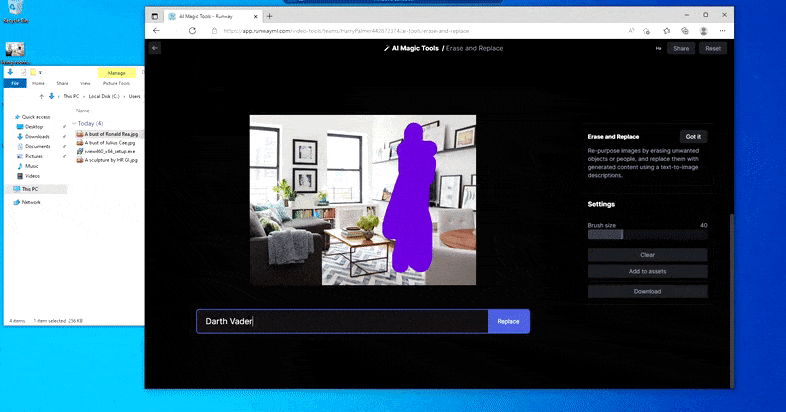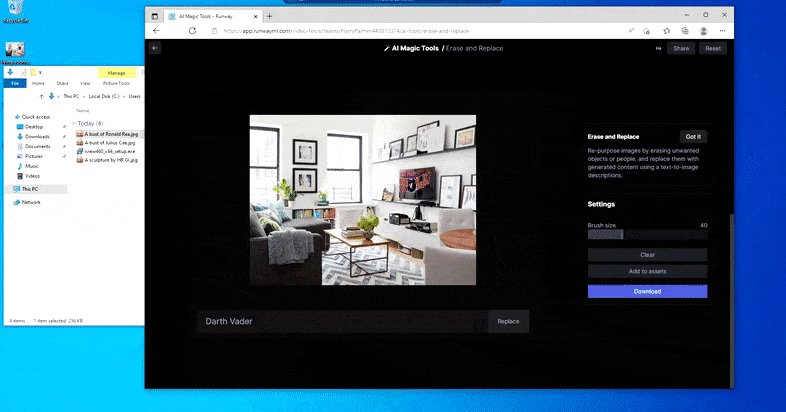
As the title signifies, you possibly can’t inject objects into empty area in Erase and Replace. Here, an effort to summon up essentially the most well-known of the Sith lords leads to an odd Vader-related mural on the TV, roughly the place the ‘replace’ space was drawn.
It is troublesome to inform if Erase and Replace is being evasive in regard to the usage of copyrighted photos (that are nonetheless largely obstructed, albeit with various success, in DALL-E 2), or if the mannequin getting used within the backend rendering engine is simply not optimized for that form of factor.

The barely NSFW ‘Mural of Nicole Kidman’ signifies that the (presumably) diffusion-based mannequin at hand lacks DALL-E 2’s former systematic rejection of rendering lifelike faces or racy content material, whereas the outcomes for makes an attempt to evince copyrighted works vary from the ambiguous (‘xenomorph’) to the absurd (‘the iron throne’). Inset backside proper, the supply image.
It can be fascinating to know what strategies Erase and Replace is utilizing to isolate the objects that it’s able to changing. Presumably the picture is being run by some derivation of CLIP, with the discrete objects individuated by object recognition and subsequent semantic segmentation. None of those operations work anyplace close to as nicely in a common-or-garden set up of Stable Diffusion.
But nothing’s good – typically the system appears to erase and never exchange, even when (as we have now seen within the picture above), the underlying rendering mechanism positively is aware of what a textual content immediate means. In this case, it proves unattainable to show a espresso desk right into a xenomorph – slightly, the desk simply disappears.
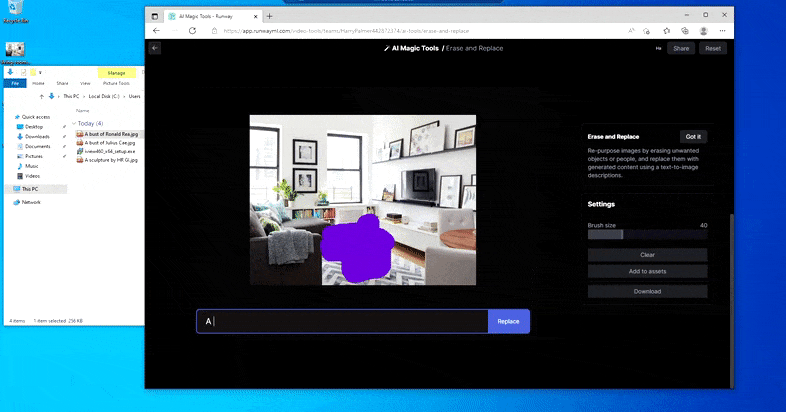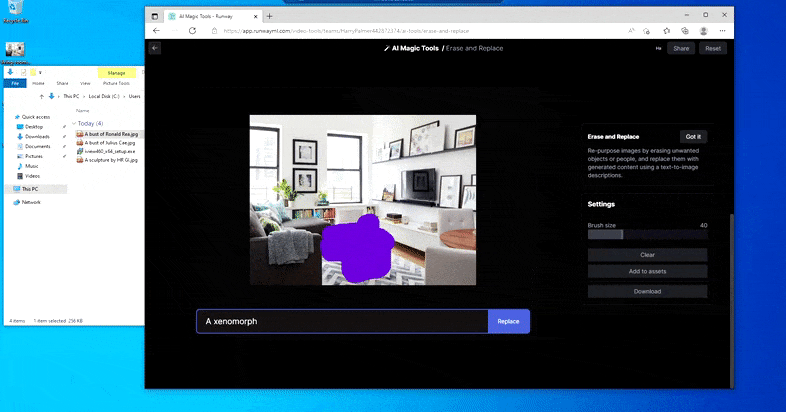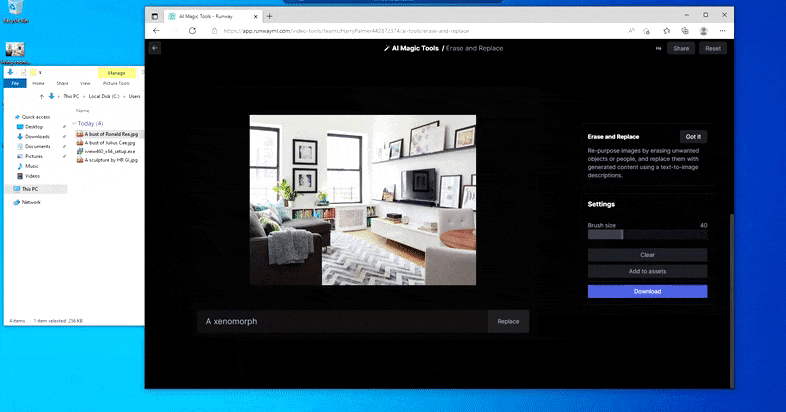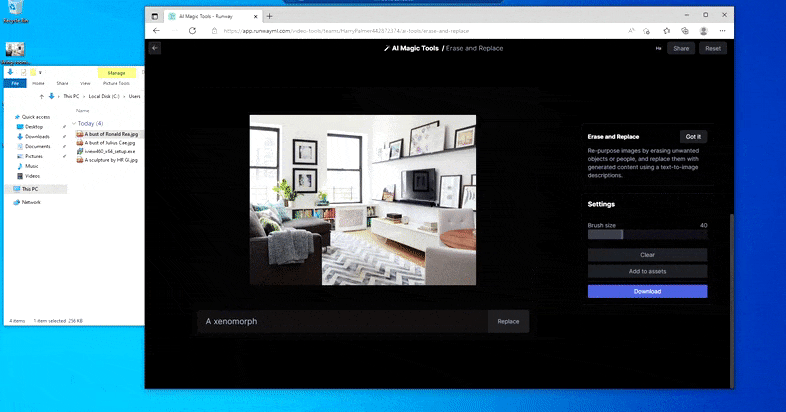
A scarier iteration of ‘Where’s Waldo’, as Erase and Replace fails to supply an alien.
Erase and Replace seems to be an efficient object substitution system, with wonderful inpainting. However, it might’t edit current perceived objects, however solely exchange them. To truly alter current picture content material with out compromising ambient materials is arguably a far tougher job, certain up with the pc imaginative and prescient analysis sector’s lengthy wrestle in the direction of disentanglement within the varied latent areas of the favored frameworks.
Imagic
It’s a job that Imagic addresses. The new paper presents quite a few examples of edits that efficiently amend particular person aspects of a photograph whereas leaving the remainder of the picture untouched.

In Imagic, the amended photos don’t endure from the attribute stretching, distortion and ‘occlusion guessing’ attribute of deepfake puppetry, which makes use of restricted priors derived from a single picture.
The system employs a three-stage course of – textual content embedding optimization; mannequin fine-tuning; and, lastly, the technology of the amended picture.

Imagic encodes the goal textual content immediate to retrieve the preliminary textual content embedding, after which optimizes the consequence to acquire the enter picture. After that, the generative mannequin is fine-tuned to the supply picture, including a variety of parameters, earlier than being subjected to the requested interpolation.
Unsurprisingly, the framework relies on Google’s Imagen text-to-video structure, although the researchers state that the system’s rules are broadly relevant to latent diffusion fashions.
Imagen makes use of a three-tier structure, slightly than the seven-tier array used for the corporate’s newer text-to-video iteration of the software program. The three distinct modules comprise a generative diffusion mannequin working at 64x64px decision; a super-resolution mannequin that upscales this output to 256x256px; and a further super-resolution mannequin to take output all the best way as much as 1024×1024 decision.
Imagic intervenes on the earliest stage of this course of, optimizing the requested textual content embedding on the 64px stage on an Adam optimizer at a static studying charge of 0.0001.

A master-class in disentanglement: these end-users which have tried to alter one thing so simple as the colour of a rendered object in a diffusion, GAN or NeRF mannequin will know the way important it’s that Imagic can carry out such transformations with out ‘tearing apart’ the consistency of the remainder of the picture.
Fine tuning then takes place on Imagen’s base mannequin, for 1500 steps per enter picture, conditioned on the revised embedding. At the identical time, the secondary 64px>256px layer is optimized in parallel on the conditioned picture. The researchers observe {that a} comparable optimization for the ultimate 256px>1024px layer has ‘little to no effect’ on the ultimate outcomes, and due to this fact haven’t applied this.
The paper states that the optimization course of takes roughly eight minutes for every picture on twin TPUV4 chips. The ultimate render takes place in core Imagen underneath the DDIM sampling scheme.
In frequent with comparable fine-tuning processes for Google’s DreamBooth, the ensuing embeddings can moreover be used to energy stylization, in addition to photorealistic edits that comprise info drawn from the broader underlying database powering Imagen (since, as the primary column beneath reveals, the supply photos wouldn’t have any of the mandatory content material to impact these transformations).

Flexible photoreal motion and edits will be elicited by way of Imagic, whereas the derived and disentangled codes obtained within the course of can as simply be used for stylized output.
The researchers in contrast Imagic to prior works SDEdit, a GAN-based strategy from 2021, a collaboration between Stanford University and Carnegie Mellon University; and Text2Live, a collaboration, from April 2022, between the Weizmann Institute of Science and NVIDIA.

A visible comparability between Imagic, SDEdit and Text2Live.
It’s clear that the previous approaches are struggling, however within the backside row, which includes interjecting a large change of pose, the incumbents fail utterly to refigure the supply materials, in comparison with a notable success from Imagic.
Imagic’s useful resource necessities and coaching time per picture, whereas quick by the requirements of such pursuits, makes it an unlikely inclusion in an area picture modifying software on private computer systems – and it isn’t clear to what extent the method of fine-tuning may very well be scaled all the way down to shopper ranges.
As it stands, Imagic is a formidable providing that’s extra suited to APIs – an surroundings Google Research, chary of criticism in regard to facilitating deepfaking, might in any case be most comfy with.
First printed 18th October 2022.
[ad_2]