
{kind=link}
[ad_1]

Sharing data is important to Google’s analysis philosophy — it accelerates technological progress and expands capabilities community-wide. Solving complicated issues requires bringing collectively various minds and assets collaboratively. This may be achieved by constructing native and world connections with multidisciplinary specialists and impacted communities. In partnership with these stakeholders, we carry our technical management, product footprint, and assets to make progress in opposition to a few of society’s biggest alternatives and challenges.
We at Google see it as our accountability to disseminate our work as contributing members of the scientific group and to assist prepare the subsequent technology of researchers. To do that properly, collaborating with specialists and researchers outdoors of Google is important. In truth, simply over half of our scientific publications spotlight work completed collectively with authors outdoors of Google. We are grateful to work collaboratively throughout the globe and have solely elevated our efforts with the broader analysis group over the previous 12 months. In this put up, we are going to speak about a few of the alternatives afforded by such partnerships, together with:
Addressing social challenges collectively
Engaging the broader group helps us progress on seemingly intractable issues. For instance, entry to well timed, correct well being info is a major problem amongst girls in rural and densely populated city areas throughout India. To remedy this problem, ARMMAN developed mMitra, a free cellular service that sends preventive care info to expectant and new moms. Adherence to such public well being applications is a prevalent problem, so researchers from Google Research and the Indian Institute of Technology, Madras labored with ARMMAN to design an ML system that alerts healthcare suppliers about members vulnerable to dropping out of the well being info program. This early identification helps ARMMAN present better-targeted help, improving maternal well being outcomes.
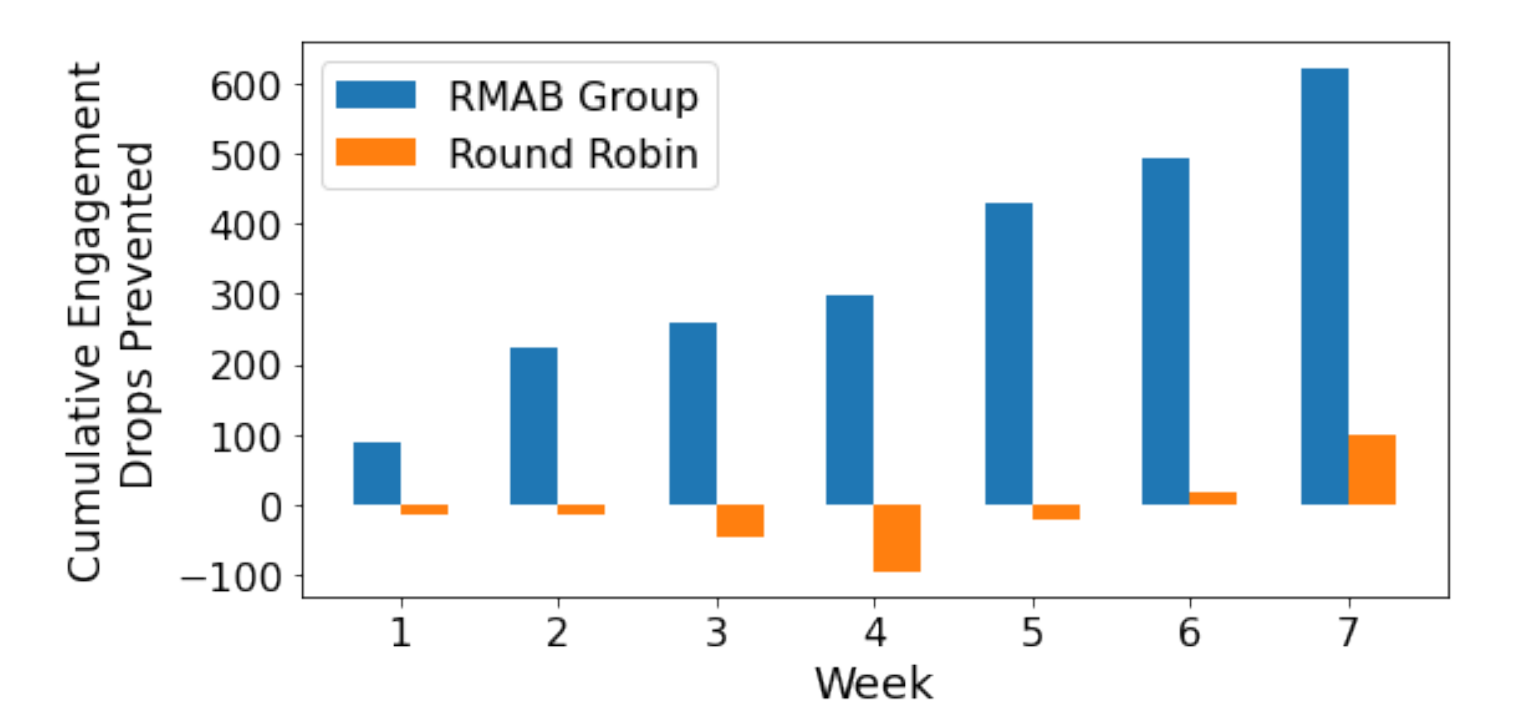 |
| Google Research labored with ARMMAN to design a system to alert healthcare suppliers about members in danger for dropping out of their preventative care info program for expectant moms. This plot reveals the cumulative engagement drops prevented utilizing our stressed multi-armed bandit mannequin (RMAB) in comparison with the management group (Round Robin). |
We additionally help Responsible AI initiatives instantly for different organizations — together with our commitment of $3M to fund the brand new INSAIT analysis heart based mostly in Bulgaria. Further, to assist construct a basis of equity, interpretability, privateness, and safety, we’re supporting the institution of a first-of-its-kind multidisciplinary Center for Responsible AI with a grant of $1M to the Indian Institute of Technology, Madras.
Training the subsequent technology of researchers
Part of our accountability in guiding how know-how impacts society is to assist prepare the subsequent technology of researchers. For instance, supporting equitable pupil persistence in computing analysis by our Computer Science Research Mentorship Program, the place Googlers have mentored over one thousand college students since 2018 — 86% of whom establish as a part of a traditionally marginalized group.
We work in direction of inclusive targets and work throughout the globe to attain them. In 2022, we expanded our analysis interactions and applications to college and college students throughout Latin America, which included grants to girls in laptop science in Ecuador. We partnered with ENS, a college in France, to assist fund scholarships for college kids to coach by analysis. Another instance is our collaboration with the Computing Alliance of Hispanic-Serving Institutions (CAHSI) to offer $4.8 million to help greater than 30 collaborative analysis initiatives and over 3,000 Hispanic college students and school throughout a community of Hispanic-serving establishments.
Efforts like these foster the analysis ecosystem and assist the group give again. Through exploreCSR, we accomplice with universities to offer college students with introductory experiences in analysis, corresponding to Rice University’s regional workshop on purposes and analysis in information science (ReWARDS), which was delivered in rural Peru by college from Rice. Similarly, one in all our Awards for Inclusion Research led to a college member serving to startups in Africa use AI.
The funding we offer is most frequently unrestricted and results in inspiring outcomes. Last 12 months, for instance, Kean University was one in all 53 establishments to obtain an exploreCSR award. It used the funding to create the Research Recruits Program, a two-semester program designed to provide undergraduates an introductory alternative to take part in analysis with a college mentor. A pupil at Kean with a persistent situation that requires him to take totally different medicines on daily basis, a battle that impacts so many, determined to pursue analysis on the subject with a peer. Their analysis, set to be printed this 12 months, demonstrates an ML resolution, constructed with Google’s TensorFlow, that may establish capsules with 99.8% certainty when used accurately. Results like these are why we proceed to put money into youthful generations, additional demonstrated by our long-term dedication to funding PhD Fellows yearly throughout the globe.
Building an inclusive ecosystem is crucial. To this finish, we have additionally partnered with the non-profit Black in Robotics (BiR), shaped to deal with the systemic inequities within the robotics group. Together, we established doctoral pupil awards that assist financially help graduate college students and to help BiR’s newly established Bay Area Robotics lab. We additionally assist make world conferences accessible to extra researchers world wide, for instance, by funding 24 college students this 12 months to attend Deep Learning Indaba in Tunisia.
Collaborating to advance scientific improvements
In 2022 Google sponsored over 150 analysis conferences and much more workshops, which results in invaluable engagements with the broader analysis group. At analysis conferences, Googlers serve on program committees and set up workshops, tutorials and quite a few different actions to collectively advance the sector. Additionally, final 12 months, we hosted over 14 devoted workshops to carry collectively researchers, such because the 2022 Quantum Symposium, which generates new concepts and instructions for the analysis discipline, additional advancing analysis initiatives. In 2022, we authored 2400 papers, a lot of which had been introduced at main analysis conferences, corresponding to NeurIPS, EMNLP, ECCV, Interspeech, ICML, CVPR, ICLR, and plenty of others. More than 50% of those papers had been authored in collaboration with researchers past Google.
Over the previous 12 months, we have expanded our engagement fashions to facilitate college students, college, and Google’s analysis scientists coming collectively throughout colleges to type constructive analysis triads. One such mission, undertaken in partnership with college and college students from Georgia Tech, goals to develop a robotic information canine with human conduct modeling and protected reinforcement studying. Throughout 2022, we gave over 224 grants to researchers and over $10M in Google Cloud Platform credit for subjects starting from the development of algorithms for post-quantum cryptography with collaborators at CNRS in France to fostering cybersecurity analysis at TU Munich and Fraunhofer AISEC in Germany.
In 2022, we made 22 new multi-year commitments totaling over ~$80M to 65 establishments throughout 9 nations, the place annually we are going to host workshops to pick over 100 analysis initiatives of mutual curiosity. For instance, in a rising partnership, we’re supporting the brand new Max Planck VIA-Center in Germany to work collectively on robotics. Another giant space of funding is a detailed partnership with 4 universities in Taiwan (NTU, NCKU, NYCU, NTHU) to extend innovation in silicon chip design and enhance competitiveness in semiconductor design and manufacturing. We intention to collaborate by default and had been proud to be not too long ago named one in all Australia’s prime collaborating firms.
Fueling innovation in merchandise and engineering
The group fuels innovation at Google. For instance, by facilitating pupil researchers to work with us on outlined analysis initiatives, we have skilled each incremental and extra dramatic enhancements. Together with visiting researchers, we mix info, compute energy, and quite a lot of experience to result in breakthroughs, corresponding to leveraging our undersea web cables to detect earthquakes. Visiting Researchers additionally labored hand-in-hand with us to develop Minerva, a state-of-the-art resolution that took place by coaching a deep studying mannequin on a dataset that accommodates quantitative reasoning with symbolic expressions.
 |
| Minerva incorporates latest prompting and analysis methods to raised remedy mathematical questions. It then employs majority voting, wherein it generates a number of options to every query and chooses the most typical reply as the answer, thus enhancing efficiency considerably. |
Open-sourcing datasets and instruments
Engaging with the broader analysis group is a core a part of our efforts to construct a extra collaborative ecosystem. We help the final development of ML and associated analysis by the discharge of open-source code and datasets. We continued to develop open supply datasets in 2022, for instance, in pure language processing and imaginative and prescient, and expanded our world index of obtainable datasets in Google Dataset Search. We additionally continued to launch sustainability information through Data Commons and invite others to make use of it for his or her analysis. See a few of the datasets and instruments we launched in 2022 listed beneath.
| Dataset | Description |
| Auto-Arborist | A multiview city tree classification dataset that consists of ~2.6M bushes masking >320 genera, which may help within the growth of fashions for city forest monitoring. |
| Bazel GitHub Metrics | A dataset with GitHub obtain counts of launch artifacts from chosen bazelbuild repositories. |
| BC-Z demonstration | Episodes of a robotic arm performing 100 totally different manipulation duties. Data for every episode consists of the RGB video, the robotic’s end-effector positions, and the pure language embedding. |
| BEGIN V2 | A benchmark dataset for evaluating dialog programs and pure language technology metrics. |
| CLSE: Corpus of Linguistically Significant Entities | A dataset of named entities annotated by linguistic specialists. It consists of 34 languages and 74 totally different semantic sorts to help varied purposes from airline ticketing to video video games. |
| CocoChorales | A dataset consisting of over 1,400 hours of audio mixtures containing four-part chorales carried out by 13 devices, all synthesized with realistic-sounding generative fashions. |
| Crossmodal-3600 | A geographically various dataset of three,600 pictures, every annotated with human-generated reference captions in 36 languages. |
| CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus | A Common Voice-based Speech-to-Speech translation corpus that features 2,657 hours of speech-to-speech translation sentence pairs from 21 languages into English. |
| DSTC11 Challenge Task | This problem evaluates task-oriented dialog programs end-to-end, from customers’ spoken utterances to inferred slot values. |
| EditBench | A complete diagnostic and analysis dataset for text-guided picture enhancing. |
| Few-shot Regional Machine Translation | FRMT is a few-shot analysis dataset containing en-pt and en-zh bitexts translated from Wikipedia, in two regional varieties for every non-English language (pt-BR and pt-PT; zh-CN and zh-TW). |
| Google Patent Phrase Similarity | A human-rated contextual phrase-to-phrase matching dataset centered on technical phrases from patents. |
| Hinglish-TOP | Hinglish-TOP is the most important code-switched semantic parsing dataset with 10k entries annotated by people, and 170K generated utterances utilizing the CST5 augmentation approach launched within the paper. |
| ImPaKT | A dataset that accommodates semantic parsing annotations for two,489 sentences from purchasing internet pages within the C4 corpus, comparable to annotations of three,719 expressed implication relationships and 6,117 typed and summarized attributes. |
| InFormal | A formality model switch dataset for 4 Indic Languages, made up of a pair of sentences and a corresponding gold label figuring out the extra formal and semantic similarity. |
| MAVERICS | A collection of test-only visible query answering datasets, created from Visual Question Answering picture captions with query answering validation and handbook verification. |
| MetaPose | A dataset with 3D human poses and digital camera estimates predicted by the MetaPose mannequin for a subset of the general public Human36M dataset with enter information vital to breed these outcomes from scratch. |
| MGnify proteins | A 2.4B-sequence protein database with annotations. |
| MiQA: Metaphorical Inference Questions and Answers | MiQA assesses the aptitude of language fashions to motive with standard metaphors. It combines the beforehand remoted subjects of metaphor detection and commonsense reasoning right into a single activity that requires a mannequin to make inferences by choosing between the literal and metaphorical register. |
| MT-Opt | A dataset of activity episodes collected throughout a fleet of actual robots, following the RLDS format to symbolize steps and episodes. |
| MultiBERTs Predictions on Winogender | Predictions of BERT on Winogender earlier than and after a number of totally different interventions. |
| Natural Language Understanding Uncertainty Evaluation | NaLUE is a relabelled and aggregated model of three giant NLU corpuses CLINC150, Banks77 and HWU64. It accommodates 50k utterances spanning 18 verticals, 77 domains, and ~260 intents. |
| NewsStories | A set of url hyperlinks to publicly accessible information articles with their related pictures and movies. |
| Open Images V7 | Open Images V7 expands the Open Images dataset with new point-level label annotations, which offer localization info for five.8k courses, and a brand new all-in-one visualization software for higher information exploration. |
| Pfam-NUniProt2 | A set of 6.8 million new protein sequence annotations. |
| Re-contextualizing Fairness in NLP for India | A dataset of area and religion-based societal stereotypes in India, with an inventory of identification phrases and templates for reproducing the outcomes from the “Re-contextualizing Fairness in NLP” paper. |
| Scanned Objects | A dataset with 1,000 frequent family objects which have been 3D scanned to be used in robotic simulation and artificial notion analysis. |
| Specialized Rater Pools | This dataset comes from a research designed to know whether or not annotators with totally different self-described identities interpret toxicity in a different way. It accommodates the unaggregated toxicity annotations of 25,500 feedback from swimming pools of raters who self-identify as African American, LGBTQ, or neither. |
| UGIF | A multi-lingual, multi-modal UI grounded dataset for step-by-step activity completion on the smartphone. |
| UniProt Protein Names | Data launch of ~49M protein title annotations predicted from their amino acid sequence. |
| upwelling irradiance from GOES-16 | Climate researchers can use the 4 years of outgoing longwave radiation and mirrored shortwave radiation information to research essential local weather forcers, corresponding to plane condensation trails. |
| UserLibri | The UserLibri dataset reorganizes the prevailing in style LibriSpeech dataset into particular person “user” datasets consisting of paired audio-transcript examples and domain-matching text-only information for every person. This dataset can be utilized for analysis in speech personalization or different language processing fields. |
| VideoCC | A dataset containing (video-URL, caption) pairs for coaching video-text machine studying fashions. |
| Wiki-conciseness | A manually curated analysis set in English for concise rewrites of two,000 Wikipedia sentences. |
| Wikipedia Translated Clusters | Introductions to English Wikipedia articles and their parallel variations in 10 different languages, with machine translations to English. Also consists of artificial corruptions to the English variations, to be recognized with NLI fashions. |
| Workload Traces 2022 | A dataset with traces that intention to assist system designers higher perceive warehouse-scale computing workloads and develop new options for front-end and data-access bottlenecks. |
| Tool | Description |
| Differential Privacy Open Source Library | An open-source library to allow builders to make use of analytic methods based mostly on DP. |
| Mood Board Search | The results of collaborative work with artists, photographers, and picture researchers to show how ML can allow individuals to visually discover subjective ideas in picture datasets. |
| Project Relate | An Android beta app that makes use of ML to assist individuals with non-standard speech make their voices heard. |
| TensorStore | TensorStore is an open-source C++ and Python library designed for storage and manipulation of n-dimensional information, which may tackle key engineering challenges in scientific computing by higher administration and processing of enormous datasets. |
| The Data Cards Playbook | A Toolkit for Transparency in Dataset Documentation. |
Conclusion
Research is an amplifier, an accelerator, and an enabler — and we’re grateful to accomplice with so many unbelievable individuals to harness it for the nice of humanity. Even when investing in analysis that advances our merchandise and engineering, we acknowledge that, finally, this fuels what we will supply our customers. We welcome extra companions to have interaction with us and maximize the advantages of AI for the world.
Acknowledgements
Thank you to our many analysis companions throughout the globe, together with lecturers, universities, NGOs, and analysis organizations, for persevering with to have interaction and work with Google on thrilling analysis efforts. There are many groups inside GoogIe who make this work attainable, together with Google’s analysis groups and group, analysis partnerships, training, and coverage groups. Finally, I’d particularly wish to thank those that offered useful suggestions within the growth of this put up, together with Sepi Hejazi Moghadam, Jill Alvidrez, Melanie Saldaña, Ashwani Sharma, Adriana Budura Skobeltsyn, Aimin Zhu, Michelle Hurtado, Salil Banerjee and Esmeralda Cardenas.
Google Research, 2022 & past
This was the ninth and ultimate weblog put up within the “Google Research, 2022 & Beyond” sequence. Other posts on this sequence are listed within the desk beneath:
[ad_2]