
{kind=link}
[ad_1]
Great machine studying (ML) analysis requires nice methods. With the growing sophistication of the algorithms and {hardware} in use right this moment and with the dimensions at which they run, the complexity of the software program essential to hold out day-to-day duties solely will increase. In this submit, we offer an summary of the quite a few advances made throughout Google this previous yr in methods for ML that allow us to help the serving and coaching of complicated fashions whereas easing the complexity of implementation for finish customers. This weblog submit additionally highlights our analysis on leveraging ML itself to assist enhance and design the subsequent generations of system stacks.
Distributed methods for ML
This yr, we have made vital strides in bettering our methods to raised help large-scale computation in ML and scientific computing on the whole. The Google TPU {hardware} has been designed with scaling in thoughts since its inception, and every year we attempt to push the boundaries even additional. This yr, we designed state-of-the-art serving methods for giant fashions, improved computerized partitioning of tensor packages and reworked the APIs of our libraries to verify all of these developments are accessible to a large viewers of customers.
One of our greatest effectivity enhancements this yr is the CollectiveEinsum technique for evaluating the massive scale matrix multiplication operations which can be on the coronary heart of neural networks. Unlike beforehand well-liked SPMD partitioning methods that separate communication from device-local computation, this strategy makes use of the quick TPU ICI hyperlinks to overlap them, resulting in as much as 1.38x efficiency enhancements. This algorithm was additionally a key part of our work on efficiently scaling Transformer inference, which presents all kinds of methods that commerce off between latency and {hardware} utilization, reaching state-of-the-art mannequin FLOPs utilization (MFU) of 76% in throughput-optimized configurations.
 |
| An illustration of AllGather-Einsum with 2-way intra-layer mannequin parallelism, proposed in CollectiveEinsum technique. Top: Illustration of non-overlapped execution. Bottom: Illustration of the CollectiveEinsum method. |
We have additionally built-in SPMD-style partitioning as a firstclass idea into each TensorFlow, with the DTensor extension, and JAX, with the redesigned array kind. In each libraries, tensors that appear full to the programmer may be transparently sharded over quite a few gadgets simply by attaching declarative structure annotations. In truth, each approaches are suitable with present code written for single-device computations that may now scale right into a multi-device program, normally with none code modifications!
Integrating SPMD partitioning into the core of our ML frameworks implies that with the ability to infer and optimize the way in which array packages are mapped onto a bigger set of gadgets is vital for efficiency. In the previous, this motivated the event of GSPMD, an vital milestone on this space. However, GSPMD depends closely on heuristics, and it nonetheless typically requires non-trivial selections to be made manually, which frequently ends in suboptimal efficiency. To make partitioning inference totally computerized, we collaborated with exterior colleagues to develop Alpa, a totally automated system that explores methods for each operator-level (mannequin) parallelism and pipeline parallelism between bigger sub-computations. It efficiently matches hand-tuned efficiency on well-liked fashions corresponding to Transformers, however can be able to efficiently scaling up different fashions, corresponding to convolutional networks and mixture-of-experts fashions that always trigger present automated strategies to battle.
 |
| Alpa overview. The inter-operator identifies one of the best ways to assign a subgraph to a submesh. The intra-operator move finds the most effective intra-operator parallelism plan for every pipeline stage. Finally, the runtime orchestration generates a static plan that orders the computation and communication. |
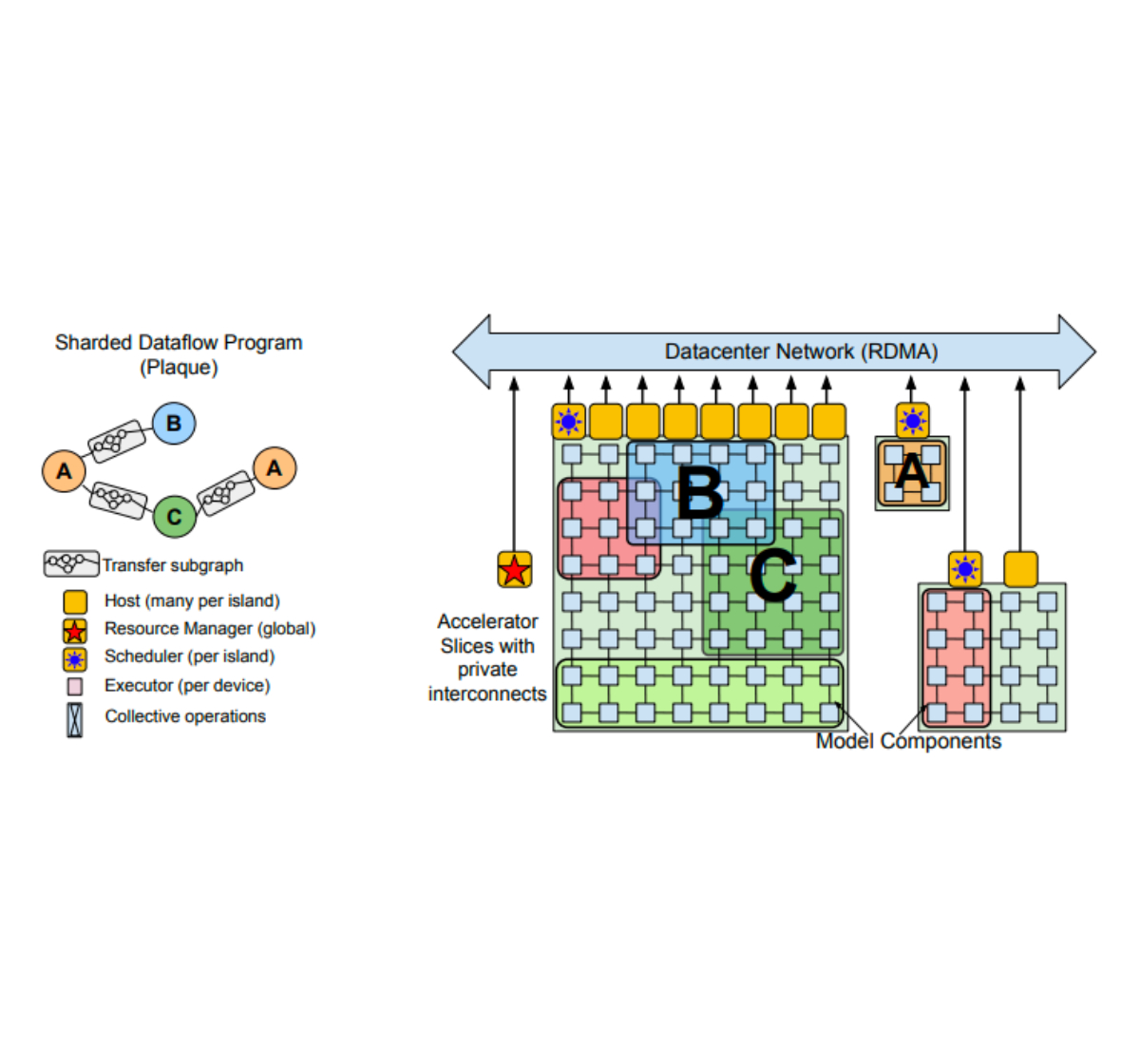
In an identical vein, the just lately revealed Pathways system provides a further layer of virtualization on high of the standard TPU runtime — accelerators are managed by long-lived processes as an alternative of being allotted on to customers. A single finish consumer can then hook up with an arbitrary variety of Pathways-controlled gadgets and write their program as if all of the gadgets had been connected on to their course of, regardless that in actuality they might even span a number of knowledge facilities. Thanks to Pathways: (1) job startup time may be decreased, (2) it’s simpler to realize fault tolerance, and (3) multitenancy turns into a viable choice, enabling a number of jobs to be executed concurrently for much more environment friendly {hardware} utilization. The ease with which Pathways permits computation spanning a number of TPU pods is essential, because it lets us keep away from future scaling bottlenecks.
 |
| Pathways overview. Top Left: Distributed computation expressed as a Directed Acyclic Graph. Top Right: The useful resource supervisor allocates digital slices of accelerator meshes for every compiled operate (e.g., A, B, and C). Bottom: Centralized schedulers for gang-schedule computations which can be then dispatched by per-shard executors. (See paper for particulars.) |
Another notable launch is TensorStore, a brand new library for multi-dimensional array storage. TensorStore is especially helpful for coaching giant language fashions (LLMs) with multi-controller runtimes, the place each course of solely manages a subset of all parameters, all of which have to be collated right into a constant checkpoint. TensorStore supplies database-grade ensures (ACID) for environment friendly and concurrent multi-dimensional array serialization into many storage backends (e.g., Google Cloud Storage, numerous filesystems, HTTP servers) and has been efficiently used for compute-intensive workloads corresponding to PaLM and reconstructions of the human cortex and fruit fly mind.
Programming languages for ML
The robustness and correctness of our technical infrastructure are very important for ML efforts, which is why we stay dedicated to making sure that it’s constructed on a sound technical and theoretical foundation, backed by cutting-edge analysis in programming languages and compiler building.
We continued investing within the open-source MLIR compiler infrastructure, constructing a extra controllable, composable and modular compiler stack. In addition, a lot progress has been made in code era for sparse linear algebra and it’s now attainable to generate each dense and sparse code from virtually similar MLIR packages. Finally, we additionally continued the event of the IREE compiler, making ready it to be used on each highly effective computer systems situated in knowledge facilities and cellular gadgets corresponding to smartphones.
On the extra theoretical facet we explored methods to formalize and confirm the code-generation methods we use. We additionally revealed a novel strategy used to implement and formalize automatic differentiation (AD) methods, that are central to ML libraries. We decomposed the reverse-mode AD algorithm into three impartial program transformations, that are considerably less complicated and simpler to confirm, highlighting the distinctive options of JAX’s implementation.
Leveraging programming language methods, corresponding to summary interpretation and program synthesis, we efficiently decreased the variety of assets required to carry out a neural structure search (NAS). This effort, 𝛼NAS, led to the invention of extra environment friendly fashions with out degradation in accuracy.
In the previous yr, we revealed quite a few new open-source libraries within the JAX ecosystem, Rax and T5X being simply two examples. With the continued effort round jax2tf, JAX fashions can now be deployed on cellular gadgets utilizing TensorFlow Lite and on the net utilizing TensorFlow.js.
Hardware accelerators & ML
Hardware design for ML
The use of personalized {hardware}, corresponding to TPUs and GPUs, has proven great advantages when it comes to each efficiency acquire and vitality effectivity (therefore decreasing the carbon footprint). In a current MLPerf competitors, we set new efficiency information on 5 benchmarks on TPUs v4, reaching speedups which can be on common 1.42x greater than the subsequent quickest submission. However, with a purpose to sustain with current advances, we’re additionally creating personalized {hardware} architectures for particular well-liked fashions.
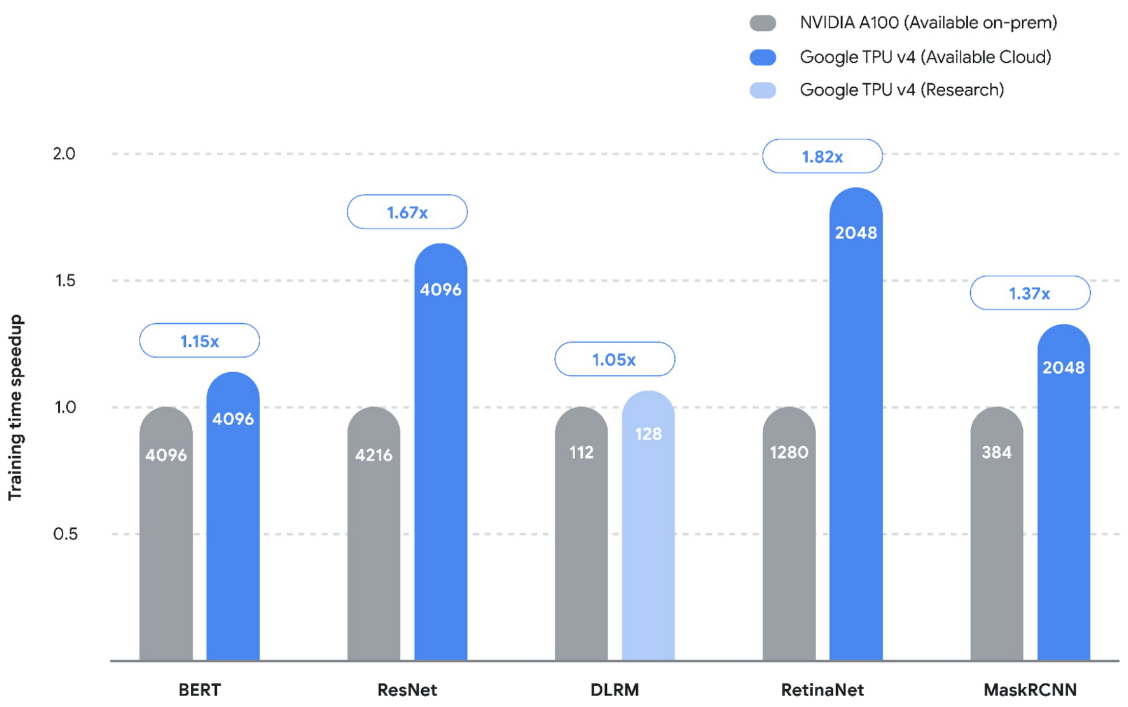 |
| TPUs demonstrated vital speedup in all 5 revealed benchmarks (MLPerf 2.0) over the quickest non-Google submission (NVIDIA on-premises). Taller bars are higher. The numbers contained in the bars signify the amount of chips / accelerators used for every of the submissions. |
However, constructing a brand new {hardware} accelerator incurs excessive preliminary price and requires vital growth and deployment time. To make single-workload accelerators viable, the design cycle time must be decreased. Full-stack Search Technique (FAST) addresses this drawback by introducing a {hardware} accelerator search framework that concurrently optimizes knowledge path, scheduling, and vital compiler selections. FAST introduces an approximate template able to describing various varieties of architectures and versatile reminiscence hierarchy leading to accelerators that enhance single-workload efficiency per Thermal Design Power (identified to extremely correlate with efficiency per Total Cost of Ownership) by 3.7x in comparison with TPU v3. This exhibits that single-workload accelerators may very well be sensible for moderate-sized datacenter deployments.
ML for {hardware} design
To automate the chip design course of as a lot as attainable, we proceed to push the capabilities of ML at numerous phases of the {hardware} design, together with high-level architectural exploration, verification, and placement and routing.
We just lately open-sourced a distributed RL infrastructure referred to as Circuit Training, together with a circuit surroundings described in our current Nature paper. We used this infrastructure in manufacturing to supply macro placements for the newest era of TPU chips. Tackling architectural exploration, PRIME introduces an ML-based strategy for looking {hardware} design house that makes use of solely present knowledge (e.g., from conventional accelerator design efforts) with none additional {hardware} simulation. This strategy alleviates the necessity to run time-consuming simulations, even when the set of goal purposes modifications. PRIME improves efficiency over state-of-the-art simulation-driven strategies by about 1.2x–1.5x whereas decreasing the simulation time by 93%–99%. AutoApprox mechanically generates approximate low-power deep studying accelerators with none accuracy loss by mapping every neural community layer to an acceptable approximation stage.
 |
| PRIME makes use of logged accelerator knowledge, consisting of each possible and infeasible accelerators, to coach a conservative mannequin, which is used to design accelerators whereas assembly design constraints. PRIME designs accelerators with as much as 1.5x smaller latency, whereas decreasing the required {hardware} simulation time by as much as 99%. |
Hardware-dependent mannequin design
While NAS has proven great functionality in discovering state-of-the-art fashions when it comes to accuracy and effectivity, it’s nonetheless restricted by lack of {hardware} information. Platform-aware NAS addresses this hole by incorporating information of the {hardware} structure into the design of the NAS search house. The ensuing EfficientNet-X mannequin is 1.5x–2x quicker than EfficientNet on TPU v3 and GPU v100, respectively, with comparable accuracy. Both platform-aware NAS and EfficientNet-X have been deployed in manufacturing, demonstrating vital accuracy good points and as much as ~40% effectivity enchancment for numerous manufacturing imaginative and prescient fashions. NaaS goes even additional by trying to find neural community architectures and {hardware} architectures collectively. Using this strategy on Edge TPUs, NaaS discovers imaginative and prescient fashions which can be 2x extra vitality environment friendly with the identical accuracy.
 |
| Overview of platform-aware NAS on TPUs/GPUs, highlighting the search house and search goals. |
ML for navigating constrained search areas
Apart from altering the {hardware} and the workload for higher effectivity, we will additionally optimize the center layer, together with the partitioner, which maps the workload onto a number of gadgets, and the compiler, which interprets the workload right into a low-level presentation understood by the {hardware}. In earlier years, we demonstrated how we will apply ML to search out higher machine placement and compiler selections. In the previous yr, we additional explored this path and located that many optimization search areas are closely constrained, the place legitimate options are fairly sparse.
To deal with this problem, we developed a number of methods to allow a realized mannequin to successfully navigate a constrained search house. Telamalloc employs a mix of ML mannequin plus heuristics to decide when a number of choices can be found, and leverages a constraint solver to deduce additional dependent selections. Telamalloc quickens the reminiscence allocation move within the Edge TPU compiler in comparison with a manufacturing Integer Linear Programming strategy and permits vital real-world fashions that might not in any other case be supported.
“A Transferable Approach for Partitioning Machine Learning Models on Multi-Chip-Modules” proposes a barely completely different strategy. It applies reinforcement studying (RL) to suggest the choices in a single step, and asks the constraint solver to regulate the proposed answer to be legitimate. For a BERT mannequin on an Edge TPU-based multi-chip mesh, this strategy discovers a greater distribution of the mannequin throughout gadgets utilizing a a lot smaller time price range in comparison with non-learned search methods.
ML for large-scale manufacturing methods
We additionally deployed ML to enhance effectivity of varied large-scale methods working in manufacturing. We just lately launched MLGO, the primary industrial-grade normal framework for integrating ML methods systematically within the LLVM infrastructure. MLGO can exchange heuristics in LLVM with an RL coverage to make optimization selections. When testing on a set of inside large-scale purposes, we discovered that the skilled coverage can scale back binary dimension by 3%–7% when optimizing inlining selections and may enhance throughput by 0.3% ~1.5% when optimizing register allocation selections. Within our manufacturing ML compiler, XLA, a realized price mannequin revealed a number of years again, was just lately deployed to information the collection of optimum tile sizes of TPU kernels for high ML workloads, saving ~2% of the whole TPU compute time in our knowledge facilities total.We additionally just lately changed an present heuristic in YouTube cache alternative algorithm with a brand new hybrid algorithm that mixes a easy heuristic with a realized mannequin, bettering byte miss ratio on the peak by ~9%.
 |
| Illustration of MLGO throughout inlining. “#bbs”, “#users”, and “callsite height” are instance caller-callee pair options. |
AI & sustainability
Given the worldwide local weather change disaster, there was comprehensible concern in regards to the environmental impression of ML. In a current paper, we confirmed that by following greatest practices, ML practitioners can scale back carbon dioxide equal emissions (CO2e) from coaching by orders of magnitude. We name the practices the “4Ms”
- Model. The first step is to pick probably the most environment friendly ML mannequin structure. For instance, Primer runs ~4x quicker on the identical {hardware} whereas reaching the identical high quality scores than the favored Transformer developed 4 years earlier.
- Machine. The second follow is to make use of probably the most vitality environment friendly laptop obtainable. For instance, when the Transformer mannequin was first revealed in 2017, a preferred GPU was the Nvidia P100. Using a current processor optimized for ML coaching, corresponding to TPU v4, improves efficiency per Watt by ~15x.
- Mechanization. Computers for coaching wanted to be housed in an information heart. Large cloud knowledge facilities are sometimes ~1.4x extra energy-efficient than the standard smaller on-premise knowledge heart.
- Map. The greatest shock in our investigation was the impression on the cleanliness of the vitality provide by selecting the most effective location. Moreover, within the cloud, location is the best of the 4 elements to alter. The distinction between a typical location and a effectively chosen location may be ~9x, even throughout the similar nation.
In this instance, multiplying the 4Ms collectively yields a 4x × 15x × 1.4x × 9x or ~750x discount in CO2e over 4 years by following the most effective practices over the coaching of the unique Transformer mannequin utilizing GPUs of 2017.
We are persevering with to discover this house and in 2023 we will probably be releasing an extra research that demonstrates tips on how to scale back the CO2e of present mannequin coaching by as much as 20x by rigorously choosing the machine, mechanization and placement of coaching.
Concluding ideas
As the sphere of ML advances, we proceed our funding in creating high-performance, energy-efficient, and easy-to-use methods and infrastructure to allow fast exploration of latest concepts. At the identical time, we proceed to discover the aptitude of ML to enhance the efficiency of complicated methods and automate labor-intensive duties in system design.
Google Research, 2022 & past
This was the second weblog submit within the “Google Research, 2022 & Beyond” sequence. Other posts on this sequence are listed within the desk under:
| * Articles will probably be linked as they’re launched. |
[ad_2]