
{kind=link}
[ad_1]
Flash permits speedy detection of points originating from the Azure platform, serving to groups reply rapidly to infrastructure-related disruptions.
Previously, we shared an replace on Project Flash as a part of our Advancing Reliability weblog collection, reaffirming our dedication to serving to Azure clients detect and diagnose digital machine (VM) availability points with velocity and precision. This 12 months, we’re excited to unveil the most recent improvements that take VM availability monitoring to the following degree—enabling clients to function their workloads on Azure with even larger confidence. I’ve requested Yingqi (Halley) Ding, Technical Program Manager from the Azure Core Compute crew, to stroll us by way of the latest investments powering the following section of Project Flash.
— Mark Russinovich, CTO, Deputy CISO, and Technical Fellow, Microsoft Azure.
Project Flash is a cross-division initiative at Microsoft. Its imaginative and prescient is to ship exact telemetry, real-time alerts, and scalable monitoring—all inside a unified, user-friendly expertise designed to fulfill the various observability wants of digital machine (VM) availability.
Flash addresses each platform-level and user-level challenges. It permits speedy detection of points originating from the Azure platform, serving to groups reply rapidly to infrastructure-related disruptions. At the identical time, it equips you with actionable insights to diagnose and resolve issues inside your individual setting. This twin functionality helps excessive availability and helps guarantee what you are promoting Service-Level Agreements are persistently met. It’s our mission to make sure you can:
- Gain clear visibility into disruptions, similar to VM reboots and restarts, utility freezes attributable to community driver updates, and 30-second host OS updates—with detailed insights into what occurred, why it occurred, and whether or not it was deliberate or surprising.
- Analyze developments and set alerts to hurry up debugging and observe availability over time.
- Monitor at scale and construct customized dashboards to remain on high of the well being of all sources.
- Receive automated root trigger analyses (RCAs) that designate which VMs had been affected, what brought about the problem, how lengthy it lasted, and what was achieved to repair it.
- Receive real-time notifications for vital occasions, similar to degraded nodes requiring VM redeployment, platform-initiated service therapeutic, or in-place reboots triggered by {hardware} points—empowering your groups to reply swiftly and reduce person affect.
- Adapt restoration insurance policies dynamically to fulfill altering workload wants and enterprise priorities.
During our crew’s journey with Flash, it has garnered widespread adoption from a number of the world’s main corporations spanning from e-commerce, gaming, finance, hedge funds, and plenty of different sectors. Their intensive utilization of Flash underscores its effectiveness and worth in assembly the various wants of high-profile organizations.
At BlackRock, VM reliability is vital to our operations. If a VM is operating on degraded {hardware}, we need to be alerted rapidly so now we have the utmost alternative to mitigate the problem earlier than it impacts customers. With Project Flash, we obtain a useful resource well being occasion built-in into our alerting processes the second an underlying node in Azure infrastructure is marked unallocatable, usually attributable to well being degradation. Our infrastructure crew then schedules a migration of the affected useful resource to wholesome {hardware} at an optimum time. This potential to predictively keep away from abrupt VM failures has lowered our VM interruption charge and improved the general reliability of our funding platform.
— Eli Hamburger, Head of Infrastructure Hosting, BlackRock.
Suite of options obtainable immediately
The Flash initiative has advanced into a sturdy, scalable monitoring framework designed to fulfill the various wants of contemporary infrastructure—whether or not you’re managing a handful of VMs or working at huge scale. Built with reliability at its core, Flash empowers you to watch what issues most, utilizing the instruments and telemetry that align together with your structure and operational mannequin.
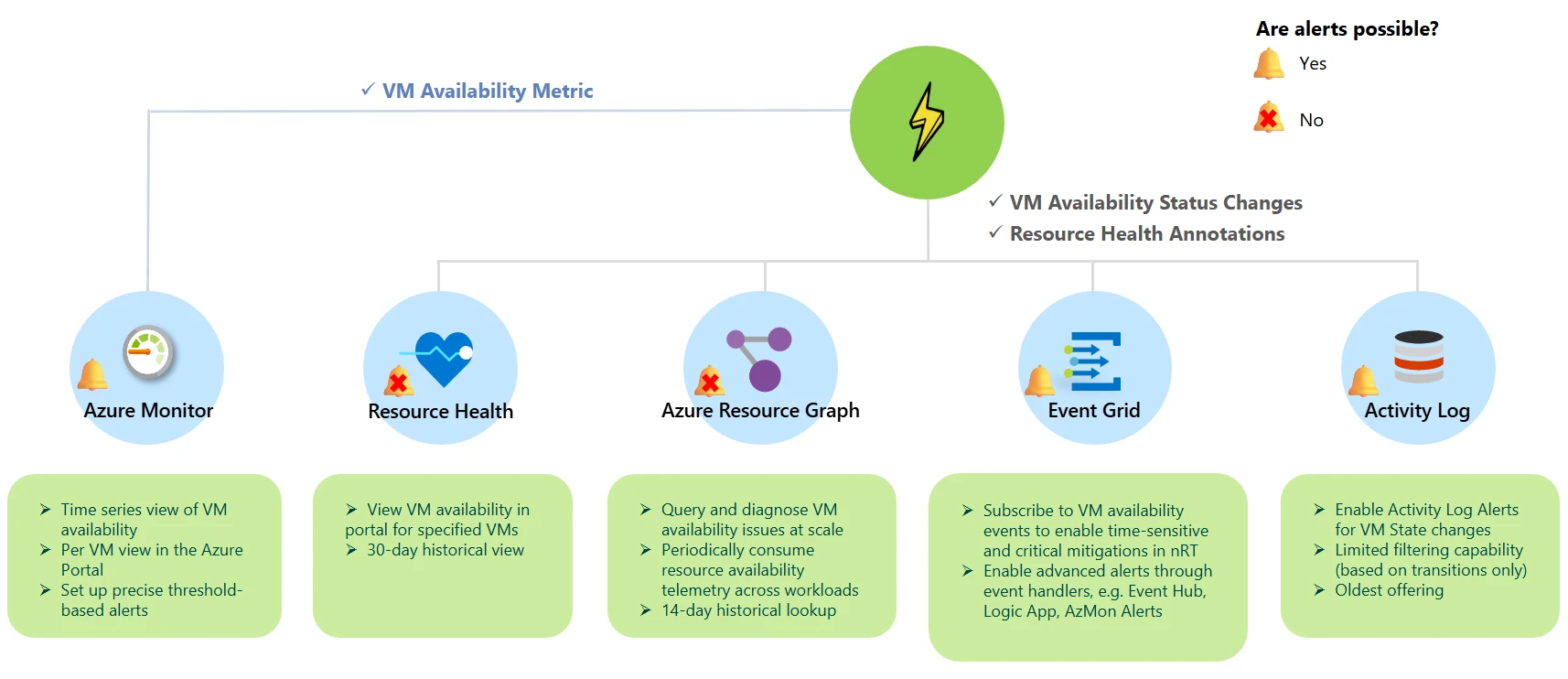
Flash publishes VM availability states and useful resource well being annotations for detailed failure attribution and downtime evaluation. The information under outlines your choices so you may select the fitting Flash monitoring resolution on your situation.
| Solution | Description |
| Azure Resource Graph (common availability) | For investigations at scale, centralized useful resource repositories, and historic lookups, you may periodically devour useful resource availability telemetry throughout all workloads directly utilizing Azure Resource Graph (ARG). |
| Event Grid system matter (public preview) | To set off time-sensitive and demanding mitigations, similar to redeploying or restarting VMs to forestall end-user affect, you may obtain alerts inside seconds of vital modifications in useful resource availability by way of Event Handlers in Event Grid. |
| Azure Monitor – Metrics (public preview) | To observe developments, combination platform metrics (e.g., CPU, disk), and configure exact threshold-based alerts, you may devour an out-of-the-box VM availability metric by way of Azure Monitor. |
| Resource Health (common availability) | To carry out instantaneous and handy per-resource well being checks within the Portal UI, you may rapidly view the RHC blade. You also can entry a 30-day historic view of well being checks for that useful resource to assist quick and efficient troubleshooting. |
What’s new?
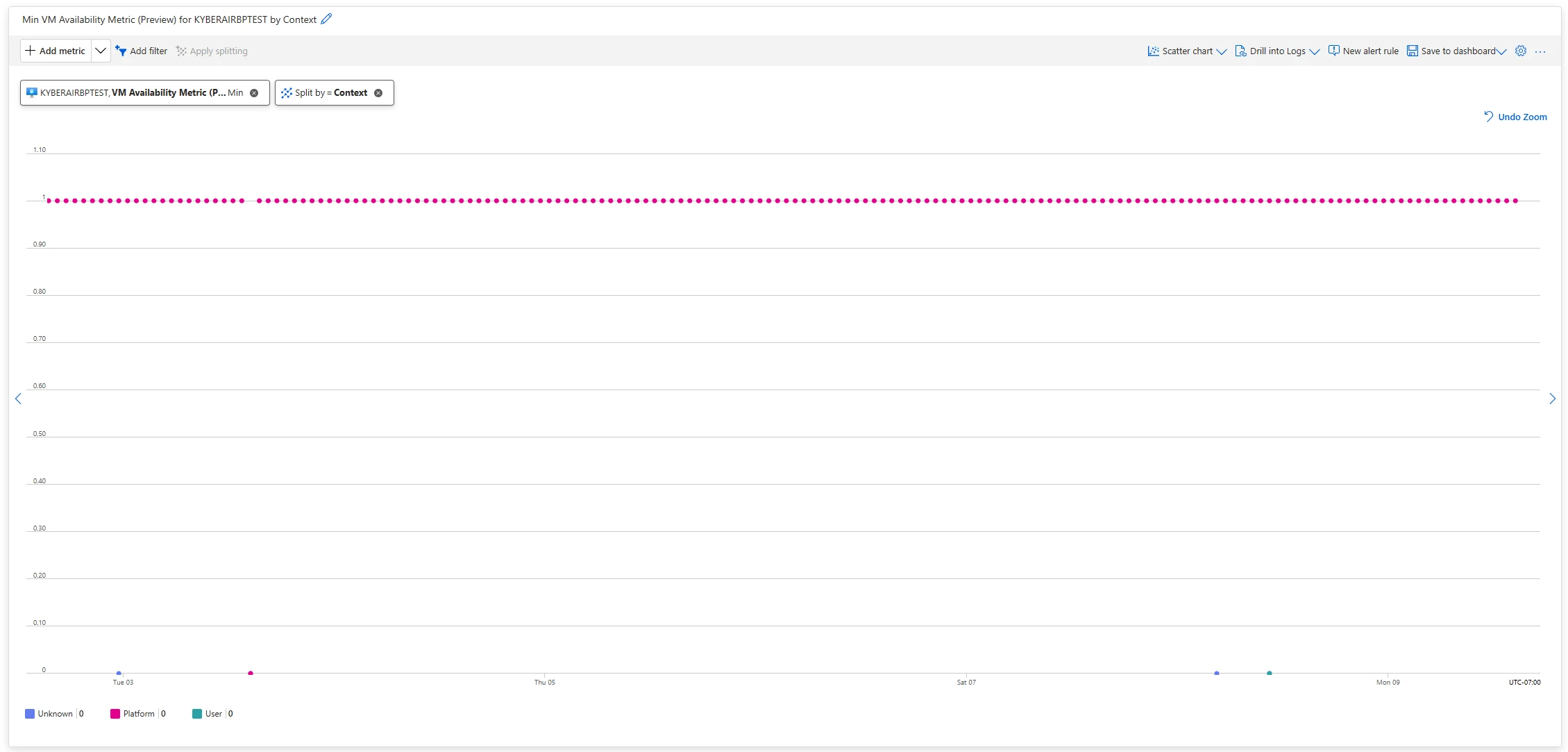
Public preview: User vs platform dimension launched for VM availability metric
Many clients have emphasised the necessity for user-friendly monitoring options that present real-time, scalable entry to compute useful resource availability knowledge. This info is important for triggering well timed mitigation actions in response to availability modifications.
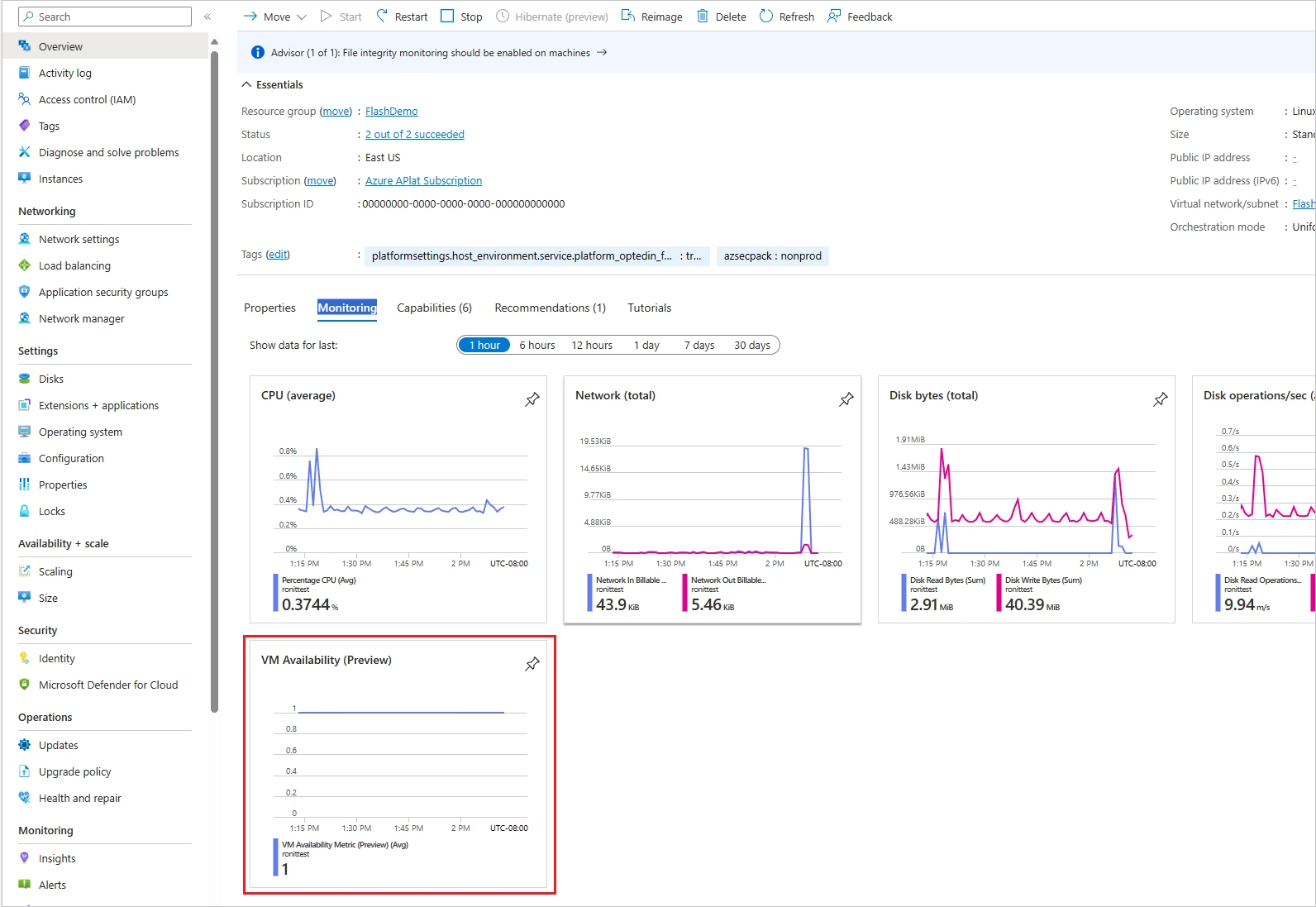
Designed to fulfill this vital want, the VM availability metric is well-suited for monitoring developments, aggregating platform metrics (similar to CPU and disk utilization), and configuring exact threshold-based alerts. You can make the most of this out-of-the-box VM availability metric in Azure Monitor.
Now you should use the Context dimension to determine whether or not VM availability was influenced by Azure or user-orchestrated exercise. This dimension signifies, throughout any disruption or when the metric drops to zero, whether or not the trigger was platform-triggered or user-driven. It can assume values of Platform, Customer, or Unknown.
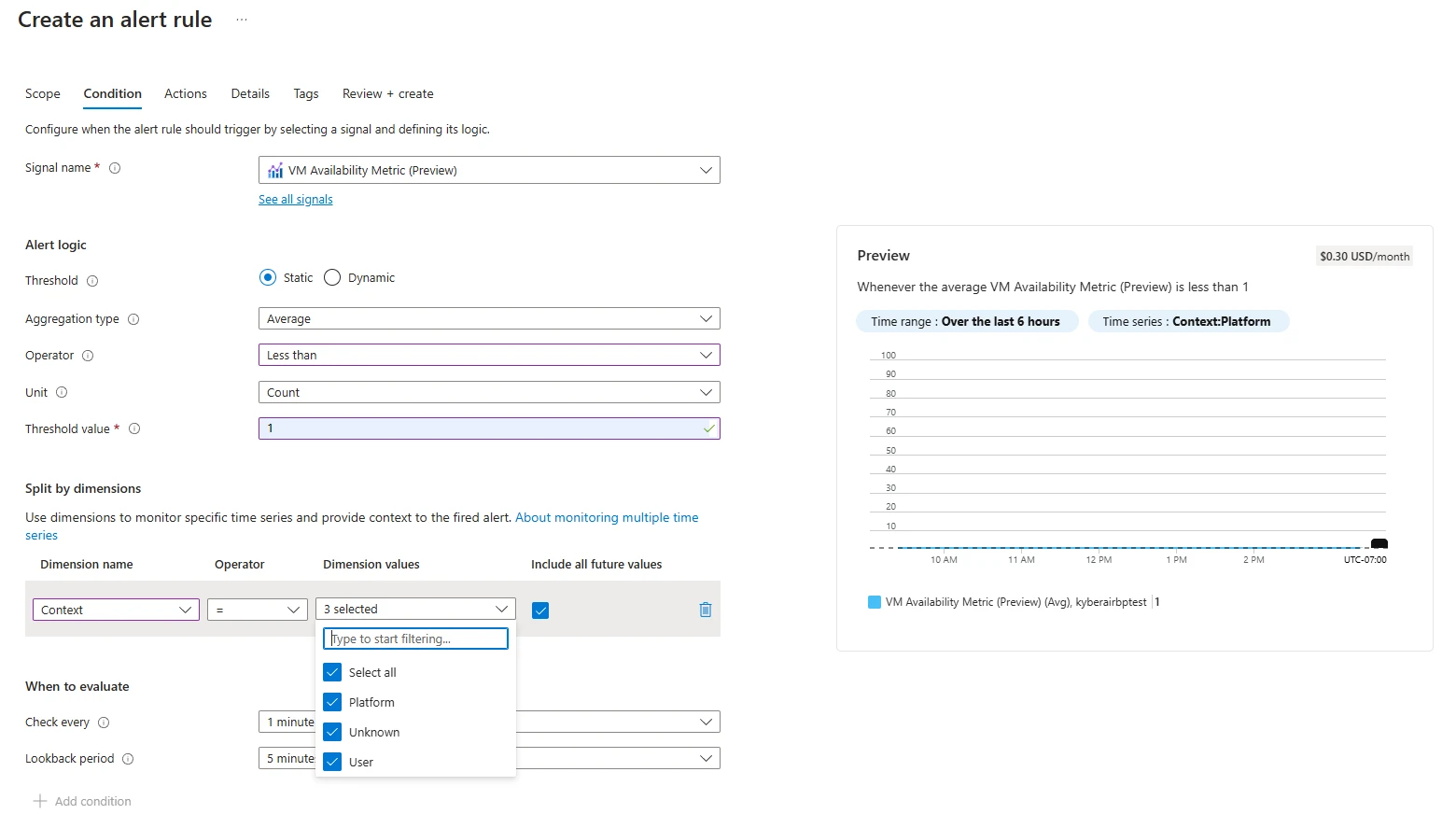
The new dimension can also be supported in Azure Monitor alert guidelines as a part of the filtering course of.
Public preview: Enable sending well being sources occasions to Azure Monitor alerts in Event Grid
Azure Event Grid is a extremely scalable, absolutely managed Pub/Sub message distribution service that gives versatile message consumption patterns. Event Grid lets you publish and subscribe to messages to assist Internet of Things (IoT) options. Through HTTP, Event Grid lets you construct event-driven options, the place a writer service (similar to Project Flash) declares its system state modifications (occasions) to subscriber purposes.
With the mixing of Azure Monitor alerts as a brand new occasion handler, now you can obtain low-latency notifications—similar to VM availability modifications and detailed annotations—by way of SMS, e mail, push notifications, and extra. This combines Event Grid’s close to real-time supply with Azure Monitor’s direct alerting capabilities.
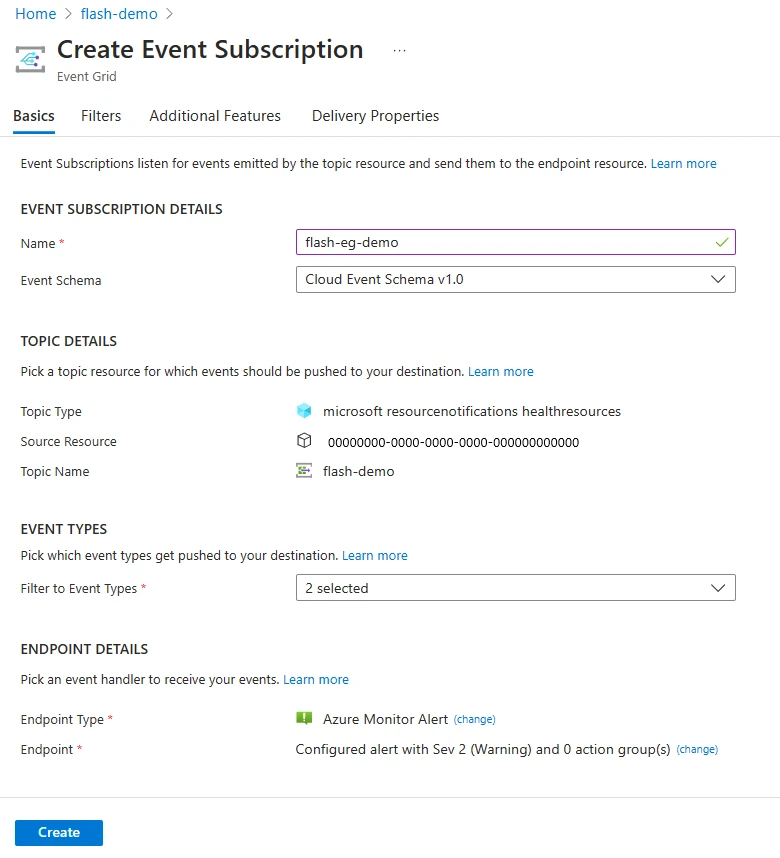
To get began, merely observe the step-by-step directions and start receiving real-time alerts with Flash’s new providing.
What’s subsequent?
Looking forward, we plan to broaden our focus to incorporate situations similar to inoperable top-of-rack switches, failures in accelerated networking, and new courses of {hardware} failure prediction. In addition, we goal to proceed enhancing knowledge high quality and consistency throughout all Flash endpoints—enabling extra correct downtime attribution and deeper visibility into VM availability.
For complete monitoring of VM availability—together with situations similar to routine upkeep, stay migration, service therapeutic, and degradation—we suggest leveraging each Flash Health occasions and Scheduled Events (SE).
- Flash Health occasions provide real-time insights into ongoing and historic availability disruptions, together with VM degradation. This facilitates efficient downtime administration, helps automated mitigation methods, and enhances root trigger evaluation.
- Scheduled Events, in distinction, present as much as quarter-hour of advance discover previous to deliberate upkeep, enabling proactive decision-making and preparation. During this window, you could select to acknowledge the occasion or defer actions based mostly in your operational readiness.
For upcoming updates on the Flash initiative, we encourage you to observe the advancing reliability collection!
[ad_2]