
{kind=link}
[ad_1]
A lot has been written about struggles of deploying machine studying initiatives to manufacturing. As with many burgeoning fields and disciplines, we don’t but have a shared canonical infrastructure stack or greatest practices for growing and deploying data-intensive functions. That is each irritating for firms that would favor making ML an odd, fuss-free value-generating perform like software program engineering, in addition to thrilling for distributors who see the chance to create buzz round a brand new class of enterprise software program.
The brand new class is usually referred to as MLOps. Whereas there isn’t an authoritative definition for the time period, it shares its ethos with its predecessor, the DevOps motion in software program engineering: by adopting well-defined processes, fashionable tooling, and automatic workflows, we are able to streamline the method of shifting from improvement to strong manufacturing deployments. This strategy has labored nicely for software program improvement, so it’s cheap to imagine that it may deal with struggles associated to deploying machine studying in manufacturing too.

Be taught quicker. Dig deeper. See farther.
Nonetheless, the idea is kind of summary. Simply introducing a brand new time period like MLOps doesn’t remedy something by itself, somewhat, it simply provides to the confusion. On this article, we need to dig deeper into the basics of machine studying as an engineering self-discipline and description solutions to key questions:
- Why does ML want particular remedy within the first place? Can’t we simply fold it into present DevOps greatest practices?
- What does a contemporary expertise stack for streamlined ML processes appear to be?
- How are you able to begin making use of the stack in apply at this time?
Why: Information Makes It Completely different
All ML initiatives are software program initiatives. For those who peek below the hood of an ML-powered utility, as of late you’ll typically discover a repository of Python code. For those who ask an engineer to indicate how they function the applying in manufacturing, they may doubtless present containers and operational dashboards—not in contrast to some other software program service.
Since software program engineers handle to construct odd software program with out experiencing as a lot ache as their counterparts within the ML division, it begs the query: ought to we simply begin treating ML initiatives as software program engineering initiatives as common, possibly educating ML practitioners in regards to the present greatest practices?
Let’s begin by contemplating the job of a non-ML software program engineer: writing conventional software program offers with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly mannequin within the code. In impact, the engineer designs and builds the world whereby the software program operates.
In distinction, a defining function of ML-powered functions is that they’re instantly uncovered to a considerable amount of messy, real-world information which is just too complicated to be understood and modeled by hand.
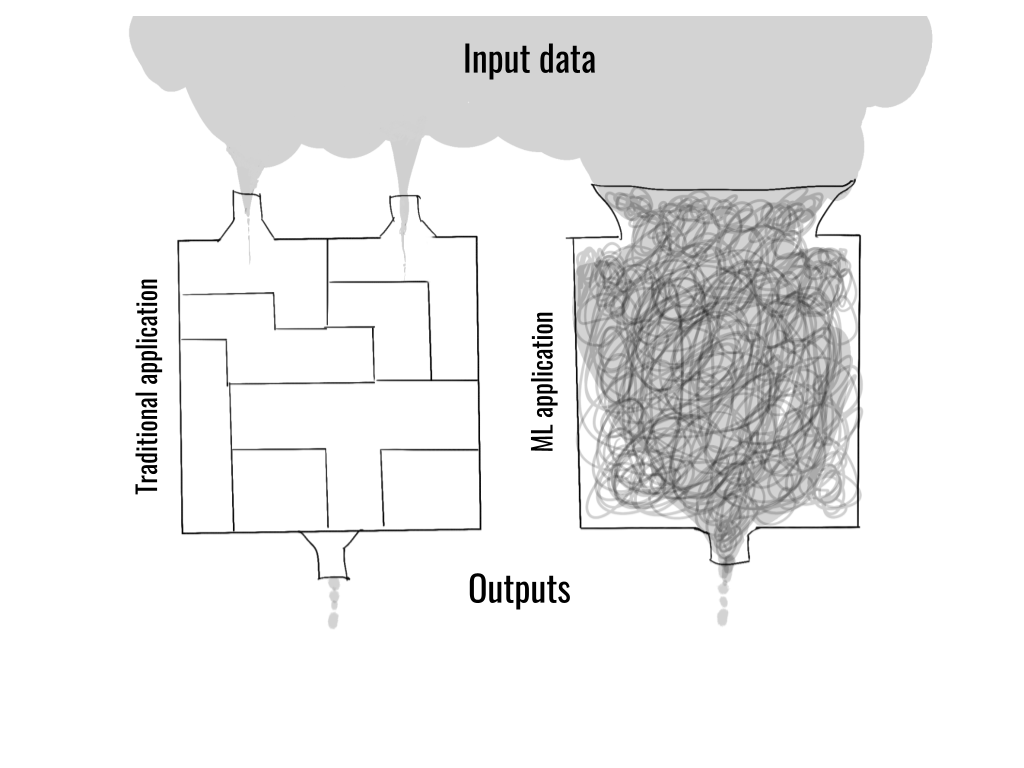
This attribute makes ML functions essentially totally different from conventional software program. It has far-reaching implications as to how such functions must be developed and by whom:
- ML functions are instantly uncovered to the continually altering actual world via information, whereas conventional software program operates in a simplified, static, summary world which is instantly constructed by the developer.
- ML apps have to be developed via cycles of experimentation: as a result of fixed publicity to information, we don’t study the conduct of ML apps via logical reasoning however via empirical statement.
- The skillset and the background of individuals constructing the functions will get realigned: whereas it’s nonetheless efficient to precise functions in code, the emphasis shifts to information and experimentation—extra akin to empirical science—somewhat than conventional software program engineering.
This strategy isn’t novel. There’s a decades-long custom of data-centric programming: builders who’ve been utilizing data-centric IDEs, similar to RStudio, Matlab, Jupyter Notebooks, and even Excel to mannequin complicated real-world phenomena, ought to discover this paradigm acquainted. Nonetheless, these instruments have been somewhat insular environments: they’re nice for prototyping however missing in terms of manufacturing use.
To make ML functions production-ready from the start, builders should adhere to the identical set of requirements as all different production-grade software program. This introduces additional necessities:
- The size of operations is usually two orders of magnitude bigger than within the earlier data-centric environments. Not solely is information bigger, however fashions—deep studying fashions specifically—are a lot bigger than earlier than.
- Fashionable ML functions have to be rigorously orchestrated: with the dramatic improve within the complexity of apps, which may require dozens of interconnected steps, builders want higher software program paradigms, similar to first-class DAGs.
- We’d like strong versioning for information, fashions, code, and ideally even the interior state of functions—suppose Git on steroids to reply inevitable questions: What modified? Why did one thing break? Who did what and when? How do two iterations examine?
- The functions should be built-in to the encompassing enterprise techniques so concepts could be examined and validated in the actual world in a managed method.
Two vital developments collide in these lists. On the one hand we now have the lengthy custom of data-centric programming; however, we face the wants of contemporary, large-scale enterprise functions. Both paradigm is inadequate by itself: it will be ill-advised to counsel constructing a contemporary ML utility in Excel. Equally, it will be pointless to faux {that a} data-intensive utility resembles a run-off-the-mill microservice which could be constructed with the same old software program toolchain consisting of, say, GitHub, Docker, and Kubernetes.
We’d like a brand new path that enables the outcomes of data-centric programming, fashions and information science functions generally, to be deployed to fashionable manufacturing infrastructure, just like how DevOps practices permits conventional software program artifacts to be deployed to manufacturing repeatedly and reliably. Crucially, the brand new path is analogous however not equal to the prevailing DevOps path.
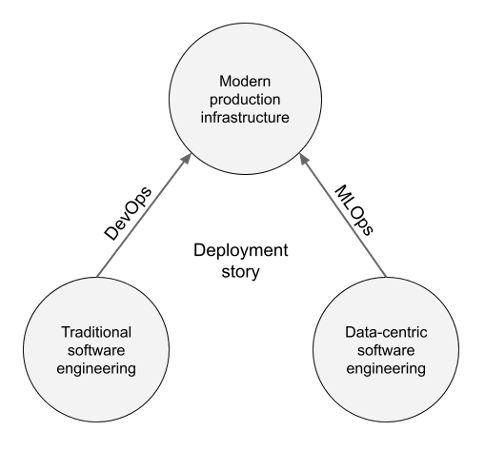
What: The Fashionable Stack of ML Infrastructure
What sort of basis would the fashionable ML utility require? It ought to mix the very best elements of contemporary manufacturing infrastructure to make sure strong deployments, in addition to draw inspiration from data-centric programming to maximise productiveness.
Whereas implementation particulars range, the most important infrastructural layers we’ve seen emerge are comparatively uniform throughout numerous initiatives. Let’s now take a tour of the varied layers, to start to map the territory. Alongside the best way, we’ll present illustrative examples. The intention behind the examples is to not be complete (maybe a idiot’s errand, anyway!), however to reference concrete tooling used at this time with the intention to floor what may in any other case be a considerably summary train.
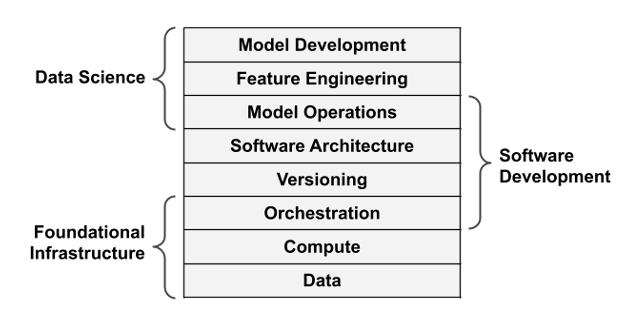
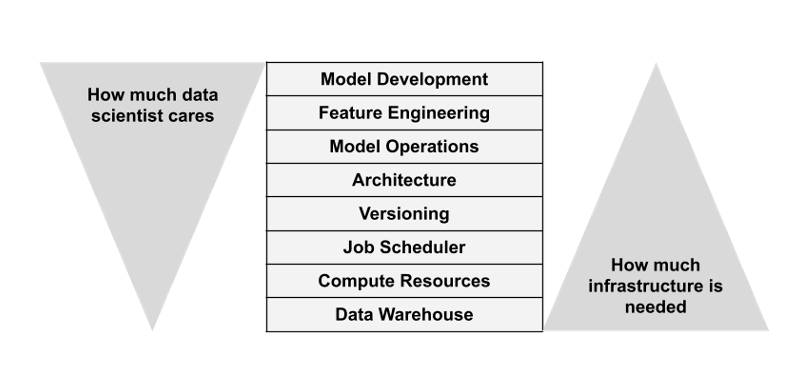
Foundational Infrastructure Layers
Information
Information is on the core of any ML challenge, so information infrastructure is a foundational concern. ML use instances not often dictate the grasp information administration answer, so the ML stack must combine with present information warehouses. Cloud-based information warehouses, similar to Snowflake, AWS’ portfolio of databases like RDS, Redshift or Aurora, or an S3-based information lake, are an awesome match to ML use instances since they are usually far more scalable than conventional databases, each when it comes to the info set sizes in addition to question patterns.
Compute
To make information helpful, we should be capable to conduct large-scale compute simply. For the reason that wants of data-intensive functions are various, it’s helpful to have a general-purpose compute layer that may deal with various kinds of duties from IO-heavy information processing to coaching giant fashions on GPUs. Apart from selection, the variety of duties could be excessive too: think about a single workflow that trains a separate mannequin for 200 nations on the earth, working a hyperparameter search over 100 parameters for every mannequin—the workflow yields 20,000 parallel duties.
Previous to the cloud, establishing and working a cluster that may deal with workloads like this is able to have been a serious technical problem. Right this moment, various cloud-based, auto-scaling techniques are simply accessible, similar to AWS Batch. Kubernetes, a preferred alternative for general-purpose container orchestration, could be configured to work as a scalable batch compute layer, though the draw back of its flexibility is elevated complexity. Be aware that container orchestration for the compute layer is to not be confused with the workflow orchestration layer, which we are going to cowl subsequent.
Orchestration
The character of computation is structured: we should be capable to handle the complexity of functions by structuring them, for instance, as a graph or a workflow that’s orchestrated.
The workflow orchestrator must carry out a seemingly easy activity: given a workflow or DAG definition, execute the duties outlined by the graph so as utilizing the compute layer. There are numerous techniques that may carry out this activity for small DAGs on a single server. Nonetheless, because the workflow orchestrator performs a key function in making certain that manufacturing workflows execute reliably, it is sensible to make use of a system that’s each scalable and extremely accessible, which leaves us with just a few battle-hardened choices, as an example: Airflow, a preferred open-source workflow orchestrator; Argo, a more moderen orchestrator that runs natively on Kubernetes, and managed options similar to Google Cloud Composer and AWS Step Features.
Software program Improvement Layers
Whereas these three foundational layers, information, compute, and orchestration, are technically all we have to execute ML functions at arbitrary scale, constructing and working ML functions instantly on high of those elements could be like hacking software program in meeting language: technically attainable however inconvenient and unproductive. To make folks productive, we want increased ranges of abstraction. Enter the software program improvement layers.
Versioning
ML app and software program artifacts exist and evolve in a dynamic surroundings. To handle the dynamism, we are able to resort to taking snapshots that signify immutable deadlines: of fashions, of information, of code, and of inside state. For that reason, we require a powerful versioning layer.
Whereas Git, GitHub, and different related instruments for software program model management work nicely for code and the same old workflows of software program improvement, they’re a bit clunky for monitoring all experiments, fashions, and information. To plug this hole, frameworks like Metaflow or MLFlow present a customized answer for versioning.
Software program Structure
Subsequent, we have to take into account who builds these functions and the way. They’re typically constructed by information scientists who should not software program engineers or pc science majors by coaching. Arguably, high-level programming languages like Python are essentially the most expressive and environment friendly ways in which humankind has conceived to formally outline complicated processes. It’s onerous to think about a greater approach to categorical non-trivial enterprise logic and convert mathematical ideas into an executable kind.
Nonetheless, not all Python code is equal. Python written in Jupyter notebooks following the custom of data-centric programming may be very totally different from Python used to implement a scalable net server. To make the info scientists maximally productive, we need to present supporting software program structure when it comes to APIs and libraries that permit them to concentrate on information, not on the machines.
Information Science Layers
With these 5 layers, we are able to current a extremely productive, data-centric software program interface that permits iterative improvement of large-scale data-intensive functions. Nonetheless, none of those layers assist with modeling and optimization. We can’t count on information scientists to put in writing modeling frameworks like PyTorch or optimizers like Adam from scratch! Moreover, there are steps which might be wanted to go from uncooked information to options required by fashions.
Mannequin Operations
In terms of information science and modeling, we separate three issues, ranging from essentially the most sensible progressing in direction of essentially the most theoretical. Assuming you’ve a mannequin, how will you use it successfully? Maybe you need to produce predictions in real-time or as a batch course of. It doesn’t matter what you do, you need to monitor the standard of the outcomes. Altogether, we are able to group these sensible issues within the mannequin operations layer. There are a lot of new instruments on this area serving to with varied features of operations, together with Seldon for mannequin deployments, Weights and Biases for mannequin monitoring, and TruEra for mannequin explainability.
Characteristic Engineering
Earlier than you’ve a mannequin, you must resolve the right way to feed it with labelled information. Managing the method of changing uncooked information to options is a deep matter of its personal, probably involving function encoders, function shops, and so forth. Producing labels is one other, equally deep matter. You need to rigorously handle consistency of information between coaching and predictions, in addition to ensure that there’s no leakage of knowledge when fashions are being educated and examined with historic information. We bucket these questions within the function engineering layer. There’s an rising area of ML-focused function shops similar to Tecton or labeling options like Scale and Snorkel. Characteristic shops purpose to resolve the problem that many information scientists in a company require related information transformations and options for his or her work and labeling options take care of the very actual challenges related to hand labeling datasets.
Mannequin Improvement
Lastly, on the very high of the stack we get to the query of mathematical modeling: What sort of modeling approach to make use of? What mannequin structure is most fitted for the duty? How you can parameterize the mannequin? Luckily, glorious off-the-shelf libraries like scikit-learn and PyTorch can be found to assist with mannequin improvement.
An Overarching Concern: Correctness and Testing
Whatever the techniques we use at every layer of the stack, we need to assure the correctness of outcomes. In conventional software program engineering we are able to do that by writing assessments: as an example, a unit take a look at can be utilized to test the conduct of a perform with predetermined inputs. Since we all know precisely how the perform is carried out, we are able to persuade ourselves via inductive reasoning that the perform ought to work accurately, based mostly on the correctness of a unit take a look at.
This course of doesn’t work when the perform, similar to a mannequin, is opaque to us. We should resort to black field testing—testing the conduct of the perform with a variety of inputs. Even worse, subtle ML functions can take an enormous variety of contextual information factors as inputs, just like the time of day, consumer’s previous conduct, or system kind into consideration, so an correct take a look at arrange might must change into a full-fledged simulator.
Since constructing an correct simulator is a extremely non-trivial problem in itself, typically it’s simpler to make use of a slice of the real-world as a simulator and A/B take a look at the applying in manufacturing in opposition to a recognized baseline. To make A/B testing attainable, all layers of the stack must be be capable to run many variations of the applying concurrently, so an arbitrary variety of production-like deployments could be run concurrently. This poses a problem to many infrastructure instruments of at this time, which have been designed for extra inflexible conventional software program in thoughts. Apart from infrastructure, efficient A/B testing requires a management airplane, a contemporary experimentation platform, similar to StatSig.
How: Wrapping The Stack For Most Usability
Think about selecting a production-grade answer for every layer of the stack: as an example, Snowflake for information, Kubernetes for compute (container orchestration), and Argo for workflow orchestration. Whereas every system does a very good job at its personal area, it isn’t trivial to construct a data-intensive utility that has cross-cutting issues touching all of the foundational layers. As well as, you must layer the higher-level issues from versioning to mannequin improvement on high of the already complicated stack. It isn’t sensible to ask an information scientist to prototype shortly and deploy to manufacturing with confidence utilizing such a contraption. Including extra YAML to cowl cracks within the stack isn’t an sufficient answer.
Many data-centric environments of the earlier era, similar to Excel and RStudio, actually shine at maximizing usability and developer productiveness. Optimally, we may wrap the production-grade infrastructure stack inside a developer-oriented consumer interface. Such an interface ought to permit the info scientist to concentrate on issues which might be most related for them, particularly the topmost layers of stack, whereas abstracting away the foundational layers.
The mix of a production-grade core and a user-friendly shell makes positive that ML functions could be prototyped quickly, deployed to manufacturing, and introduced again to the prototyping surroundings for steady enchancment. The iteration cycles must be measured in hours or days, not in months.
Over the previous 5 years, various such frameworks have began to emerge, each as business choices in addition to in open-source.
Metaflow is an open-source framework, initially developed at Netflix, particularly designed to handle this concern (disclaimer: one of many authors works on Metaflow): How can we wrap strong manufacturing infrastructure in a single coherent, easy-to-use interface for information scientists? Below the hood, Metaflow integrates with best-of-the-breed manufacturing infrastructure, similar to Kubernetes and AWS Step Features, whereas offering a improvement expertise that pulls inspiration from data-centric programming, that’s, by treating native prototyping because the first-class citizen.
Google’s open-source Kubeflow addresses related issues, though with a extra engineer-oriented strategy. As a business product, Databricks supplies a managed surroundings that mixes data-centric notebooks with a proprietary manufacturing infrastructure. All cloud suppliers present business options as nicely, similar to AWS Sagemaker or Azure ML Studio.
Whereas these options, and lots of much less recognized ones, appear related on the floor, there are a lot of variations between them. When evaluating options, take into account specializing in the three key dimensions lined on this article:
- Does the answer present a pleasant consumer expertise for information scientists and ML engineers? There isn’t a basic motive why information scientists ought to settle for a worse stage of productiveness than is achievable with present data-centric instruments.
- Does the answer present first-class help for fast iterative improvement and frictionless A/B testing? It must be straightforward to take initiatives shortly from prototype to manufacturing and again, so manufacturing points could be reproduced and debugged domestically.
- Does the answer combine together with your present infrastructure, specifically to the foundational information, compute, and orchestration layers? It isn’t productive to function ML as an island. In terms of working ML in manufacturing, it’s useful to have the ability to leverage present manufacturing tooling for observability and deployments, for instance, as a lot as attainable.
It’s secure to say that each one present options nonetheless have room for enchancment. But it appears inevitable that over the following 5 years the entire stack will mature, and the consumer expertise will converge in direction of and finally past the very best data-centric IDEs. Companies will discover ways to create worth with ML just like conventional software program engineering and empirical, data-driven improvement will take its place amongst different ubiquitous software program improvement paradigms.
[ad_2]