
{kind=link}
[ad_1]
Information overload is a major problem for a lot of organizations and people at the moment. It might be overwhelming to maintain up with incoming chat messages and paperwork that arrive at our inbox on a regular basis. This has been exacerbated by the rise in digital work and stays a problem as many groups transition to a hybrid work setting with a mixture of these working each nearly and in an workplace. One resolution that may tackle data overload is summarization — for instance, to assist customers enhance their productiveness and higher handle a lot data, we not too long ago launched auto-generated summaries in Google Docs.
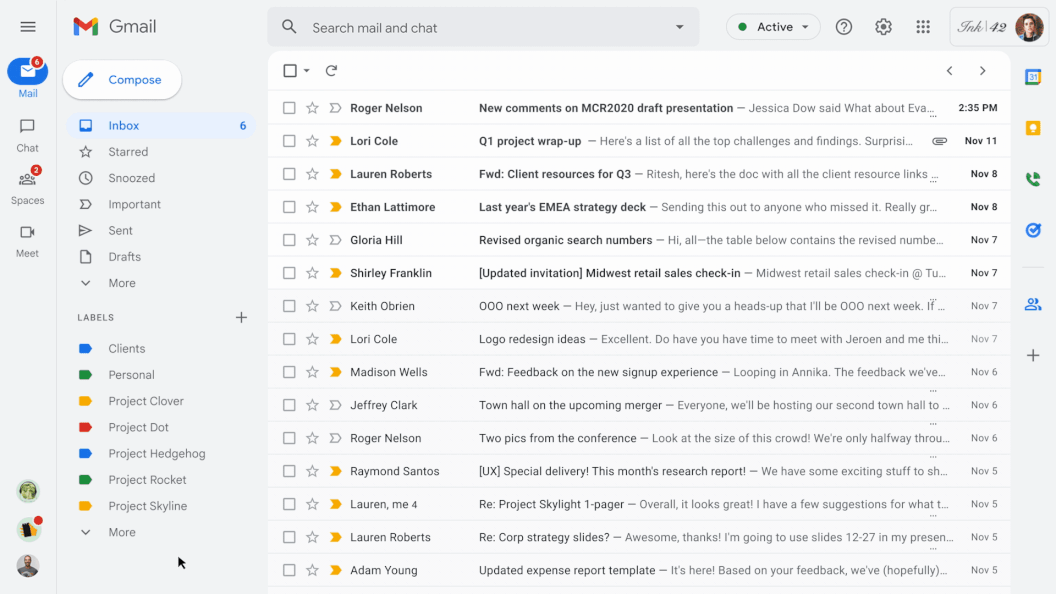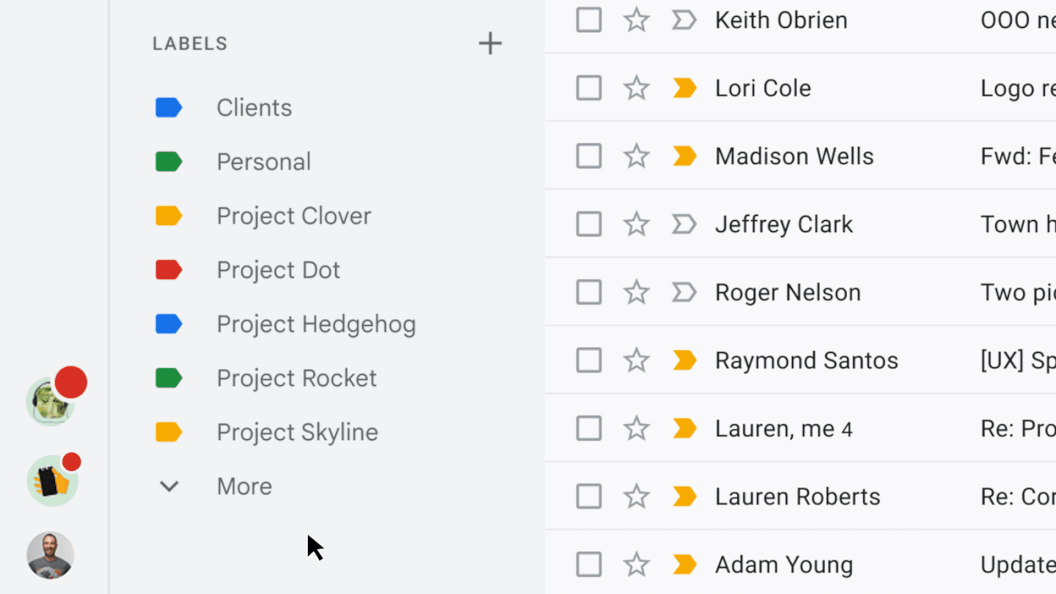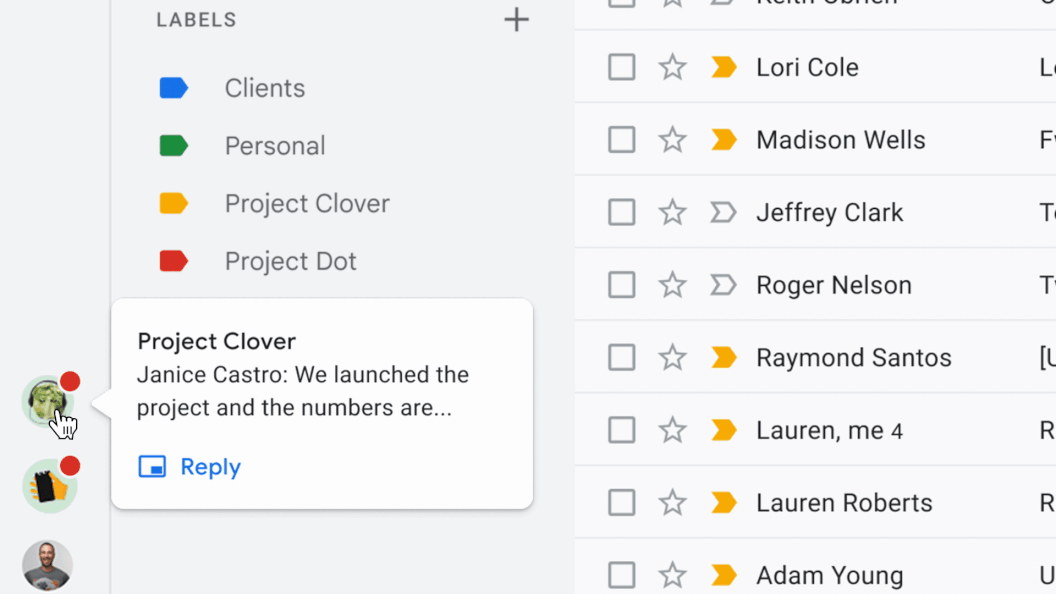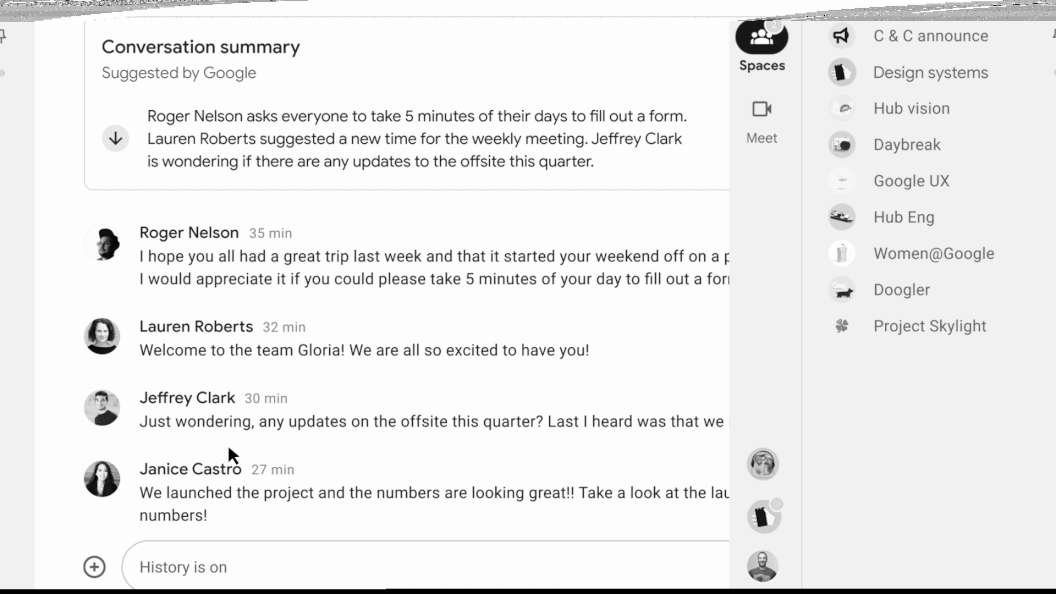
Today, we’re excited to introduce dialog summaries in Google Chat for messages in Spaces. When these summaries can be found, a card with robotically generated summaries is proven as customers enter Spaces with unread messages. The card features a listing of summaries for the totally different matters mentioned in Spaces. This characteristic is enabled by our state-of-the-art abstractive summarization mannequin, Pegasus, which generates helpful and concise summaries for chat conversations, and is at the moment out there to chose premium Google Workspace enterprise clients.
 |
| Conversation summaries present a useful digest of conversations in Spaces, permitting customers to shortly catch-up on unread messages and navigate to probably the most related threads. |
Conversation Summarization Modeling
The objective of textual content summarization is to offer useful and concise summaries for various kinds of textual content, comparable to paperwork, articles, or spoken conversations. A great abstract covers the important thing factors succinctly, and is fluent and grammatically appropriate. One method to summarization is to extract key elements from the textual content and concatenate them collectively right into a abstract (i.e., extractive summarization). Another method is to make use of pure language era (NLG) methods to summarize utilizing novel phrases and phrases not essentially current within the authentic textual content. This is known as abstractive summarization and is taken into account nearer to how an individual would usually summarize textual content. A important problem with abstractive summarization, nevertheless, is that it generally struggles to generate correct and grammatically appropriate summaries, particularly in actual world purposes.
ForumSum Dataset
The majority of abstractive summarization datasets and analysis focuses on single-speaker textual content paperwork, like information and scientific articles, primarily as a result of abundance of human-written summaries for such paperwork. On the opposite hand, datasets of human-written summaries for different sorts of textual content, like chat or multi-speaker conversations, are very restricted.
To tackle this we created ForumSum, a various and high-quality dialog summarization dataset with human-written summaries. The conversations within the dataset are collected from all kinds of public web boards, and are cleaned up and filtered to make sure top quality and secure content material (extra particulars within the paper).
 |
| An instance from the ForumSum dataset. |
Each utterance within the dialog begins on a brand new line, comprises an creator identify and a message textual content that’s separated with a colon. Human annotators are then given detailed directions to jot down a 1-3 sentence abstract of the dialog. These directions went by a number of iterations to make sure annotators wrote top quality summaries. We have collected summaries for over six thousand conversations, with a median of greater than 6 audio system and 10 utterances per dialog. ForumSum supplies high quality coaching knowledge for the dialog summarization downside: it has quite a lot of matters, variety of audio system, and variety of utterances generally encountered in a chat software.
Conversation Summarization Model Design
As we have now written beforehand, the Transformer is a well-liked mannequin structure for sequence-to-sequence duties, like abstractive summarization, the place the inputs are the doc phrases and the outputs are the abstract phrases. Pegasus mixed transformers with self-supervised pre-training custom-made for abstractive summarization, making it an awesome mannequin selection for dialog summarization. First, we fine-tune Pegasus on the ForumSum dataset the place the enter is the dialog phrases and the output is the abstract phrases. Second, we use data distillation to distill the Pegasus mannequin right into a hybrid structure of a transformer encoder and a recurrent neural community (RNN) decoder. The ensuing mannequin has decrease latency and reminiscence footprint whereas sustaining comparable high quality because the Pegasus mannequin.
Quality and User Experience
A great abstract captures the essence of the dialog whereas being fluent and grammatically appropriate. Based on human analysis and consumer suggestions, we discovered that the summarization mannequin generates helpful and correct summaries more often than not. But often the mannequin generates low high quality summaries. After trying into points reported by customers, we discovered that there are two important sorts of low high quality summaries. The first one is misattribution, when the mannequin confuses which particular person or entity stated or carried out a sure motion. The second one is misrepresentation, when the mannequin’s generated abstract misrepresents or contradicts the chat dialog.
To tackle low high quality summaries and enhance the consumer expertise, we have now made progress in a number of areas:
- Improving ForumSum: While ForumSum supplies a very good illustration of chat conversations, we observed sure patterns and language types in Google Chat conversations that differ from ForumSum, e.g., how customers point out different customers and the usage of abbreviations and particular symbols. After exploring examples reported by customers, we concluded that these out-of-distribution language patterns contributed to low high quality summaries. To tackle this, we first carried out knowledge formatting and clean-ups to scale back mismatches between chat and ForumSum conversations at any time when doable. Second, we added extra coaching knowledge to ForumSum to raised symbolize these model mismatches. Collectively, these modifications resulted in discount of low high quality summaries.
- Controlled triggering: To ensure that summaries deliver probably the most worth to our customers, we first have to ensure that the chat dialog is worthy of summarization. For instance, we discovered that there’s much less worth in producing a abstract when the consumer is actively engaged in a dialog and doesn’t have many unread messages, or when the dialog is just too brief.
- Detecting low high quality summaries: While the 2 strategies above restricted low high quality and low worth summaries, we nonetheless developed strategies to detect and abstain from displaying such summaries to the consumer when they’re generated. These are a set of heuristics and fashions to measure the general high quality of summaries and whether or not they undergo from misattribution or misrepresentation points.
Finally, whereas the hybrid mannequin offered vital efficiency enhancements, the latency to generate summaries was nonetheless noticeable to customers once they opened Spaces with unread messages. To tackle this challenge, we as a substitute generate and replace summaries at any time when there’s a new message despatched, edited or deleted. Then summaries are cached ephemerally to make sure they floor easily when customers open Spaces with unread messages.
Conclusion and Future Work
We are excited to use state-of-the-art abstractive summarization fashions to assist our Workspace customers enhance their productiveness in Spaces. While that is nice progress, we consider there are numerous alternatives to additional enhance the expertise and the general high quality of summaries. Future instructions we’re exploring embrace higher modeling and summarizing entangled conversations that embrace a number of matters, and growing metrics that higher measure the factual consistency between chat conversations and summaries.
Acknowledgements
The authors wish to thank the many individuals throughout Google that contributed to this work: Ahmed Chowdhury, Alejandro Elizondo, Anmol Tukrel, Benjamin Lee, Cameron Oelsen, Chao Wang, Chris Carroll, Don Kim, Hun Jung, Jackie Tsay, Jennifer Chou, Jesse Sliter, John Sipple, Jonathan Herzig, Kate Montgomery, Maalika Manoharan, Mahdis Mahdieh, Mia Chen, Misha Khalman, Peter Liu, Robert Diersing, Roee Aharoni, Sarah Read, Winnie Yeung, Yao Zhao, and Yonghui Wu.
[ad_2]